transformers.js - Run 🤗 Transformers in your browser!
Transformers.js


Run
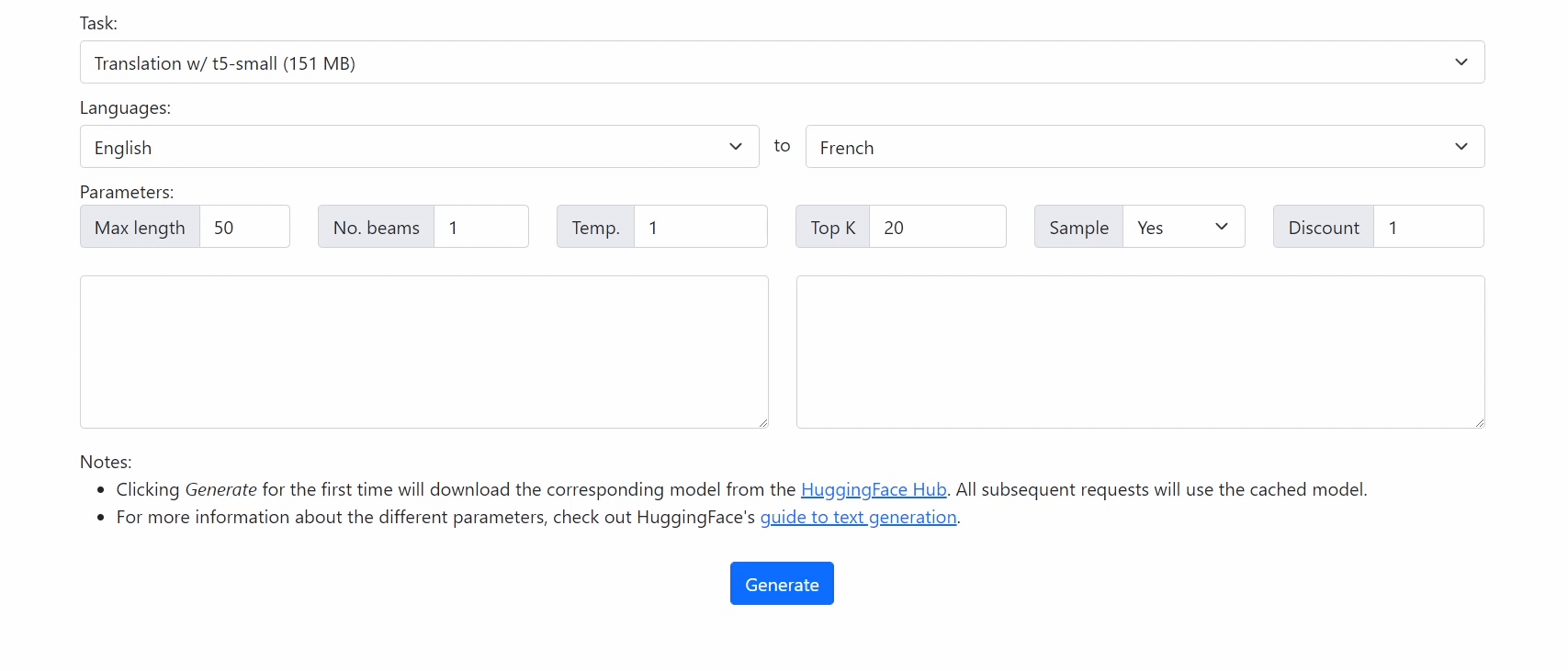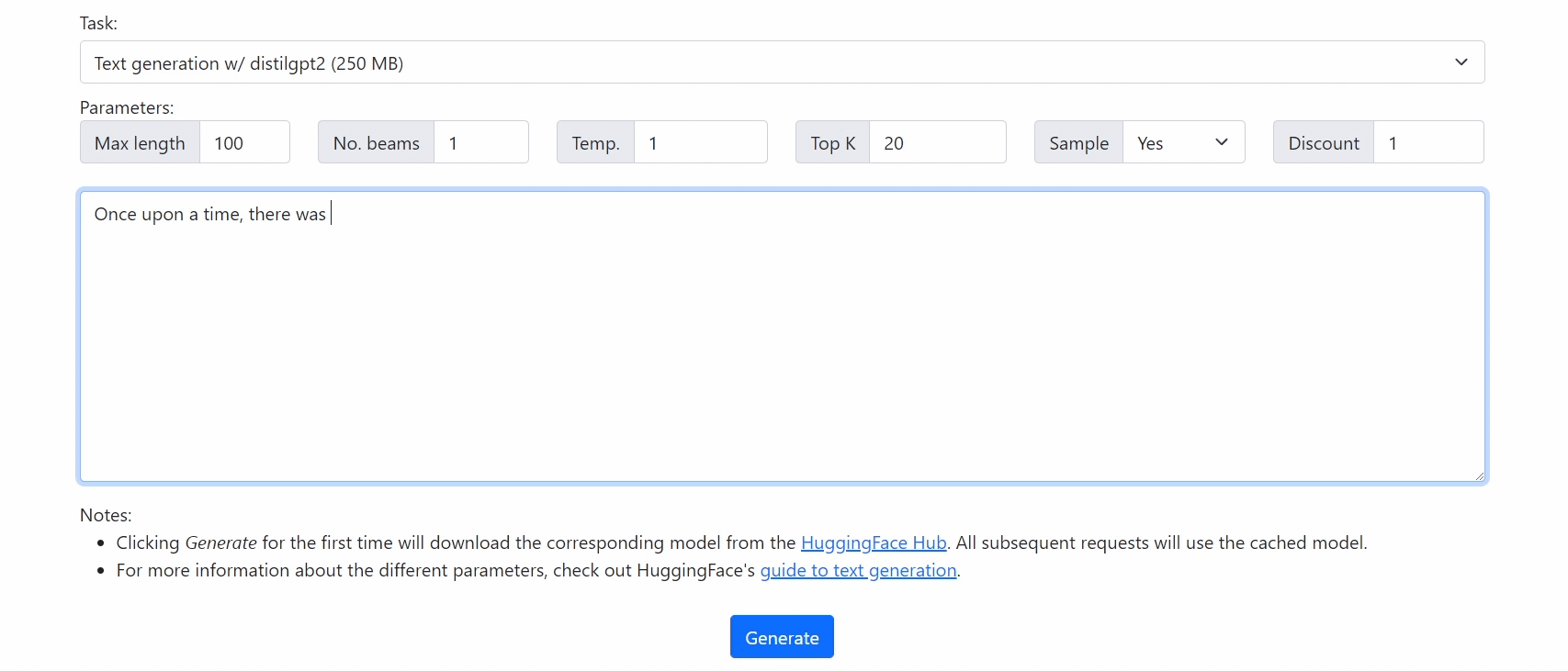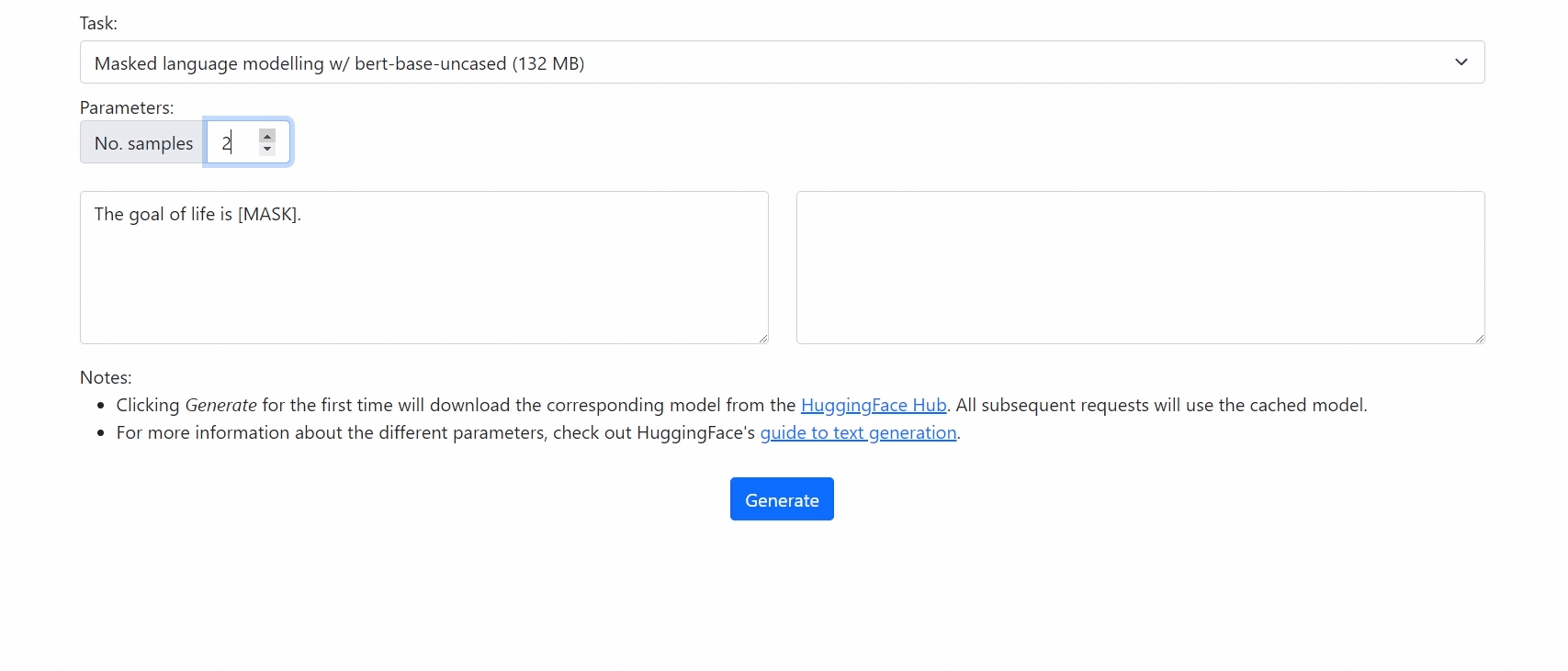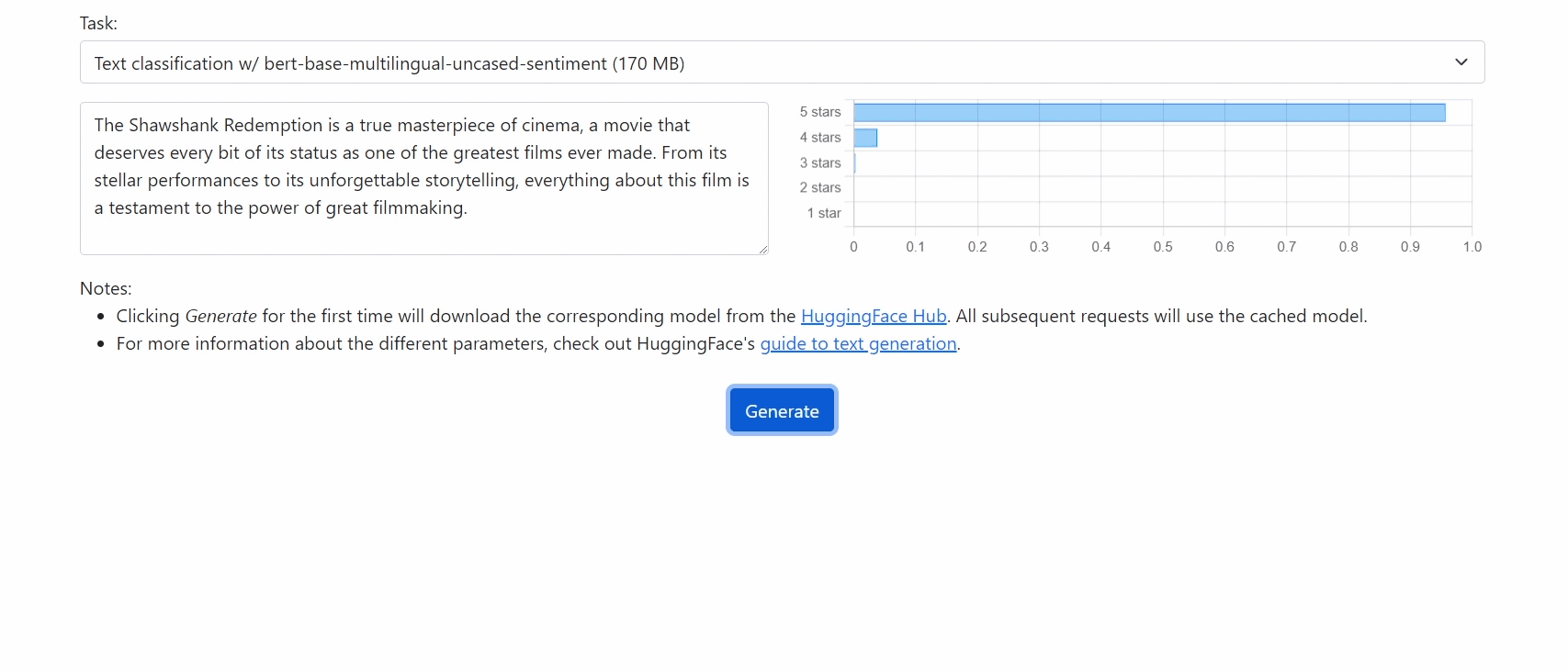
Check out our demo at https://xenova.github.io/transformers.js/. As you'll see, everything runs inside the browser!
Getting Started
Installation
If you use npm, you can install it using:
npm i @xenova/transformersAlternatively, you can use it in a <script> tag from a CDN, for example:
<!-- Using jsDelivr -->
<script src="https://cdn.jsdelivr.net/npm/@xenova/transformers/dist/transformers.min.js"></script>
<!-- or UNPKG -->
<script src="https://www.unpkg.com/@xenova/transformers/dist/transformers.min.js"></script>Basic example
It's super easy to translate from existing code!
| Python (original) | Javascript (ours) |
|---|---|
from transformers import pipeline
# Allocate a pipeline for sentiment-analysis
pipe = pipeline('sentiment-analysis')
out = pipe('I love transformers!')
# [{'label': 'POSITIVE', 'score': 0.999806941}] |
import { pipeline } from "@xenova/transformers";
// Allocate a pipeline for sentiment-analysis
let pipe = await pipeline('sentiment-analysis');
let out = await pipe('I love transformers!');
// [{'label': 'POSITIVE', 'score': 0.999817686}] |
In the same way as the Python library, you can use a different model by providing its name as the second argument to the pipeline function. For example:
// Use a different model for sentiment-analysis
let pipe = await pipeline('sentiment-analysis', 'nlptown/bert-base-multilingual-uncased-sentiment');Custom setup
By default, Transformers.js uses hosted models and precompiled WASM binaries, which should work out-of-the-box. You can override this behaviour as follows:
import { env } from "@xenova/transformers";
// Use a different host for models.
// - `remoteURL` defaults to use the HuggingFace Hub
// - `localURL` defaults to '/models/onnx/quantized/'
env.remoteURL = 'https://www.example.com/';
env.localURL = '/path/to/models/';
// Set whether to use remote or local models. Defaults to true.
// - If true, use the path specified by `env.remoteURL`.
// - If false, use the path specified by `env.localURL`.
env.remoteModels = false;
// Set parent path of .wasm files. Defaults to use a CDN.
env.onnx.wasm.wasmPaths = '/path/to/files/';Usage
Convert your PyTorch models to ONNX
We use ONNX Runtime to run the models in the browser, so you must first convert your PyTorch model to ONNX (which can be done using our conversion script). In general, the command will look something like this:
python ./scripts/convert.py --model_id <hf_model_id> --from_hub --quantize --task <task>
For example, to use bert-base-uncased for masked language modelling, you can use the command:
python ./scripts/convert.py --model_id bert-base-uncased --from_hub --quantize --task masked-lm
If you want to use a local model, remove the --from_hub flag from above and place your PyTorch model in the ./models/pytorch/ folder. You can also choose a different location by specifying the parent input folder with --input_parent_dir /path/to/parent_dir/ (note: without the model id).
Alternatively, you can find some of the models we have already converted here. For example, to use bert-base-uncased for masked language modelling, you can use the model found at https://huggingface.co/Xenova/transformers.js/tree/main/quantized/bert-base-uncased/masked-lm.
Note: We recommend quantizing the model (--quantize) to reduce model size and improve inference speeds (at the expense of a slight decrease in accuracy). For more information, run the help command: python ./scripts/convert.py -h.
Options
Coming soon...
Examples
Coming soon... In the meantime, check out the source code for the demo here.
Credit
Inspired by https://github.com/praeclarum/transformers-js
