TTS - 🐸💬- 用于文本到语音的深度学习工具包,在研究和生产中经过实战测试
🐸Coqui.ai 新闻
- 📣 (X)TTS,我们的生产TTS模型,可以说13种语言,发布博客文章,演示,文档
- 📣 🐶Bark 现在可用于通过不受约束的语音克隆进行推理。文档
- 📣 你可以将 ~1100 Fairseq 型号与 TTS 一起使用🐸。
- 📣 🐸TTS 现在支持 🐢Tortoise 具有更快的推理速度。文档
- 📣 Coqui Studio API登陆🐸TTS。- 例 子
- 📣 Coqui Studio API 已上线。
- 📣 带有提示的语音生成 - 提示语音 - 在Coqui Studio上直播!!- 博客文章
- 📣 Voice Generation with fusion - Voice fusion - 在Coqui Studio上直播。
- 📣 语音克隆在Coqui Studio上直播。


🐸TTS 是一个用于高级文本到语音生成的库。
🚀 +1100 种语言的预训练模型。
🛠️ 用于训练新模型和微调任何语言现有模型的工具。
📚 用于数据集分析和策展的实用程序。

![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
💬 在哪里提问
请使用我们的专用渠道进行提问和讨论。如果帮助是公开共享的,以便更多的人可以从中受益,那么帮助就会更有价值。
| 类型 | 平台 |
|---|---|
| 🚨 错误报告 | GitHub 问题跟踪器 |
| 🎁 功能请求和想法 | GitHub 问题跟踪器 |
| 👩 💻 使用问题 | GitHub 讨论 |
| 🗯 一般性讨论 | GitHub 讨论或不和谐 |
🔗 链接和资源
| 类型 | 链接 |
|---|---|
| 💼 文档 | 阅读文档 |
| 💾 安装 | TTS/README.md |
| 👩 💻 贡献 | CONTRIBUTING.md |
| 📌 路线图 | 主要发展计划 |
| 🚀 已发布的型号 | TTS 版本和实验模型 |
| 📰 文件 | TTS论文 |
🥇 TTS 性能
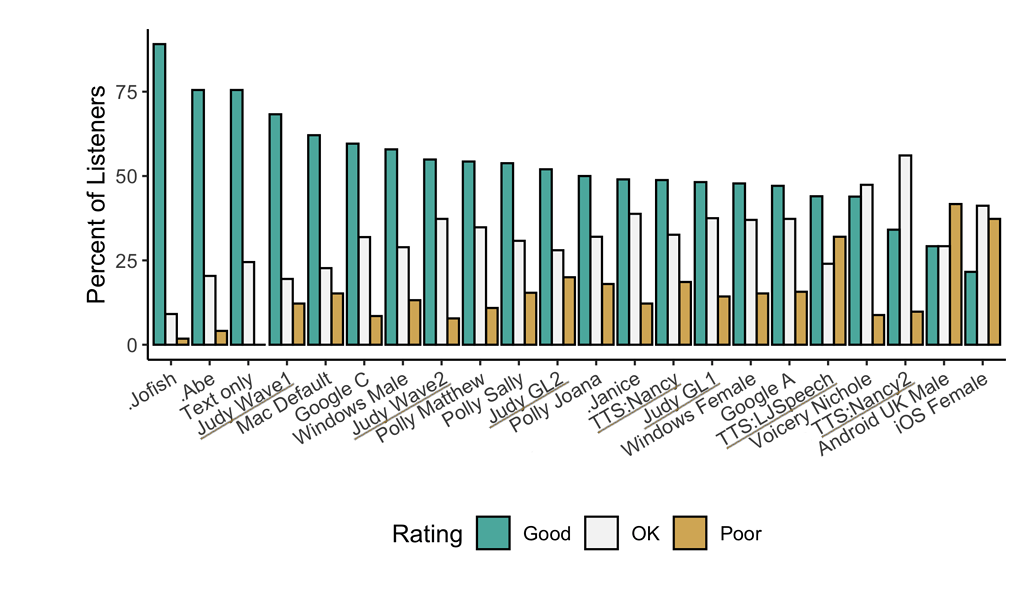
带下划线的“TTS*”和“Judy*”是未开源发布的内部 🐸TTS 模型。他们来这里是为了展示潜力。以点 (.乔菲什 .安倍和.珍妮丝)是真实的人类声音。
特征
- 用于文本2语音任务的高性能深度学习模型。
- Text2Spec 模型(Tacotron、Tacotron2、Glow-TTS、SpeedySpeech)。
- 扬声器编码器,用于有效计算扬声器嵌入。
- Vocoder models(MelGAN, Multiband-MelGAN, GAN-TTS, ParallelWaveGAN, WaveGrad, WaveRNN)
- 快速高效的模型训练。
- 终端和张量板上的详细训练日志。
- 支持多扬声器 TTS。
- 高效、灵活、轻便,但功能齐全。
Trainer API
- 已发布和即用型模型。
- 用于管理文本2语音数据集的工具。
dataset_analysis
- 用于使用和测试模型的实用程序。
- 模块化(但不是太多)代码库,可以轻松实现新想法。
模型实现
频谱图模型
- 塔科特龙:纸
- Tacotron2:纸
- 发光-TTS:纸
- 快速语音:纸
- 对齐-TTS:纸张
- 快速间距:纸
- 快速语音:纸
- 快速语音2:纸张
- SC-GlowTTS:纸
- 电容:纸
- 溢出:纸张
- 神经HMM TTS:纸
- 令人愉快的TTS:纸
端到端模型
注意方法
扬声器编码器
声码器
语音转换
- 免费VC:纸
你还可以帮助我们实施更多模型。
安装
🐸TTS 在 Ubuntu 18.04 上进行了测试,python >= 3.7,< 3.11。
如果你只对使用已发布🐸的 TTS 模型合成语音感兴趣,则从 PyPI 安装是最简单的选择。
pip install TTS如果计划编码或训练模型,请克隆 🐸TTS 并将其安装到本地。
git clone https://github.com/coqui-ai/TTS
pip install -e .[all,dev,notebooks] # Select the relevant extras如果你使用的是 Ubuntu (Debian),你也可以运行以下命令进行安装。
$ make system-deps # intended to be used on Ubuntu (Debian). Let us know if you have a different OS.
$ make install如果你使用的是Windows,👑 @GuyPaddock在此处编写了安装说明。
docker 镜像
你也可以尝试 TTS,而无需与 docker 映像一起安装。只需运行以下命令,你就可以在不安装的情况下运行 TTS。
docker run --rm -it -p 5002:5002 --entrypoint /bin/bash ghcr.io/coqui-ai/tts-cpu
python3 TTS/server/server.py --list_models #To get the list of available models
python3 TTS/server/server.py --model_name tts_models/en/vctk/vits # To start a server然后,你可以在此处享受TTS服务器 有关docker映像(如GPU支持)的更多详细信息,请参阅此处
TTS合成🐸语音
🐍 蟒蛇接口
运行多说话人和多语言模型
import torch
from TTS.api import TTS
# Get device
device = "cuda" if torch.cuda.is_available() else "cpu"
# List available 🐸TTS models and choose the first one
model_name = TTS().list_models()[0]
# Init TTS
tts = TTS(model_name).to(device)
# Run TTS
# ❗ Since this model is multi-speaker and multi-lingual, we must set the target speaker and the language
# Text to speech with a numpy output
wav = tts.tts("This is a test! This is also a test!!", speaker=tts.speakers[0], language=tts.languages[0])
# Text to speech to a file
tts.tts_to_file(text="Hello world!", speaker=tts.speakers[0], language=tts.languages[0], file_path="output.wav")运行单个扬声器模型
# Init TTS with the target model name
tts = TTS(model_name="tts_models/de/thorsten/tacotron2-DDC", progress_bar=False).to(device)
# Run TTS
tts.tts_to_file(text="Ich bin eine Testnachricht.", file_path=OUTPUT_PATH)
# Example voice cloning with YourTTS in English, French and Portuguese
tts = TTS(model_name="tts_models/multilingual/multi-dataset/your_tts", progress_bar=False).to(device)
tts.tts_to_file("This is voice cloning.", speaker_wav="my/cloning/audio.wav", language="en", file_path="output.wav")
tts.tts_to_file("C'est le clonage de la voix.", speaker_wav="my/cloning/audio.wav", language="fr-fr", file_path="output.wav")
tts.tts_to_file("Isso é clonagem de voz.", speaker_wav="my/cloning/audio.wav", language="pt-br", file_path="output.wav")语音转换示例
将语音转换为语音
source_wav
target_wav
tts = TTS(model_name="voice_conversion_models/multilingual/vctk/freevc24", progress_bar=False).to("cuda")
tts.voice_conversion_to_file(source_wav="my/source.wav", target_wav="my/target.wav", file_path="output.wav")语音克隆示例与语音转换模型一起。
这样,你可以使用 TTS 中的任何🐸模型克隆语音。
tts = TTS("tts_models/de/thorsten/tacotron2-DDC")
tts.tts_with_vc_to_file(
"Wie sage ich auf Italienisch, dass ich dich liebe?",
speaker_wav="target/speaker.wav",
file_path="output.wav"
)使用 🐸Coqui Studio 语音的示例。
你可以在Coqui Studio中🐸访问所有克隆的声音和内置扬声器。为此,你需要一个 API 令牌,你可以从帐户页面获取该令牌。获取 API 令牌后,需要配置 COQUI_STUDIO_TOKEN 环境变量。
获得有效的 API 令牌后,演播室扬声器将在列表中显示为不同的型号。这些模型将遵循命名约定
coqui_studio/en/<studio_speaker_name>/coqui_studio
# XTTS model
models = TTS(cs_api_model="XTTS").list_models()
# Init TTS with the target studio speaker
tts = TTS(model_name="coqui_studio/en/Torcull Diarmuid/coqui_studio", progress_bar=False)
# Run TTS
tts.tts_to_file(text="This is a test.", file_path=OUTPUT_PATH)
# V1 model
models = TTS(cs_api_model="V1").list_models()
# Run TTS with emotion and speed control
# Emotion control only works with V1 model
tts.tts_to_file(text="This is a test.", file_path=OUTPUT_PATH, emotion="Happy", speed=1.5)
# XTTS-multilingual
models = TTS(cs_api_model="XTTS-multilingual").list_models()
# Run TTS with emotion and speed control
# Emotion control only works with V1 model
tts.tts_to_file(text="Das ist ein Test.", file_path=OUTPUT_PATH, language="de", speed=1.0)使用 ~1100 种语言的 Fairseq 模型的文本到语音转换示例。 🤯
对于 Fairseq 型号,请使用以下名称格式:。你可以在此处找到语言ISO代码,并在此处了解Fairseq型号。
tts_models/<lang-iso_code>/fairseq/vits
# TTS with on the fly voice conversion
api = TTS("tts_models/deu/fairseq/vits")
api.tts_with_vc_to_file(
"Wie sage ich auf Italienisch, dass ich dich liebe?",
speaker_wav="target/speaker.wav",
file_path="output.wav"
)命令行 tts
在命令行上合成语音。
可以使用经过训练的模型,也可以从提供的列表中选择模型。
如果未指定任何模型,则它使用基于 LJSpeech 的英语模型。
单扬声器型号
-
列出提供的型号:
$ tts --list_models
-
获取模型信息(tts_models和vocoder_models):
-
按类型/名称查询:model_info_by_name使用来自 --list_models 的名称。
$ tts --model_info_by_name "<model_type>/<language>/<dataset>/<model_name>"
例如:
$ tts --model_info_by_name tts_models/tr/common-voice/glow-tts $ tts --model_info_by_name vocoder_models/en/ljspeech/hifigan_v2
-
按类型/idx 查询:model_query_idx使用 --list_models 中的相应 idx。
$ tts --model_info_by_idx "<model_type>/<model_query_idx>"
例如:
$ tts --model_info_by_idx tts_models/3
-
按全名查询模型信息:
$ tts --model_info_by_name "<model_type>/<language>/<dataset>/<model_name>"
-
-
使用默认模型运行 TTS:
$ tts --text "Text for TTS" --out_path output/path/speech.wav
-
使用默认声码器模型运行 TTS 模型:
$ tts --text "Text for TTS" --model_name "<model_type>/<language>/<dataset>/<model_name>" --out_path output/path/speech.wav
例如:
$ tts --text "Text for TTS" --model_name "tts_models/en/ljspeech/glow-tts" --out_path output/path/speech.wav
-
使用列表中的特定 TTS 和声码器模型运行:
$ tts --text "Text for TTS" --model_name "<model_type>/<language>/<dataset>/<model_name>" --vocoder_name "<model_type>/<language>/<dataset>/<model_name>" --out_path output/path/speech.wav
例如:
$ tts --text "Text for TTS" --model_name "tts_models/en/ljspeech/glow-tts" --vocoder_name "vocoder_models/en/ljspeech/univnet" --out_path output/path/speech.wav
-
运行你自己的TTS模型(使用Griffin-Lim声码器):
$ tts --text "Text for TTS" --model_path path/to/model.pth --config_path path/to/config.json --out_path output/path/speech.wav
-
运行你自己的 TTS 和声码器模型:
$ tts --text "Text for TTS" --model_path path/to/model.pth --config_path path/to/config.json --out_path output/path/speech.wav --vocoder_path path/to/vocoder.pth --vocoder_config_path path/to/vocoder_config.json
多扬声器型号
-
列出可用的扬声器并从中选择<speaker_id>:
$ tts --model_name "<language>/<dataset>/<model_name>" --list_speaker_idxs
-
使用目标扬声器 ID 运行多扬声器 TTS 模型:
$ tts --text "Text for TTS." --out_path output/path/speech.wav --model_name "<language>/<dataset>/<model_name>" --speaker_idx <speaker_id>
-
运行你自己的多扬声器 TTS 模型:
$ tts --text "Text for TTS" --out_path output/path/speech.wav --model_path path/to/model.pth --config_path path/to/config.json --speakers_file_path path/to/speaker.json --speaker_idx <speaker_id>
语音转换模型
$ tts --out_path output/path/speech.wav --model_name "<language>/<dataset>/<model_name>" --source_wav <path/to/speaker/wav> --target_wav <path/to/reference/wav>
目录结构
|- notebooks/ (Jupyter Notebooks for model evaluation, parameter selection and data analysis.)
|- utils/ (common utilities.)
|- TTS
|- bin/ (folder for all the executables.)
|- train*.py (train your target model.)
|- ...
|- tts/ (text to speech models)
|- layers/ (model layer definitions)
|- models/ (model definitions)
|- utils/ (model specific utilities.)
|- speaker_encoder/ (Speaker Encoder models.)
|- (same)
|- vocoder/ (Vocoder models.)
|- (same)
