devops-exercises - 包含Linux、Jenkins、AWS、SRE、Prometheus、Docker、Python、Ansible、Git、Kubernetes、Terraform、OpenStack、SQL、NoSQL、Azure、GCP、DNS、弹性、网络、虚拟化等DevOps 面试问题

i️ 此存储库包含有关各种技术主题的问题和练习,有时与 DevOps 和 SRE 相关
 开发运营 |
 吉特 |
 网络 |
 硬件 |
 Kubernetes |
 软件开发 |
 蟒 |
 去 |
 佩尔 |
 正则表达式 |
 云 |
 自主技术 |
 天蓝色 |
 谷歌云平台 |
 开放堆栈 |
 操作系统 |
 Linux目录 |
 虚拟化 |
 域名解析 |
 外壳脚本 |
 数据库 |
 .SQL |
 蒙戈 |
 测试 |
 大数据 |
 CI/CD |
 证书 |
 器皿 |
 开放移位 |
 存储 |
 大地形态 |
 木偶 |
 分散式 |
 你可以提出的问题 |
 安斯布尔 |
 可观察性 |
 普罗 米修斯 |
 圈子CI |
 |
 格拉法纳 |
 阿尔戈 |
 软技能 |
 安全 |
 系统设计 |
|
 混沌工程 |
 杂项 |
 弹性的 |
 卡 夫 卡 |
网络
一般来说,你需要什么才能沟通?
- 一种共同语言(供两端理解)
- 一种解决你想与谁沟通的方法
- 连接(以便通信内容可以到达收件人)
什么是以太网?
以太网仅指当今最常用的局域网(LAN)类型。与跨越较大地理区域的 WAN(广域网)相比,LAN 是位于小区域(如办公室、大学校园甚至家庭)的计算机连接网络。
什么是 MAC 地址?它的用途是什么?
MAC 地址是用于标识网络上各个设备的唯一标识号或代码。
在以太网上发送的数据包始终来自 MAC 地址并发送到 MAC 地址。如果网络适配器正在接收数据包,则会将数据包的目标 MAC 地址与适配器自己的 MAC 地址进行比较。
何时使用此 MAC 地址?: ff:ff:ff:ff:ff:ff:ff
当设备将数据包发送到广播 MAC 地址 (FF:FF:FF:FF:FF) 时,该数据包将传送到本地网络上的所有站点。以太网广播用于在数据链路层将 IP 地址解析为 MAC 地址(通过 ARP)。
什么是 IP 地址?
互联网协议地址(IP 地址)是分配给连接到使用互联网协议进行通信的计算机网络的每个设备的数字标签。IP 地址有两个主要功能:主机或网络接口识别和位置寻址。
解释子网掩码并举例说明
子网掩码是一个 32 位数字,用于屏蔽 IP 地址并将 IP 地址划分为网络地址和主机地址。子网掩码是通过将网络位设置为所有“1”并将主机位设置为所有“0”来实现的。在给定的网络中,在总可用主机地址中,有两个始终保留用于特定目的,不能分配给任何主机。这些是保留为网络地址(也称为网络 ID)的第一个地址,也是用于网络广播的最后一个地址。
什么是私有 IP 地址?在哪些场景/系统设计中,应该使用它?
专用 IP 地址分配给同一网络中的主机以相互通信。顾名思义,“专用”一词表明,任何外部网络的设备都无法访问分配了专用 IP 地址的设备。例如,如果我住在宿舍,我希望我的宿舍伙伴加入我托管的游戏服务器,我会要求他们通过我服务器的私有IP地址加入,因为网络是宿舍的本地网络。
什么是公共 IP 地址?在哪些场景/系统设计中,应该使用它?
公共 IP 地址是面向公众的 IP 地址。如果你托管的游戏服务器希望你的朋友加入,你将为你的朋友提供你的公共 IP 地址,以允许他们的计算机识别和定位你的网络和服务器,以便进行连接。有一次,你不需要使用面向公众的 IP 地址,如果你与与你连接到同一网络的朋友一起玩,在这种情况下,你将使用私有 IP 地址。为了使某人能够连接到位于内部的服务器,你必须设置一个端口转发以告诉你的路由器允许来自公共域的流量进入你的网络,反之亦然。
解释 OSI 模型。有哪些层次?每一层负责什么?
- 应用:用户端(HTTP在这里)
- 演示:在应用层实体之间建立上下文(此处为加密)
- 会话:建立、管理和终止连接
- 传输:将可变长度的数据序列从源主机传输到目标主机(TCP和UDP在这里)
- 网络:将数据报从一个网络传输到另一个网络(IP 在这里)
- 数据链路:提供两个直接连接的节点之间的链路(MAC在这里)
- 物理:数据连接的电气和物理规格(位在这里)
你可以在 penguintutor.com 中阅读有关 OSI 模型的更多信息
对于以下每个选项,确定它属于哪个 OSI 层:
- 纠错
- 数据包路由
- 电缆和电信号
- MAC地址
- IP地址
- 终止连接
- 3 路握手
你熟悉哪些交付方案?
单播:一对一通信,其中有一个发送方和一个接收方。
广播:向网络中的每个人发送消息。地址 ff:ff:ff:ff:ff:ff 用于广播。使用广播的两种常见协议是ARP和DHCP。
多播:向一组订阅者发送消息。它可以是一对多或多对多。
什么是CSMA/CD?它是否用于现代以太网网络?
CSMA/CD 代表 载波检测多址/碰撞检测。它的主要重点是管理对共享介质/总线的访问,其中只有一个主机可以在给定的时间点进行传输。
CSMA/CD 算法:
- 在发送帧之前,它会检查另一个主机是否已在传输帧。
- 如果没有人在传输,它将开始传输帧。
- 如果两台主机同时传输,则会发生冲突。
- 两个主机都停止发送帧,并向每个人发送“卡纸信号”,通知每个人发生了碰撞
- 他们正在等待一个随机的时间,然后再发送
- 一旦每个主机等待随机时间,他们就会尝试再次发送帧,因此循环再次开始
描述以下网络设备及其之间的区别:
- 路由器
- 开关
- 枢纽
路由器、交换机和集线器都是用于连接局域网 (LAN) 中的设备的网络设备。但是,每个设备的运行方式不同,并且有其特定的用例。以下是每个设备的简要说明以及它们之间的差异:
- 路由器:将多个网段连接在一起的网络设备。它在 OSI 模型的网络层(第 3 层)运行,并使用路由协议在网络之间定向数据。路由器使用 IP 地址来识别设备并将数据包路由到正确的目的地。
- 交换机:连接局域网上多个设备的网络设备。它在 OSI 模型的数据链路层(第 2 层)运行,并使用 MAC 地址来识别设备并将数据包定向到正确的目的地。交换机允许同一网络上的设备更有效地相互通信,并且可以防止多个设备同时发送数据时可能发生的数据冲突。
- 集线器:通过单根电缆连接多个设备的网络设备,用于连接多个设备而不分段网络。但是,与交换机不同,它在 OSI 模型的物理层(第 1 层)运行,并且只是将数据包广播到与其连接的所有设备,无论该设备是否是预期的接收方。这意味着可能会发生数据冲突,因此网络的效率可能会受到影响。集线器通常不用于现代网络设置,因为交换机效率更高,网络性能更好。
什么是“冲突域”?
冲突域是一个网段,其中设备可能会通过尝试同时传输数据来相互干扰。当两个设备同时传输数据时,可能会导致冲突,从而导致数据丢失或损坏。在冲突域中,所有设备共享相同的带宽,任何设备都可能干扰其他设备的数据传输。
什么是“广播域”?
广播域是一个网段,其中所有设备都可以通过发送广播消息相互通信。广播消息是发送到网络中的所有设备而不是特定设备的消息。在广播域中,所有设备都可以接收和处理广播消息,无论该消息是否适用于它们。
连接到交换机的三台计算机。有多少个冲突域?有多少个广播域?
三个冲突域和一个广播域
路由器如何工作?
路由器是在两个或多个分组交换计算机网络之间传递信息的物理或虚拟设备。路由器检查给定数据包的目标 Internet 协议地址(IP 地址),计算其到达目的地的最佳方式,然后相应地转发它。
什么是纳特?
网络地址转换 (NAT) 是将一个或多个本地 IP 地址转换为一个或多个全局 IP 地址的过程,反之亦然,以便为本地主机提供 Internet 访问。
什么是代理?它是如何工作的?我们需要它做什么?
代理服务器充当你和互联网之间的网关。它是一个中间服务器,将最终用户与他们浏览的网站分开。
如果你使用的是代理服务器,则互联网流量会流经代理服务器到达你请求的地址。然后,请求通过同一代理服务器返回(此规则有例外),然后代理服务器将从网站接收的数据转发给你。
代理服务器提供不同级别的功能、安全性和隐私,具体取决于你的用例、需求或公司策略。
什么是 TCP?它是如何工作的?什么是 3 向握手?
TCP 3 向握手或 TCP/IP 网络中用于在服务器和客户端之间建立连接的过程。
三次握手主要用于创建 TCP 套接字连接。它在以下情况下有效:
- 客户机节点通过 IP 网络将 SYN 数据包发送到同一网络或外部网络上的服务器。此数据包的目的是询问/推断服务器是否为新连接打开。
- 目标服务器必须具有可以接受和启动新连接的开放端口。当服务器从客户端节点接收到 SYN 数据包时,它会响应并返回确认回执 – ACK 数据包或 SYN/ACK 数据包。
- 客户机节点从服务器接收 SYN/ACK 并使用 ACK 数据包进行响应。
SSL 握手如何工作?
SSL 握手是在客户端和服务器之间建立安全连接的过程。
- 客户端向服务器发送客户端 Hello 消息,其中包括客户端的 SSL/TLS 协议版本、客户端支持的加密算法列表以及随机值。
- 服务器使用服务器问候消息进行响应,其中包括服务器的 SSL/TLS 协议版本、随机值和会话 ID。
- 服务器发送包含服务器证书的证书消息。
- 服务器发送“服务器问候完成”消息,指示服务器已完成“服务器问候”阶段的消息发送完毕。
- 客户端发送客户端密钥交换消息,其中包含客户端的公钥。
- 客户端发送更改密码规范消息,通知服务器客户端将发送使用新密码规范加密的消息。
- 客户端发送加密握手消息,其中包含使用服务器公钥加密的预主密钥密钥。
- 服务器发送更改密码规范消息,通知客户端服务器将发送使用新密码规范加密的消息。
- 服务器发送加密握手消息,其中包含使用客户端公钥加密的预主密钥。
- 客户端和服务器现在可以交换应用程序数据。
TCP和UDP有什么区别?
TCP在客户端和服务器之间建立连接以保证包的顺序,另一方面,UDP不会在客户端和服务器之间建立连接,也不处理包订单。这使得UDP比TCP更轻量级,并且是流等服务的完美候选者。
Penguintutor.com 提供了一个很好的解释。
你熟悉哪些 TCP/IP 协议?
解释“默认网关”
默认网关充当接入点或 IP 路由器,联网计算机使用该接入点或 IP 路由器将信息发送到另一个网络或 Internet 中的计算机。
什么是 ARP?它是如何工作的?
ARP 代表 地址解析协议。当你尝试 ping 本地网络上的 IP 地址(例如 192.168.1.1)时,你的系统必须将 IP 地址 192.168.1.1 转换为 MAC 地址。这涉及使用 ARP 解析地址,因此得名。
系统保留一个 ARP 查找表,其中存储有关哪些 IP 地址与哪些 MAC 地址关联的信息。当尝试将数据包发送到 IP 地址时,系统将首先查阅此表以查看它是否已经知道 MAC 地址。如果缓存了值,则不使用 ARP。
什么是TTL?它有助于预防什么?
- TTL(生存时间)是 IP(互联网协议)数据包中的一个值,用于确定数据包在被丢弃之前可以传输多少跃点或路由器。路由器每次转发数据包时,TTL 值都会减少 1。当 TTL 值达到零时,数据包将被丢弃,并且 ICMP(互联网控制消息协议)消息将发送回发送方,指示数据包已过期。
- TTL 用于防止数据包在网络中无限期地循环,这可能会导致拥塞并降低网络性能。
- 它还有助于防止数据包被困在路由环路中,其中数据包在同一组路由器之间连续传输而不会到达目的地。
- 此外,TTL 还可用于帮助检测和防止 IP 欺骗攻击,即攻击者尝试使用虚假或虚假 IP 地址模拟网络上的另一台设备。通过限制数据包可以传输的跃点数,TTL 可以帮助防止数据包路由到不合法的目标。
什么是DHCP?它是如何工作的?
它代表动态主机配置协议,并将 IP 地址、子网掩码和网关分配给主机。这是它的工作原理:
- 主机在进入网络时广播消息以搜索 DHCP 服务器 (DHCP 发现)
- DHCP 服务器将报价消息作为包含租用时间、子网掩码、IP 地址等的数据包发回(DHCP 报价)
- 根据接受的提议,客户端会发回回复广播,让所有 DHCP 服务器知道(DHCP 请求)
- 服务器发送确认(DHCP 确认)
在此处阅读更多内容
你可以在同一网络上有两个DHCP服务器吗?它是如何工作的?
在同一网络上可以有两个DHCP服务器,但是,不建议这样做,并且仔细配置它们以防止冲突和配置问题非常重要。
- 在同一网络上配置两台 DHCP 服务器时,两台服务器都有将 IP 地址和其他网络配置设置分配给同一设备的风险,这可能会导致冲突和连接问题。此外,如果 DHCP 服务器配置了不同的网络设置或选项,则网络上的设备可能会收到冲突或不一致的配置设置。
- 但是,在某些情况下,可能需要在同一网络上有两个 DHCP 服务器,例如在大型网络中,一个 DHCP 服务器可能无法处理所有请求。在这种情况下,可以将 DHCP 服务器配置为为不同的 IP 地址范围或不同的子网提供服务,以便它们不会相互干扰。
什么是 SSL 隧道?它是如何工作的?
- SSL(安全套接字层)隧道是一种技术,用于通过不安全的网络(如 Internet)在两个端点之间建立安全的加密连接。SSL 隧道是通过将流量封装在 SSL 连接中创建的,该连接提供机密性、完整性和身份验证。
以下是 SSL 隧道的工作原理:
- 客户端启动与服务器的 SSL 连接,这涉及建立 SSL 会话的握手过程。
- 建立 SSL 会话后,客户端和服务器协商加密参数(如加密算法和密钥长度),然后交换数字证书以相互进行身份验证。
- 然后,客户端通过 SSL 隧道将流量发送到服务器,服务器解密流量并将其转发到目标。
- 服务器通过 SSL 隧道将流量发送回客户端,客户端解密流量并将其转发到应用程序。
什么是套接字?在哪里可以看到系统中的套接字列表?
- 套接字是一个软件终结点,可通过网络在进程之间进行双向通信。套接字为网络通信提供标准化接口,允许应用程序通过网络发送和接收数据。要查看 Linux 系统上打开的套接字列表:netstat -an
- 此命令显示所有打开的套接字的列表,以及它们的协议、本地地址、外部地址和状态。
什么是 IPv6?如果我们有IPv4,我们为什么要考虑使用它?
- IPv6(互联网协议版本 6)是互联网协议 (IP) 的最新版本,用于识别网络上的设备并与之通信。IPv6 地址是 128 位地址,以十六进制表示法表示,例如 2001:0db8:85a3:0000:0000:8a2e:0370:7334。
我们应该考虑使用 IPv6 而不是 IPv4 有几个原因:
- 地址空间:IPv4 的地址空间有限,在世界许多地方已经用尽。IPv6 提供了更大的地址空间,允许数万亿个唯一 IP 地址。
- 安全性:IPv6 包括对 IPsec 的内置支持,可为网络流量提供端到端加密和身份验证。
- 性能:IPv6 包括有助于提高网络性能的功能,例如组播路由,它允许将单个数据包同时发送到多个目标。
- 简化的网络配置:IPv6 包括可以简化网络配置的功能,例如无状态自动配置,它允许设备自动配置自己的 IPv6 地址,而无需 DHCP 服务器。
- 更好的移动支持:IPv6 包括可以改进移动支持的功能,例如移动 IPv6,它允许设备在不同网络之间移动时维护其 IPv6 地址。
什么是虚拟局域网?
- VLAN(虚拟局域网)是一种逻辑网络,它将物理网络上的一组设备组合在一起,无论其物理位置如何。VLAN 是通过配置网络交换机为连接到交换机上特定端口或端口组的设备发送的帧分配特定的 VLAN ID 来创建的。
什么是 MTU?
MTU 代表 最大传输单位。它是可以在单个事务中发送的最大 PDU(协议数据单元)的大小。
如果发送的数据包大于 MTU,会发生什么情况?
使用 IPv4 协议,路由器可以对 PDU 进行分段,然后通过事务发送所有分段的 PDU。
使用 IPv6 协议时,它会向用户的计算机发出错误。
是真是假?Ping正在使用UDP,因为它不关心可靠的连接
假。Ping实际上使用的是ICMP(互联网控制消息协议),这是一种网络协议,用于发送诊断消息和控制与网络通信相关的消息。
什么是 SDN?
- SDN 代表 软件定义的网络。它是一种强调网络控制的集中化的网络管理方法,使管理员能够通过软件抽象来管理网络行为。
- 在传统网络中,路由器、交换机和防火墙等网络设备是使用专用软件或命令行界面单独配置和管理的。相比之下,SDN 将网络控制平面与数据平面分开,允许管理员通过集中式软件控制器管理网络行为。
什么是ICMP?它的用途是什么?
- ICMP 代表 互联网控制消息协议。它是用于IP网络中诊断和控制目的的协议。它是互联网协议套件的一部分,在网络层运行。
ICMP 消息用于多种用途,包括:
- 错误报告:ICMP 消息用于报告网络中发生的错误,例如无法传递到其目标的数据包。
- Ping:ICMP 用于发送 ping 消息,这些消息用于测试主机或网络是否可访问,并测量数据包的往返时间。
- 路径 MTU 发现:ICMP 用于发现路径的最大传输单元 (MTU),这是可以在不分段的情况下传输的最大数据包大小。
- 跟踪路由:跟踪路由实用程序使用 ICMP 来跟踪数据包通过网络的路径。
- 路由器发现:ICMP 用于发现网络中的路由器。
什么是纳特?它是如何工作的?
NAT 代表 网络地址转换。这是一种在传输信息之前将多个本地专用地址映射到公共地址的方法。希望多个设备使用单个 IP 地址的组织使用 NAT,大多数家用路由器也是如此。例如,你计算机的专用 IP 可能是 192.168.1.100,但你的路由器将流量映射到其公共 IP(例如 1.1.1.1)。互联网上的任何设备都会看到来自你的公共 IP (1.1.1.1) 而不是你的私有 IP (192.168.1.100) 的流量。
以下每个协议中使用哪个端口号?
- 固态度
- 短信通信
- HTTP
- 域名解析
- HTTPS
- 邮票
- 自来水龙
- SSH - 22
- SMTP - 25
- HTTP - 80
- DNS - 53
- HTTPS - 443
- FTP - 21
- SFTP - 22
哪些因素会影响网络性能?
有几个因素会影响网络性能,包括:
- 带宽:网络连接的可用带宽会显著影响其性能。带宽有限的网络可能会遇到数据传输速率慢、延迟高和响应能力差的问题。
- 延迟:延迟是指数据从网络中的一个点传输到另一个点时发生的延迟。高延迟会导致网络性能降低,尤其是对于视频会议和在线游戏等实时应用程序。
- 网络拥塞:当太多设备同时使用网络时,可能会发生网络拥塞,从而导致数据传输速率缓慢和网络性能不佳。
- 丢包:在传输过程中丢弃数据包时,会发生丢包。这可能会导致网络速度变慢,整体网络性能降低。
- 网络拓扑:网络的物理布局(包括交换机、路由器和其他网络设备的放置)可能会影响网络性能。
- 网络协议:不同的网络协议具有不同的性能特征,这可能会影响网络性能。例如,TCP 是一种可靠的协议,可以保证数据的传递,但由于错误检查和重新传输所需的开销,它也可能导致性能降低。
- 网络安全:防火墙和加密等安全措施可能会影响网络性能,尤其是在它们需要强大的处理能力或引入额外延迟时。
- 距离:网络上设备之间的物理距离会影响网络性能,尤其是对于信号强度和干扰会影响连接和数据传输速率的无线网络。
什么是APIPA?
APIPA 是一组 IP 地址,当无法访问主 DHCP 服务器时,设备将分配这些地址
APIPA使用什么IP范围?
APIPA使用的IP范围:169.254.0.1 - 169.254.255.254。
控制平面和数据平面
“控制平面”指的是什么?
控制平面是网络的一部分,用于决定如何将数据包路由和转发到其他位置。
“数据平面”指的是什么?
数据平面是实际转发数据/数据包的网络的一部分。
“管理平面”指的是什么?
它指的是监视和管理功能。
创建路由表属于哪个平面(数据、控制等)?
控制平面。
解释生成树协议 (STP)。
什么是链路聚合?为什么使用它?
什么是非对称路由?如何处理?
你熟悉哪些覆盖(隧道)协议?
什么是 GRE?它是如何工作的?
什么是VXLAN?它是如何工作的?
什么是SNAT?
解释 OSPF。
OSPF(开放最短路径优先)是一种路由协议,可以在各种类型的路由器上实现。通常,大多数现代路由器都支持 OSPF,包括思科、瞻博网络和华为等供应商的路由器。该协议旨在与基于 IP 的网络(包括 IPv4 和 IPv6)配合使用。此外,它使用分层网络设计,其中路由器被分组到区域中,每个区域都有自己的拓扑图和路由表。这种设计有助于减少需要在路由器之间交换的路由信息量,并提高网络可扩展性。
OSPF 4 类型的路由器包括:
- 内置路由器
- 区域边界路由器
- 自治系统边界路由器
- 骨干路由器
了解有关 OSPF 路由器类型的更多信息:https://www.educba.com/ospf-router-types/
什么是延迟?
延迟是信息从源到达目的地所花费的时间。
什么是带宽?
带宽是通信通道衡量后者在特定时间段内可以处理多少数据的能力。更多的带宽意味着更多的流量处理,从而更多的数据传输。
什么是吞吐量?
吞吐量是指对特定时间段内通过任何传输通道传输的实际数据量的测量。
执行搜索查询时,延迟或吞吐量哪个更重要?如何确保我们管理全球基础设施?
延迟。为了获得良好的延迟,应将搜索查询转发到最近的数据中心。
上传视频时,延迟和吞吐量哪个更重要?如何保证这一点?
吞吐量。为了获得良好的吞吐量,应将上传流路由到未充分利用的链路。
转发请求时还有哪些其他注意事项(延迟和吞吐量除外)?
- 保持缓存更新(这意味着请求可能不会转发到最近的数据中心)
解释脊柱和叶子
什么是网络拥塞?什么原因造成的?
当网络上要传输的数据太多并且没有足够的容量来处理需求时,就会发生网络拥塞。这可能会导致延迟增加和数据包丢失。原因可能有多种,例如网络使用率高、文件传输量大、恶意软件、硬件问题或网络设计问题。为了防止网络拥塞,监控网络使用情况并实施限制或管理需求的策略非常重要。
关于UDP数据包格式,你能告诉我什么?TCP 数据包格式如何?它有什么不同?
什么是指数退避算法?它在哪里使用?
使用汉明码,以下数据字100111010001101的代码字是什么?
00110011110100011101
给出应用层中发现的协议示例
- 超文本传输协议 (HTTP) - 用于互联网上的网页
- 简单邮件传输协议 (SMTP) - 电子邮件传输
- 电信网络 - (TELNET) - 终端仿真,允许客户端访问 telnet 服务器
- 文件传输协议 (FTP) - 便于在任意两台计算机之间传输文件
- 域名系统 (DNS) - 域名翻译
- 动态主机配置协议 (DHCP) - 将 IP 地址、子网掩码和网关分配给主机
- 简单网络管理协议 (SNMP) - 收集网络上设备上的数据
给出在网络层中找到的协议示例
- 互联网协议 (IP) - 协助将数据包从一台机器路由到另一台机器
- 互联网控制消息协议 (ICMP) - 让人们知道发生了什么,例如错误消息和调试信息
什么是HSTS?
HTTP 严格传输安全是一个 Web 服务器指令,它通过一开始发送并返回到浏览器的响应标头通知用户代理和 Web 浏览器如何处理其连接。这会强制通过 HTTPS 加密进行连接,而忽略任何脚本通过 HTTP 加载该域中的任何资源的调用。
网络 - 杂项
什么是互联网?它和万维网一样吗?
互联网是指一个网络网络,在全球范围内传输大量数据。
万维网是在互联网之上的数百万台服务器上运行的应用程序,通过所谓的网络浏览器访问
什么是互联网服务提供商?
ISP(互联网服务提供商)是本地互联网公司提供商。
操作系统
操作系统练习
| 名字 | 主题 | 目标和说明 | 溶液 | 评论 |
|---|---|---|---|---|
| 叉子 101 | 叉 | 链接 | 链接 | |
| 叉 102 | 叉 | 链接 | 链接 |
操作系统 - 自我评估
什么是操作系统?
摘自《操作系统:三个简单的部分》一书:
“负责使运行程序变得容易(甚至允许你同时运行许多程序),允许程序共享内存,使程序能够与设备交互,以及其他类似有趣的东西”。
操作系统 - 进程
你能解释一下什么是过程吗?
进程是正在运行的程序。程序是一条或多条指令,程序(或进程)由操作系统执行。
如果必须为操作系统中的进程设计一个 API,那么这个 API 会是什么样子的?
它将支持以下内容:
- 创建 - 允许创建新进程
- 删除 - 允许删除/销毁进程
- 状态 - 允许检查进程的状态,是否正在运行,已停止,等待等。
- 停止 - 允许停止正在运行的进程
如何创建流程?
- 操作系统正在读取程序的代码和任何其他相关数据
- 程序的代码被加载到内存中,或者更具体地说,加载到进程的地址空间中。
- 内存是为程序的堆栈(也称为运行时堆栈)分配的。堆栈还由操作系统使用argv,argc和main()参数等数据进行初始化
- 内存是为程序的堆分配的,这是动态分配的数据(如数据结构链表和哈希表)所必需的
- 执行 I/O 初始化任务,例如在基于 Unix/Linux 的系统中,每个进程都有 3 个文件描述符(输入、输出和错误)
- 操作系统正在运行程序,从main()开始
是真是假?将程序加载到内存中是急切完成的(一次全部)
假。过去确实如此,但今天的操作系统执行延迟加载,这意味着仅首先加载进程运行所需的相关部分。
流程有哪些不同的状态?
- 运行 - 它正在执行指令
- 就绪 - 它已准备好运行,但由于不同的原因它处于暂停状态
- 已阻止 - 它正在等待某些操作完成。例如 I/O 磁盘请求
进程被阻止的原因有哪些?
- I/O 操作(例如,从磁盘读取)
- 等待来自网络的数据包
什么是进程间通信 (IPC)?
什么是“分时”?
即使使用具有一个物理 CPU 的系统,也可以允许多个用户在其上工作并运行程序。这可以通过分时来实现,其中计算资源共享的方式在用户看来系统有多个CPU,但实际上它只是通过应用多并发和多任务共享一个CPU。
什么是“空间共享”?
与分时度假有些相反。在时间共享中,一个实体使用资源一段时间,然后同一资源可以被另一个资源使用,而在空间共享中,空间由多个实体共享,但不会在它们之间传输。
它由一个实体使用,直到该实体决定摆脱它。以存储为例。在存储中,文件是你的,直到你决定删除它。
哪个组件确定在给定时刻运行哪个进程?
中央处理器调度程序
操作系统 - 内存
什么是“虚拟内存”,它有什么用途?
虚拟内存将计算机的 RAM 与硬盘上的临时空间相结合。当 RAM 不足时,虚拟内存有助于将数据从 RAM 移动到称为分页文件的空间。将数据移动到分页文件可以释放 RAM,以便你的计算机可以完成其工作。通常,计算机的RAM越多,程序运行的速度就越快。https://www.minitool.com/lib/virtual-memory.html
什么是需求分页?
什么是写入时复制?
写入时复制 (COW) 是一种资源管理概念,其目标是减少不必要的信息复制。这是一个概念,例如在 POSIX fork 系统调用中实现,它创建调用进程的重复进程。
这个想法:
- 如果在 2 个或更多实体之间共享资源(例如 2 个进程之间的共享内存段),则不需要为每个实体复制资源,而是每个实体对共享资源具有 READ 操作访问权限。(共享的隔离标记为只读)(想想每个实体都有一个指向共享资源位置的指针,可以取消引用该指针以读取其值)
- 如果一个实体对共享资源执行 WRITE 操作,则会出现问题,因为共享该资源的所有其他实体也会永久更改。(想想一个进程修改堆栈上的一些变量,或者在堆上动态分配一些数据,这些对共享资源的更改也适用于所有其他进程,这绝对是一种不希望的行为)
- 仅当即将对共享资源执行 WRITE 操作时,作为解决方案,此资源首先被复制,然后应用更改。
什么是内核,它有什么作用?
内核是操作系统的一部分,负责以下任务:
- 分配内存
- 安排流程
- 控制中央处理器
是真是假?内核中的某些代码片段被加载到内存的受保护区域中,因此应用程序无法覆盖它们
真
什么是POSIX?
解释什么是信号量及其在操作系统中的作用
什么是缓存?什么是缓冲区?
缓冲区:RAM中的保留位置,用于临时保存数据 缓存:缓存通常在进程读取和写入磁盘时使用,通过使不同程序使用的类似数据易于访问来加快进程速度。
虚拟化
什么是虚拟化?
虚拟化使用软件在计算机硬件上创建一个抽象层,允许将单个计算机的硬件元素(处理器、内存、存储等)划分为多个虚拟计算机,通常称为虚拟机 (VM)。
什么是虚拟机管理程序?
红帽:“虚拟机管理程序是创建和运行虚拟机 (VM) 的软件。虚拟机监控程序(有时称为虚拟机监视器 (VMM))将虚拟机管理程序操作系统和资源与虚拟机隔离开来,并允许创建和管理这些虚拟机。
在此处阅读更多内容
有哪些类型的虚拟机管理程序?
托管虚拟机管理程序和裸机虚拟机管理程序。
与托管虚拟机管理程序相比,裸机虚拟机管理程序的优点和缺点是什么?
由于具有自己的驱动程序和对硬件组件的直接访问,裸机虚拟机管理程序通常具有更好的性能以及稳定性和可扩展性。
另一方面,加载(任何)驱动程序可能会有一些限制,因此托管虚拟机管理程序通常会受益于更好的硬件兼容性。
有哪些类型的虚拟化?
操作系统虚拟化 网络功能虚拟化 桌面虚拟化
容器化是一种虚拟化吗?
是的,这是一个操作系统级别的虚拟化,其中内核是共享的,并允许使用多个隔离的用户空间实例。
虚拟机的引入如何改变了行业和应用程序的部署方式?
虚拟机的引入允许公司在同一硬件上部署多个业务应用程序,而每个应用程序都以安全的方式彼此分离,每个应用程序都在自己单独的操作系统上运行。
虚拟机
在容器时代,我们需要虚拟机吗?它们是否仍然相关?
是的,即使在容器时代,虚拟机仍然具有相关性。虽然容器为虚拟机提供了一种轻量级和可移植的替代方案,但它们确实存在一定的局限性。虚拟机仍然很重要,因为它们提供隔离和安全性,可以运行不同的操作系统,并且适用于旧版应用。例如,容器限制是共享主机内核。
普罗 米修斯
什么是普罗米修斯?普罗米修斯的主要特点是什么?
Prometheus是一个流行的开源系统监控和警报工具包,最初由SoundCloud开发。它旨在收集和存储时间序列数据,并允许使用称为 PromQL 的强大查询语言查询和分析该数据。Prometheus 经常用于监控云原生应用程序、微服务和其他现代基础架构。
普罗米修斯的一些主要功能包括:
1. Data model: Prometheus uses a flexible data model that allows users to organize and label their time-series data in a way that makes sense for their particular use case. Labels are used to identify different dimensions of the data, such as the source of the data or the environment in which it was collected. 2. Pull-based architecture: Prometheus uses a pull-based model to collect data from targets, meaning that the Prometheus server actively queries its targets for metrics data at regular intervals. This architecture is more scalable and reliable than a push-based model, which would require every target to push data to the server. 3. Time-series database: Prometheus stores all of its data in a time-series database, which allows users to perform queries over time ranges and to aggregate and analyze their data in various ways. The database is optimized for write-heavy workloads, and can handle a high volume of data with low latency. 4. Alerting: Prometheus includes a powerful alerting system that allows users to define rules based on their metrics data and to send alerts when certain conditions are met. Alerts can be sent via email, chat, or other channels, and can be customized to include specific details about the problem. 5. Visualization: Prometheus has a built-in graphing and visualization tool, called PromDash, which allows users to create custom dashboards to monitor their systems and applications. PromDash supports a variety of graph types and visualization options, and can be customized using CSS and JavaScript.
总体而言,Prometheus 是一款强大而灵活的监控和分析系统和应用程序的工具,在业界广泛用于云原生监控和可观测性。
在什么情况下最好不要使用普罗米修斯?
来自 Prometheus 文档:“如果你需要 100% 的准确性,例如按请求计费”。
描述普罗米修斯架构和组件
普罗米修斯架构由四个主要组件组成:
1. Prometheus Server: The Prometheus server is responsible for collecting and storing metrics data. It has a simple built-in storage layer that allows it to store time-series data in a time-ordered database. 2. Client Libraries: Prometheus provides a range of client libraries that enable applications to expose their metrics data in a format that can be ingested by the Prometheus server. These libraries are available for a range of programming languages, including Java, Python, and Go. 3. Exporters: Exporters are software components that expose existing metrics from third-party systems and make them available for ingestion by the Prometheus server. Prometheus provides exporters for a range of popular technologies, including MySQL, PostgreSQL, and Apache. 4. Alertmanager: The Alertmanager component is responsible for processing alerts generated by the Prometheus server. It can handle alerts from multiple sources and provides a range of features for deduplicating, grouping, and routing alerts to appropriate channels.
总体而言,Prometheus 架构旨在实现高度可扩展和弹性。服务器和客户端库可以以分布式方式部署,以支持跨大规模、高度动态环境的监视
你能将Prometheus与其他解决方案(如InfluxDB)进行比较吗?
与其他监控解决方案(如InfluxDB)相比,Prometheus以其高性能和可扩展性而闻名。它可以处理大量数据,并且可以轻松地与监控生态系统中的其他工具集成。另一方面,InfluxDB以其易用性和简单性而闻名。它具有用户友好的界面,并提供易于使用的API来收集和查询数据。
另一个流行的解决方案Nagios是一个更传统的监控系统,它依赖于基于推送的模型来收集数据。Nagios已经存在了很长时间,以其稳定性和可靠性而闻名。然而,与Prometheus相比,Nagios缺少一些更高级的功能,例如多维数据模型和强大的查询语言。
总体而言,监视解决方案的选择取决于组织的特定需求和要求。虽然 Prometheus 是大规模监控和警报的绝佳选择,但 InfluxDB 可能更适合需要易用性和简单性的小型环境。对于优先考虑稳定性和可靠性而不是高级功能的组织来说,Nagios 仍然是一个可靠的选择。
什么是警报?
在 Prometheus 中,警报是在满足特定条件或阈值时触发的通知。可以将警报配置为在某些指标超过特定阈值或发生特定事件时触发。触发警报后,可以将其路由到各种渠道,例如电子邮件、寻呼机或聊天,以通知相关团队或个人采取适当的措施。警报是任何监视系统的关键组件,因为它们允许团队在问题影响用户或导致系统停机之前主动检测和响应问题。
什么是实例?什么是工作?
在普罗米修斯中,实例是指正在监视的单个目标。例如,单个服务器或服务。作业是一组执行相同功能的实例,例如一组为同一应用程序提供服务的 Web 服务器。作业允许你一起定义和管理一组目标。
从本质上讲,实例是 Prometheus 从中收集指标的单个目标,而作业是可以作为一个组管理的类似实例的集合。
普罗米修斯支持哪些核心指标类型?
Prometheus 支持多种类型的指标,包括:
1. 计数器:用于跟踪事件或样本计数的单调递增值。示例包括处理的请求数或遇到的错误总数。2. 仪表:可以上升或下降的值,例如 CPU 使用率或内存使用率。与计数器不同,仪表值可以是任意的,这意味着它们可以根据被监视系统的变化而上升和下降。3. 直方图:一组根据其值划分为桶的观测值或事件。直方图有助于分析指标的分布,例如请求延迟或响应大小。4. 摘要:摘要类似于直方图,但它不是存储桶,而是为观测值提供一组分位数。摘要可用于监视请求延迟或响应大小随时间推移的分布。Prometheus 还支持各种函数和运算符来聚合和操作指标,例如总和、最大值、最小值和速率。这些功能使其成为监视和警报系统指标的强大工具。
什么是出口商?它的用途是什么?
导出器充当第三方系统或应用程序与 Prometheus 之间的桥梁,使 Prometheus 能够监控和收集来自该系统或应用程序的数据。
导出器充当服务器,在特定网络端口上侦听来自 Prometheus 的请求以抓取指标。它从第三方系统或应用程序中收集指标,并将其转换为普罗米修斯可以理解的格式。然后,导出器通过 HTTP 端点将这些指标公开给 Prometheus,使其可用于收集和分析。
导出器通常用于监视各种类型的基础结构组件,例如数据库、Web 服务器和存储系统。例如,有导出器可用于监视流行的数据库,如MySQL和PostgreSQL,以及像Apache和Nginx这样的Web服务器。
总体而言,出口商是 Prometheus 生态系统的关键组成部分,允许监控广泛的系统和应用程序,并为平台提供高度的灵活性和可扩展性。
哪些普罗米修斯最佳实践?
以下是其中的三个:
1. 仔细标记:仔细且一致的指标标记对于有效的查询和警报至关重要。标签应清晰、简洁,并包含有关指标的所有相关信息。2. 保持指标简单:导出商公开的指标应该简单,并专注于被监控系统的单个方面。这有助于避免混淆,并确保团队的所有成员都可以轻松理解指标。3. 谨慎使用警报:虽然警报是 Prometheus 的一项强大功能,但应谨慎使用,并且仅用于最关键的问题。设置过多警报可能会导致警报疲劳,并导致忽略重要警报。建议仅设置最重要的警报,并根据警报的实际频率随时间调整阈值。如何获取给定时间段内的请求总数?
要使用 Prometheus 获取给定时间段内的请求总数,你可以使用 *sum* 函数和 *rate* 函数。下面是一个示例查询,它将为你提供过去一小时内的请求总数:
sum(rate(http_requests_total[1h])) 在此查询中,http_requests_total是跟踪 HTTP 请求总数的指标的名称,速率函数计算过去一小时的每秒请求速率。然后,sum 函数将所有请求相加,为你提供过去一小时内的请求总数。
你可以通过更改速率函数中的持续时间来调整时间范围。例如,如果你想获取最后一天的请求总数,你可以将函数更改为 rate(http_requests_total[1d])。
普罗米修斯中的 HA 是什么意思?
HA 代表 高可用性。这意味着该系统设计为高度可靠且始终可用,即使遇到故障或其他问题也是如此。在实践中,这通常涉及设置 Prometheus 的多个实例,并确保它们都同步并能够无缝地协同工作。这可以通过各种技术来实现,例如负载平衡、复制和故障转移机制。通过在 Prometheus 中实施 HA,用户可以确保其监控数据始终可用且最新,即使面临硬件或软件故障、网络问题或其他可能导致停机或数据丢失的问题。
如何连接两个指标?
在 Prometheus 中,可以使用 *join()* 函数连接两个指标。*join()* 函数根据两个或多个时间序列的标签值组合它们。它需要两个必需的参数:*on* 和 *table*。on 参数指定要联接的标签 *on*,*table* 参数指定要联接的时间序列。
下面是如何使用 join() 函数联接两个指标的示例:
sum_series(
join(
on(service, instance) request_count_total,
on(service, instance) error_count_total,
)
)
在此示例中,join() 函数根据服务和实例标签值组合request_count_total和error_count_total时序。然后,sum_series() 函数计算结果时间序列的总和
如何编写返回标签值的查询?
若要编写返回 Prometheus 中标签值的查询,可以使用 *label_values* 函数。*label_values* 函数采用两个参数:标签名称和指标名称。
例如,如果你有一个名为 http_requests_total 的指标,其标签名为 method,并且你想要返回方法标签的所有值,则可以使用以下查询:
label_values(http_requests_total, method)
这将返回http_requests_total指标中方法标签的所有值的列表。然后,可以在进一步的查询中使用此列表或筛选数据。
如何以百分比将cpu_user_seconds转换为 CPU 使用率?
要将 *cpu_user_seconds* 转换为百分比的 CPU 使用率,你需要将其除以总运行时间和 CPU 内核数,然后乘以 100。公式如下:
100 * sum(rate(process_cpu_user_seconds_total{job=“<job-name>”}[<time-period>])) by (instance) / (<time-period> * <num-cpu-cores>) 此处是要查询的作业的名称,是要查询的时间范围(例如 5m、1h),是要查询的计算机上的 CPU 内核数。
例如,若要获取在具有 4 个 CPU 内核的计算机上运行的名为 my-job 的作业过去 5 分钟的 CPU 使用率百分比,可以使用以下查询:
100 * sum(rate(process_cpu_user_seconds_total{job="my-job"}[5m])) by (instance) / (5m * 4)
去
Go 编程语言有哪些特点?
- 强静态类型 - 变量的类型不能随时间变化,必须在编译时定义
- 单纯
- 快速编译时间
- 内置并发
- 垃圾收集
- 独立于平台
- 编译为独立二进制文件 - 运行应用所需的任何内容都将编译为一个二进制文件。对于运行时的版本管理非常有用。
Go也有很好的社区。
和 有什么区别?var x int = 2
x := 2
结果是相同的,值为 2 的变量。
我们将变量类型设置为整数,而让 Go 自己找出类型。
var x int = 2
x := 2
是真是假?在 Go 中,我们可以重新声明变量,一旦声明,我们必须使用它。
假。我们不能重新声明变量,但是是的,我们必须使用声明的变量。
你用过哪些 Go 库?
这应该根据你的使用情况回答,但一些示例是:
- FMT - 格式化的 I/O
以下代码块有什么问题?如何解决?func main() {
var x float32 = 13.5
var y int
y = x
}
func main() {
var x float32 = 13.5
var y int
y = x
}
以下代码块尝试将整数 101 转换为字符串,但我们得到的是“e”。为什么?如何解决?package main
import "fmt"
func main() {
var x int = 101
var y string
y = string(x)
fmt.Println(y)
}
package main
import "fmt"
func main() {
var x int = 101
var y string
y = string(x)
fmt.Println(y)
}它查看设置为 101 的 unicode 值,并使用它来将整数转换为字符串。如果你想得到“101”,你应该使用包“strconv”并替换为
y = string(x)
y = strconv.Itoa(x)
以下代码有什么问题?package main
func main() {
var x = 2
var y = 3
const someConst = x + y
}
package main
func main() {
var x = 2
var y = 3
const someConst = x + y
}
Go 中的常量只能使用常量表达式声明。但是,它们的总和是可变的。
x
y
const initializer x + y is not a constant
以下代码块的输出是什么?package main
import "fmt"
const (
x = iota
y = iota
)
const z = iota
func main() {
fmt.Printf("%v\n", x)
fmt.Printf("%v\n", y)
fmt.Printf("%v\n", z)
}
package main
import "fmt"
const (
x = iota
y = iota
)
const z = iota
func main() {
fmt.Printf("%v\n", x)
fmt.Printf("%v\n", y)
fmt.Printf("%v\n", z)
}Go 的 iota 标识符用于 const 声明中,以简化递增数字的定义。由于它可以在表达式中使用,因此它提供了超越简单枚举的通用性。
在第一个 iota 组中,在第二个组中。
Go Wiki 中的 iota 页面
x
y
z
以下代码块的输出是什么?package main
import "fmt"
const (
_ = iota + 3
x
)
func main() {
fmt.Printf("%v\n", x)
}
package main
import "fmt"
const (
_ = iota + 3
x
)
func main() {
fmt.Printf("%v\n", x)
}由于第一个 iota 是用值 () 声明的,因此下一个 iota 的值为
3
+ 3
4
以下代码块的输出是什么?package main
import (
"fmt"
"sync"
"time"
)
func main() {
var wg sync.WaitGroup
wg.Add(1)
go func() {
time.Sleep(time.Second * 2)
fmt.Println("1")
wg.Done()
}()
go func() {
fmt.Println("2")
}()
wg.Wait()
fmt.Println("3")
}
package main
import (
"fmt"
"sync"
"time"
)
func main() {
var wg sync.WaitGroup
wg.Add(1)
go func() {
time.Sleep(time.Second * 2)
fmt.Println("1")
wg.Done()
}()
go func() {
fmt.Println("2")
}()
wg.Wait()
fmt.Println("3")
}输出: 2 1 3
以下代码块的输出是什么?package main
import (
"fmt"
)
func mod1(a []int) {
for i := range a {
a[i] = 5
}
fmt.Println("1:", a)
}
func mod2(a []int) {
a = append(a, 125) // !
for i := range a {
a[i] = 5
}
fmt.Println("2:", a)
}
func main() {
s1 := []int{1, 2, 3, 4}
mod1(s1)
fmt.Println("1:", s1)
s2 := []int{1, 2, 3, 4}
mod2(s2)
fmt.Println("2:", s2)
}
package main
import (
"fmt"
)
func mod1(a []int) {
for i := range a {
a[i] = 5
}
fmt.Println("1:", a)
}
func mod2(a []int) {
a = append(a, 125) // !
for i := range a {
a[i] = 5
}
fmt.Println("2:", a)
}
func main() {
s1 := []int{1, 2, 3, 4}
mod1(s1)
fmt.Println("1:", s1)
s2 := []int{1, 2, 3, 4}
mod2(s2)
fmt.Println("2:", s2)
}输出:
1 [5 5 5 5]
1 [5 5 5 5]
2 [5 5 5 5 5]
2 [1 2 3 4]
在 is 链接中,当我们使用 时,我们正在将值更改为。但是在 中,创建新切片,我们只更改值,而不是 .
mod1
a[i]
s1
mod2
append
a
s2
以下代码块的输出是什么?package main
import (
"container/heap"
"fmt"
)
// An IntHeap is a min-heap of ints.
type IntHeap []int
func (h IntHeap) Len() int { return len(h) }
func (h IntHeap) Less(i, j int) bool { return h[i] < h[j] }
func (h IntHeap) Swap(i, j int) { h[i], h[j] = h[j], h[i] }
func (h *IntHeap) Push(x interface{}) {
// Push and Pop use pointer receivers because they modify the slice's length,
// not just its contents.
*h = append(*h, x.(int))
}
func (h *IntHeap) Pop() interface{} {
old := *h
n := len(old)
x := old[n-1]
*h = old[0 : n-1]
return x
}
func main() {
h := &IntHeap{4, 8, 3, 6}
heap.Init(h)
heap.Push(h, 7)
fmt.Println((*h)[0])
}
package main
import (
"container/heap"
"fmt"
)
// An IntHeap is a min-heap of ints.
type IntHeap []int
func (h IntHeap) Len() int { return len(h) }
func (h IntHeap) Less(i, j int) bool { return h[i] < h[j] }
func (h IntHeap) Swap(i, j int) { h[i], h[j] = h[j], h[i] }
func (h *IntHeap) Push(x interface{}) {
// Push and Pop use pointer receivers because they modify the slice's length,
// not just its contents.
*h = append(*h, x.(int))
}
func (h *IntHeap) Pop() interface{} {
old := *h
n := len(old)
x := old[n-1]
*h = old[0 : n-1]
return x
}
func main() {
h := &IntHeap{4, 8, 3, 6}
heap.Init(h)
heap.Push(h, 7)
fmt.Println((*h)[0])
}输出: 3
蒙戈
MongoDB的优势是什么?或者换句话说,为什么选择MongoDB而不是NoSQL的其他实现?
MongoDB的优势如下:
- 无架构
- 易于横向扩展
- 没有复杂的联接
- 单个对象的结构清晰
SQL和NoSQL有什么区别?
主要区别在于SQL数据库是结构化的(数据以带有行和列的表的形式存储 - 就像excel电子表格表一样),而NoSQL是非结构化的,数据存储可以根据NoSQL DB的设置方式而变化,例如键值对,面向文档等。
在什么情况下,你更喜欢使用 NoSQL/Mongo 而不是 SQL?
- 经常变化的异构数据
- 数据一致性和完整性不是重中之重
- 数据库需要快速扩展时的最佳选择
什么是文档?什么是集合?
- 文档是MongoDB中的记录,它以BSON(二进制JSON)格式存储,是MongoDB中数据的基本单位。
- 集合是存储在MongoDB中单个数据库中的一组相关文档。
什么是聚合器?
- 聚合器是MongoDB中的一个框架,它对一组数据执行操作以返回单个计算结果。
什么更好?嵌入文档还是引用?
- 没有明确的答案哪个更好,这取决于具体的用例和要求。一些解释:嵌入式文档提供原子更新,而引用文档允许更好的规范化。
你是否在 Mongo 中执行过数据检索优化?如果没有,你能想到优化慢速数据检索的方法吗?
- 在MongoDB中优化数据检索的一些方法是:索引,正确的模式设计,查询优化和数据库负载平衡。
查询
解释此查询:db.books.find({"name": /abc/})
解释此查询:db.books.find().sort({x:1})
find() 和 find_one() 有什么区别?
-
find()
返回与查询条件匹配的所有文档。 - find_one() 仅返回一个与查询条件匹配的文档(如果未找到匹配项,则返回 null)。
如何从 Mongo 数据库导出数据?
- 蒙古出口
- 编程语言
.SQL
SQL 练习
| 名字 | 主题 | 目标和说明 | 溶液 | 评论 |
|---|---|---|---|---|
| 函数与比较 | 查询改进 | 锻炼 | 溶液 |
SQL 自我评估
什么是 SQL?
SQL(结构化查询语言)是关系数据库(如MySQL,MariaDB等)的标准语言。
它用于读取、更新、删除和创建关系数据库中的数据。
SQL与NoSQL有何不同
主要区别在于SQL数据库是结构化的(数据以带有行和列的表的形式存储 - 就像excel电子表格表一样),而NoSQL是非结构化的,数据存储可以根据NoSQL DB的设置方式而变化,例如键值对,面向文档等。
什么时候最好使用 SQL?NoSQL?
SQL - 最适合在数据完整性至关重要时使用。SQL通常在金融领域的许多业务和领域实施,因为它符合ACID标准。
NoSQL - 如果你需要快速扩展,那就太好了。NoSQL在设计时考虑了Web应用程序,因此如果你需要将相同的信息快速传播到多个服务器,它非常有用。
此外,由于 NoSQL 不遵守关系数据库所需的具有列和行结构的严格表,因此你可以将不同的数据类型存储在一起。
实用 SQL - 基础知识
对于这些问题,我们将使用如下所示的客户和订单表:
客户
| Customer_ID | Customer_Name | Items_in_cart | Cash_spent_to_Date |
|---|---|---|---|
| 100204 | 约翰·史密斯 | 0 | 20.00 |
| 100205 | 简·史密斯 | 3 | 40.00 |
| 100206 | 鲍比·弗兰克 | 1 | 100.20 |
订单
| Customer_ID | Order_ID | 项目 | 价格 | Date_sold |
|---|---|---|---|---|
| 100206 | A123 | 橡皮鸭 | 2.20 | 2019-09-18 |
| 100206 | A123 | 泡泡浴 | 8.00 | 2019-09-18 |
| 100206 | Q987 | 80 包 TP | 90.00 | 2019-09-20 |
| 100205 | Z001 | 猫粮 - 金枪鱼 | 10.00 | 2019-08-05 |
| 100205 | Z001 | 猫粮 - 鸡肉 | 10.00 | 2019-08-05 |
| 100205 | Z001 | 猫粮 - 牛肉 | 10.00 | 2019-08-05 |
| 100205 | Z001 | 猫粮 - 小猫玉米饼 | 10.00 | 2019-08-05 |
| 100204 | X202 | 咖啡 | 20.00 | 2019-04-29 |
如何从此表中选择所有字段?
从客户中选择 *
;
约翰的购物车里有多少件商品?
从Customer_Name
=“约翰·史密斯”的客户中选择Items_in_cart;
所有客户花费的所有现金的总和是多少?
选择 SUM(Cash_spent_to_Date) 作为客户的SUM_CASH
;
有多少人的购物车中有商品?
选择 count(1) 作为 Number_of_People_w_items 来自客户
,其中Items_in_cart > 0;
如何将客户表连接到订单表?
你将在唯一键上加入它们。在这种情况下,唯一键同时Customer_ID在“客户”表和“订单”表中
你将如何显示哪个客户订购了哪些商品?
选择 c.Customer_Name, o.来自客户的项目
c
左 加入订单 o
在 c.Customer_ID = o.Customer_ID;
使用 with 语句,你将如何显示谁订购了猫粮以及花费的总金额?
cat_food为 ( 选择 Customer_ID, 总和(价格) 作为 TOTAL_PRICE 从订单
中 像“%猫粮%”
这样的项目按Customer_ID分组
)
选择Customer_name,TOTAL_PRICE
来自客户 c
内部连接 cat_food f
在 c.Customer_ID = f.Customer_ID c.Customer_ID
的地方(从cat_food中选择Customer_ID);
尽管这是一个简单的语句,但当复杂查询需要在连接到另一个表之前在表上运行时,“with”子句确实大放异彩。with 语句很好,因为你在运行查询时会创建一个伪临时值,而不是创建一个全新的表。
所有购买的猫粮的总和并不容易获得,因此我们使用 with 语句创建伪表来检索每个客户花费的价格总和,然后正常联接表。
你将使用以下哪个查询?SELECT count(*) SELECT count(*)
FROM shawarma_purchases FROM shawarma_purchases
WHERE vs. WHERE
YEAR(purchased_at) == '2017' purchased_at >= '2017-01-01' AND
purchased_at <= '2017-31-12'
SELECT count(*) SELECT count(*)
FROM shawarma_purchases FROM shawarma_purchases
WHERE vs. WHERE
YEAR(purchased_at) == '2017' purchased_at >= '2017-01-01' AND
purchased_at <= '2017-31-12'
SELECT count(*) FROM shawarma_purchases WHERE purchased_at >= '2017-01-01' AND purchased_at <= '2017-31-12'
当你使用函数()时,它必须扫描整个数据库,而不是使用索引和基本上是列,处于其自然状态。
YEAR(purchased_at)
开放堆栈
你熟悉OpenStack的哪些组件/项目?
你能告诉我以下每个服务/项目负责什么吗?
- 新星
- 中子
- 煤渣
- 一目了然
- 重点
- Nova - 管理虚拟实例
- Neutron - 通过提供网络即服务 (NaaS) 来管理网络
- 煤渣 - 块存储
- 概览 - 管理虚拟机和容器的映像(搜索、获取和注册)
- 梯形 - 跨云的身份验证服务
确定用于以下各项的服务/项目:
- 复制或快照实例
- 用于查看和修改资源的 GUI
- 块存储
- 管理虚拟实例
- 概览 - 影像服务。也用于复制或快照实例
- 地平线 - 用于查看和修改资源的 GUI
- 煤渣 - 块存储
- Nova - 管理虚拟实例
什么是租户/项目?
确定真假:
- OpenStack是免费使用的
- 负责联网的服务是Glance
- 租户/项目的目的是在不同项目和OpenStack用户之间共享资源
详细描述如何使用浮动 IP 启动实例
你接到客户的电话,说:“我可以 ping 我的实例,但无法连接 (ssh)它”。可能有什么问题?
OpenStack支持哪些类型的网络?
如何调试OpenStack存储问题?(工具、日志等)
如何调试 OpenStack 计算问题?(工具、日志等)
OpenStack Deployment & TripleO
你过去是否部署过OpenStack?如果是,你能描述一下你是怎么做到的吗?
开放堆栈计算
你能详细描述一下新星吗?
- 用于预置和管理虚拟实例
- 它支持不同级别的多租户 - 日志记录、最终用户控制、审计等。
- 高度可扩展
- 可以使用内部系统或LDAP进行身份验证
- 支持多种类型的块存储
- 尝试与硬件和虚拟机管理程序无关
你对 Nova 架构和组件了解多少?
- nova-API - 提供元数据和计算API的服务器
- 不同的 Nova 组件通过使用队列(通常是 Rabbitmq)和数据库进行通信
- 创建实例的请求由 nova-scheduler 检查,该调度程序确定实例的创建和运行位置
- nova-compute 是负责与虚拟机管理程序通信以创建实例并管理其生命周期的组件
OpenStack Networking (Neutron)
详细解释中子
- OpenStack的核心组件之一,也是一个独立的项目
- Neutron专注于提供网络即服务
- 使用Neutron,用户可以在云中设置网络,并配置和管理各种网络服务
- 中子与以下物质相互作用:
- 梯形失真 - 授权 API 调用
- 新星 - 新星与中子通信以将NIC插入网络
- Horizon - 支持 dashboard 中的网络实体,并提供包含网络详细信息的拓扑视图
解释以下每个组件:
- 中子-dhcp-试剂
- 中子-l3-试剂
- 中子计量剂
- 中子-*-中子
- 中子服务器
- Neutron-L3-agent - L3/NAT 转发(例如,为 VM 提供外部网络访问)
- Neutron-dhcp-agent - DHCP 服务
- 中子计量剂 - L3流量计量
- Neutron-*-agtent - 管理每个计算上的本地交换机配置(基于所选插件)
- Neutron-server - 公开网络 API 并在需要时将请求传递给其他插件
解释这些网络类型:
- 管理网络
- 访客网络
- 原料药网络
- 外部网络
- 管理网络 - 用于OpenStack组件之间的内部通信。此网络中的任何 IP 地址只能在数据中心内访问
- 访客网络 - 用于实例/虚拟机之间的通信
- API 网络 - 用于服务 API 通信。此网络中的任何 IP 地址都可以公开访问
- 外部网络 - 用于公共通信。互联网上的任何人都可以访问此网络中的任何IP地址
应按什么顺序删除以下实体:
- 网络
- Port
- 路由器
- 子
- Port
- 子
- 路由器
- 网络
造成这种情况的原因有很多。例如:如果分配了活动端口,则无法删除路由器。
什么是提供商网络?
L2 和 L3 存在哪些组件和服务?
什么是 ML2 插件?解释其体系结构
什么是 L2 代理?它是如何工作的,它负责什么?
什么是 L3 代理?它是如何工作的,它负责什么?
解释元数据代理负责的内容
Neutron支持哪些网络实体?
如何调试OpenStack网络问题?(工具、日志等)
OpenStack - 概览
详细解释一瞥
- Glance是OpenStack图像服务
- 它处理与实例磁盘和映像相关的请求
- Glance 还用于为快速实例备份创建快照
- 用户可以使用 Glance 创建新图像或上传现有图像
描述概览体系结构
- glance-API - 负责处理图像 API 调用,例如检索和存储。它由两个 API 组成:1. 注册表 API - 负责内部请求 2.用户 API - 可以公开访问
- glance-registry - 负责处理图像元数据请求(例如大小、类型等)。此组件是私有的,这意味着它不公开可用
- 元数据定义服务 - 用于自定义元数据的 API
- 数据库 - 用于存储图像元数据
- 映像存储库 - 用于存储映像。这可以是文件系统,快速对象存储,HTTP等。
OpenStack - Swift
详细解释 Swift
- Swift 是对象存储服务,是一种高度可用、分布式且一致的存储,旨在存储大量数据
- Swift 将数据分布在多个服务器上,同时将其写入多个磁盘
- 可以选择添加其他服务器来扩展群集。同时快速维护信息和数据复制的完整性。
默认情况下,用户可以存储大小为 100GB 的对象吗?
不是默认的。对象存储 API 将每个对象的最大限制为 5GB,但可以进行调整。
解释以下关于 Swift 的内容:
- 容器
- 帐户
- 对象
- 容器 - 定义对象的命名空间。
- 帐户 - 为容器定义命名空间
- 对象 - 数据内容(例如图像、文档等)
是真是假?同一容器中可以有两个同名的对象,但不能在两个不同的容器中
假。如果两个对象位于不同的容器中,则可以具有相同的名称。
OpenStack - Cinder
详细解释煤渣
- Cinder是OpenStack块存储服务
- 它基本上提供了与其他服务(如Nova)一起使用的存储资源。
- Cinder支持的最常用的存储实现之一是LVM
- 从用户的角度来看,这是透明的,这意味着用户不知道存储的位置,在幕后,存储的位置或使用什么类型的存储
描述煤渣的组件
- cinder-API - 接收 API 请求
- 煤渣卷 - 管理连接的块设备
- 煤渣调度程序 - 负责存储卷
OpenStack - Keystone
你能描述一下关于Keystone的以下概念吗?
- 角色
- 租户/项目
- 服务
- 端点
- 令 牌
- 角色 - 确定用户或项目可以执行的操作的权限和特权列表
- 租户/项目 - 与其他资源组隔离的一组资源的逻辑表示形式。它可以是一个帐户,组织,...
- 服务 - 用户可用于访问不同资源的端点
- 端点 - 可用于访问某个OpenStack服务的网络地址
- 令牌 - 用于访问资源,同时描述可以使用作用域访问哪些资源
服务的属性是什么?换句话说,如何识别服务?
用:
- 名字
- 身份证号码
- 类型
- 描述
解释以下内容: - 公共网址 - 内部网址 - 管理网址
- 公共网址 - 通过公共互联网公开访问
- 内部网址 - 用于服务之间的通信
- 管理员网址 - 用于管理管理
什么是服务目录?
服务及其终结点的列表
OpenStack Advanced - Services
描述以下各项服务
- 迅速
- 撒哈拉沙漠
- 讽刺
- 宝库
- 奥德
- 云高仪
- Swift - 高度可用、分布式、最终一致的对象/blob 存储
- 撒哈拉 - 管理 Hadoop 集群
- 具有讽刺意味 - 裸机配置
- Trove - 在OpenStack上运行的数据库即服务
- 奥德 - 报警服务
- 云高计 - 跟踪和监控使用情况
确定用于以下各项的服务/项目:
- 在OpenStack上运行的数据库即服务
- 裸机配置
- 跟踪和监控使用情况
- 报警服务
- 管理 Hadoop 集群
- 高度可用、分布式、最终一致的对象/blob 存储
- 在OpenStack上运行的数据库即服务 - Trove
- 裸机配置 - 具有讽刺意味
- 跟踪和监控使用情况 - 云高仪
- 报警服务 - 奥德
- 管理 Hadoop 集群
- 管理 Hadoop 集群 - 撒哈拉沙漠
- 高度可用、分布式、最终一致的对象/blob 存储 - Swift
OpenStack Advanced - Keystone
你能详细描述一下鼎石服务吗?
- 如果没有Keystone,就无法部署OpenStack。
- 它提供身份、策略和令牌服务
- 提供的身份验证适用于用户和服务
- 支持的授权是基于令牌和基于用户的。
- 有一个基于存储在 JSON 文件中的 RBAC 定义的策略,该文件中的每一行都定义了要应用的访问级别
描述梯形架构
- 有一个服务API和管理API,Keystone通过它获取请求
- Keystone 有四个后端:
- 令牌后端 - 用户和服务的临时令牌
- 策略后端 - 规则管理和授权
- 身份后端 - 用户和组(独立数据库、LDAP 等)
- 目录后端 - 终结点
- 它具有可插拔的环境,你可以在其中与以下环境集成:
- 目录
- KVS(键值存储)
- .SQL
- 帕姆
- 内存缓存
描述梯形失真身份验证过程
- Keystone 收到一个电话/请求,并使用用户名、密码和 authURL 检查它是否来自授权用户
- 一旦确认,Keystone将提供一个令牌。
- 令牌包含用户项目的列表,因此每次都无需进行身份验证,可以提交令牌
OpenStack Advanced - Compute (Nova)
以下各项的作用是什么?
- 新星-api
- 新星计算
- 新星导体
- 新星证书
- nova-consoleauth
- nova-scheduler
- nova-api - 负责管理请求/调用
- nova-compute - 负责管理实例生命周期
- nova-conductor - 在nova-compute和数据库之间进行调解,因此nova-compute不会直接访问它
你熟悉哪些类型的新星代理?
- Nova-novncproxy - 通过 VNC 连接访问
- Nova-spicehtml5proxy - 通过 SPICE 访问
- Nova-xvpvncproxy - 通过 VNC 连接访问
OpenStack Advanced - Networking (Neutron)
BGP 动态路由简介
网络命名空间在OpenStack中的角色是什么?
OpenStack Advanced - Horizon
你能详细描述一下地平线吗?
- 基于 Django 的项目,专注于提供 OpenStack dashboard 和创建其他自定义 dashboard 的能力
- 你可以使用它来访问不同的OpenStack服务资源 - 实例,映像,网络,...
- 通过访问 dashboard ,用户可以使用它来列出、创建、删除和修改不同的资源
- 它也是高度可定制的,你可以根据需要修改或添加它
你能对地平线架构说些什么?
- API 向后兼容
- 有三种类型的 dashboard :用户、系统和设置
- 它为所有OpenStack核心项目提供核心支持,如Neutron,Nova等。(开箱即用,无需安装额外的软件包或插件)
- 任何人都可以扩展 dashboard 并添加新组件
- Horizon 提供了模板和核心类,从中可以构建自己的 dashboard
木偶
什么是木偶?它是如何工作的?
- Puppet是一种配置管理工具,可确保所有系统都配置为所需和可预测的状态。
解释木偶建筑
- Puppet具有主-辅助节点架构。客户端分布在网络中,并与存在 Puppet 模块的主-辅助环境进行通信。客户端代理将带有其 ID 的证书发送到服务器;然后,服务器对该证书进行签名并将其发送回客户端。此身份验证允许客户端和主服务器之间进行安全且可验证的通信。
你能将Puppet与其他配置管理工具进行比较吗?你为什么选择使用Puppet?
- Puppet经常与其他配置管理工具(如Chef,Ansible,SaltStack和cfengine)进行比较。选择使用 Puppet 通常取决于组织的需求,例如易用性、可扩展性和社区支持。
解释以下内容:
- 模块
- 清单
- 节点
- 模块 - 是清单、模板和文件的集合
- 清单 - 是用于配置客户端的实际代码
- 节点 - 允许你将特定配置分配给特定节点
解释事实
- Facter 是 Puppet 中的一个独立工具,用于收集有关系统及其配置的信息,例如操作系统、IP 地址、内存和网络接口。此信息可用于 Puppet 清单中,以决定应如何管理资源,并根据系统的特征自定义 Puppet 的行为。Facter 被集成到 Puppet 中,其事实可以在 Puppet 清单中用于做出有关资源管理的决策。
什么是MCollective?
- MCollective 是一个中间件系统,它与 Puppet 集成,提供编排、远程执行和并行作业执行功能。
你有编写模块的经验吗?你创建了哪个模块,用于什么?
解释什么是希拉
- Hiera 是 Puppet 中的分层数据存储,用于将数据与代码分离,从而更轻松地分离、管理和重用数据。
弹性的
什么是弹性堆栈?
弹性堆栈包括:
- 弹性搜索
- 木花
- 日志存储
- 打
- 弹性Hadoop
- APM 服务器
Elasticsearch,Logstash和Kibana也被称为ELK堆栈。
解释什么是 Elasticsearch
来自官方文档:
“Elasticsearch是一个分布式文档存储。Elasticsearch 不是将信息存储为列式数据行,而是存储已序列化为 JSON 文档的复杂数据结构”
解释什么是节拍
Beats 是轻量级的数据发送器。这些数据发送器安装在数据所在的客户端上。节拍示例:Filebeat、Metricbeat、Auditbeat。还有更多。
什么是木花?
来自官方文档:
“Kibana 是一个开源分析和可视化平台,旨在与 Elasticsearch 配合使用。你可以使用 Kibana 来搜索、查看存储在 Elasticsearch 索引中的数据并与之交互。你可以轻松执行高级数据分析,并在各种图表、表格和 map中可视化数据。
描述从应用记录某些信息到使用 Elastic 堆栈时在控制面板中向用户显示信息为止会发生什么情况
该过程可能因所选体系结构和你可能希望应用于日志的处理而有所不同。一种可能的工作流程是:
- 应用程序记录的数据由 filebeat 选取并发送到 logstash
- 日志存储根据定义的筛选器处理日志。完成后,输出将发送到Elasticsearch。
- Elasticsearch 存储它获得的文档,并将文档编入索引,以便将来快速访问
- 用户在 Kibana 中创建基于索引数据的可视化
- 用户创建一个 dashboard ,该 dashboard 由上一步中创建的可视化组成
弹性搜索
什么是数据节点?
这是存储数据的地方,也是进行不同处理的地方(例如,当你搜索数据时)。
什么是主节点?
部分主节点责任:
- 跟踪群集中所有节点的状态
- 验证副本是否正常工作,以及数据是否可从每个数据节点获得。
- 没有热节点(没有比其他节点工作更努力的数据节点)
虽然实际上可以有多个主节点,但其中只有选择的主节点。
什么是采集节点?
负责根据摄取管道处理数据的节点。如果你不需要使用 logstash,那么这个节点可以从 beats 接收数据并处理它,类似于在 Logstash 中处理它的方式。
什么是仅协调节点?
来自官方文档:
仅协调节点可以通过从数据和符合主节点条件的节点中卸载协调节点角色,使大型集群受益。它们加入群集并接收完整的群集状态(与其他节点一样),并且使用群集状态将请求直接路由到适当的位置。
数据是如何存储在 Elasticsearch 中的?
- 数据存储在索引中
- 索引使用分片分布在集群中
什么是指数?
在大多数情况下,Elasticsearch 中的索引与 SQL/NoSQL 世界中的整个数据库进行比较。
你可以选择使用一个索引来保存应用的所有数据,也可以选择使用多个索引,其中每个索引包含不同类型的应用(例如,应用正在运行的每个服务的索引)。
官方文档也提供了一个很好的解释(一般来说,这是非常好的文档,因为每个项目都应该有):
“索引可以被认为是文档的优化集合,每个文档都是字段的集合,字段是包含数据的键值对”
解释分片
索引被拆分为分片,文档被散列到特定的分片。每个分片可能位于集群中的不同节点上,并且每个分片都是一个独立的索引。
这允许 Elasticsearch 扩展到整个服务器集群。
什么是倒排指数?
来自官方文档:
“倒排索引列出了任何文档中出现的每个唯一单词,并标识每个单词出现的所有文档。”
什么是文档?
继续与SQL/NoSQL进行比较,Elasticsearch中的文档在SQL的情况下是表中的一行,对于NoSQL来说,是集合中的文档。与NoSQL一样,文档是一个JSON对象,它将数据保存在应用程序中的一个单元上。此单位是什么取决于你的应用。如果你的应用与图书相关,则每个文档都会描述一本书。如果你的应用程序是关于衬衫的,那么每个文档都是一件衬衫。
你检查 elasticsearch 集群的运行状况,它是红色的。什么意思?什么会导致状态为黄色而不是绿色?
红色表示某些数据在群集中不可用。索引的某些分片是未确定的。群集还有其他一些状态。黄色表示集群中有未分配的分片。如果你有单个节点并且索引具有副本,则可以处于此状态。绿色表示集群中的所有分片都分配给节点,并且你的集群运行正常。
是真是假?Elasticsearch 索引每个字段中的所有数据,每个索引字段具有相同的数据结构,以实现统一和快速的查询能力
假。来自官方文档:
“每个索引字段都有一个专用的、优化的数据结构。例如,文本字段存储在倒排索引中,数值和地理字段存储在 BKD 树中。
文档具有哪些保留字段?
- _指数
- _id
- _类型
解释映射
定义自己的映射有哪些优势?(或者:你什么时候使用自己的映射?
- 你可以优化字段以进行部分匹配
- 你可以定义已知字段的自定义格式(例如日期)
- 你可以执行特定于语言的分析
解释副本
在随时可能发生故障的网络/云环境中,如果分片/节点以某种方式脱机或因任何原因消失,则使用故障转移机制非常有用,强烈建议使用。为此,Elasticsearch 允许你将索引分片的一个或多个副本创建为所谓的副本分片,或简称副本。
你能解释一下术语频率和文档频率吗?
术语频率是术语在给定文档中出现的频率,文档频率是术语在所有文档中出现的频率。它们都用于通过计算术语频率/文档频率来确定术语的相关性。
此命令的作用是什么?curl -X PUT "localhost:9200/customer/_doc/1?pretty" -H 'Content-Type: application/json' -d'{ "name": "John Doe" }'
如果不存在,它会创建客户索引,并添加一个字段名称设置为“John Dow”的新文档。此外,如果它是第一个文档,它将获得 ID 1。
如果运行上一个命令两次会发生什么?运行 100 次怎么样?
- 如果名称值不同,则它将“名称”更新为新值
- 无论如何,它将版本字段增加了一个
什么是批量 API?你会用它来做什么?
当你需要为多个文档编制索引时,将使用批量 API。对于大量文档,使用比单个请求要快得多,因为网络往返较少。
查询 DSL
解释 Elasticsearch 查询语法(布尔值、字段、范围)
解释什么是相关性分数
解释查询上下文和筛选上下文
来自官方文档:
“在查询上下文中,查询子句回答了以下问题:”此文档与此查询子句的匹配程度如何?除了确定文档是否匹配之外,查询子句还计算_score元字段中的相关性分数。
“在筛选器上下文中,查询子句回答问题”此文档是否与此查询子句匹配?答案是简单的是或否 - 不计算分数。过滤上下文主要用于过滤结构化数据”
描述具有大量数据的生产环境的体系结构与小规模环境的区别
这个问题有几种可能的答案。其中之一如下:
弹性的小规模架构将由弹性堆栈组成。这意味着我们将拥有 beats、logstash、elastcsearch 和 kibana。
具有大量数据的生产环境可以包括某种缓冲组件(例如Reddis或RabbitMQ)以及安全组件(例如Nginx)。
日志存储
什么是 Logstash 插件?有哪些插件类型?
- 输入插件 - 如何从不同来源收集数据
- 过滤器插件 - 处理数据
- 输出插件 - 将数据推送到不同的输出/服务/平台
什么是格罗克?
一个日志插件,它以一种格式修改信息并将其沉浸在另一种格式中。
格罗克是如何工作的?
你熟悉哪些格洛克模式?
什么是“_grokparsefailure”?
如何测试或调试 grok 模式?
什么是 Logstash 编解码器?有哪些编解码器?
木花
在 Kibana 的“发现”下可以找到什么?
存储在索引中的原始数据。你可以搜索和过滤它。
在 Kibana 中,单击“发现”后,你会看到“561 次点击”。什么意思?
与搜索结果匹配的文档总数。如果未使用查询,则只需文档总数。
你可以在“可视化”下找到什么?
“可视化”是你可以为数据创建可视化表示的地方(饼图、图形等)
Kibana 支持/包含哪些可视化类型?
你将对统计异常值使用哪种可视化类型
详细描述如何在 Kibana 中创建 dashboard
文件节拍
什么是文件节拍?
如果使用的是 ELK,是否也必须使用 filebeat?在什么情况下使用文件节拍很有用?
是真是假?单个收割机根据 Filebeat.yml 中设置的限制收获多个文件
假。一台收割机收获一个锉刀。
什么是文件节拍模块?
弹性堆栈
如何保护弹性堆栈?
你可以使用提供的弹性实用程序生成证书,并更改配置以使用证书模型启用安全性。
分散式
解释分布式计算(或分布式系统)
根据Martin Kleppmann的说法:
“许多进程在许多机器上运行...只有通过具有可变延迟的不可靠网络传递消息,系统可能会遭受部分故障、不可靠的时钟和进程暂停。
另一个定义:“物理上分离但逻辑连接的系统”
什么会导致系统故障?
- 网络
- 中央处理器
- 记忆
- 磁盘
你知道什么是“CAP定理”吗?(又名布鲁尔定理)
根据 CAP 定理,分布式数据存储不可能同时提供以下两个以上的数据:
- 可用性:每个请求都会收到响应(不一定是最新数据)
- 一致性:每个请求都会收到包含最新/最新数据的响应
- 分区容错:即使某些数据丢失/丢弃,系统也会继续运行
以下设计存在哪些问题?如何改进?
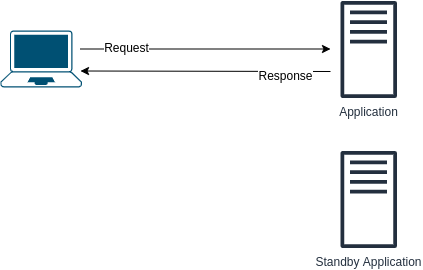

1. 过渡可能需要时间。换句话说,明显的停机时间。2. 备用服务器是资源浪费 - 如果第一个应用程序服务器正在运行,那么备用服务器什么都不做
以下设计存在哪些问题?如何改进?
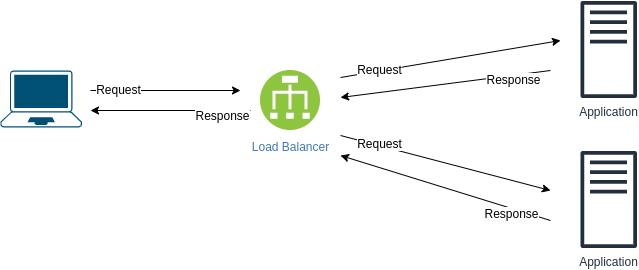

问题:如果负载均衡器死亡,我们将失去与应用程序通信的能力。
改进方法:
- 添加另一个负载均衡器
- 对两个负载均衡器使用 DNS A 记录
- 使用消息队列
什么是“无共享”架构?
它是一种架构,其中数据是从单个非共享源检索的,通常专门连接到一个节点,而不是请求可以到达许多节点之一并且数据将从一个共享位置检索的架构(存储、内存等)。
解释挎斗模式(或挎斗代理)
杂项
| 名字 | 主题 | 目标和说明 | 溶液 | 评论 |
|---|---|---|---|---|
| 高可用性“Hello World” | 锻炼 | 溶液 |
在浏览器的地址栏中键入 URL 时会发生什么情况?
- 浏览器按以下顺序在DNS中搜索域名IP地址的记录:
- 浏览器缓存
- 操作系统缓存
- 在用户系统上配置的 DNS 服务器(可以是 ISP DNS、公共 DNS 等)
- 如果在本地找不到 DNS 记录,则会启动完整的 DNS 解析。
- 它使用 TCP 协议连接到服务器
- 浏览器向服务器发送 HTTP 请求
- 服务器将 HTTP 响应发送回浏览器
- 浏览器呈现响应(例如.HTML)
- 然后,浏览器根据需要向服务器发送后续请求,以获取HTML中的嵌入式链接,javascript,图像,然后重复步骤3至5。
待办事项:添加更多详细信息!
应用程序接口
解释什么是 API
我喜欢 blog.christianposta.com 的这个定义:
“一个明确且有目的的接口,旨在通过网络调用,使软件开发人员能够以受控和舒适的方式以编程方式访问组织内的数据和功能。
是真是假?API 定义与 API 规范相同
假。从 swagger.io:
“API 定义类似于 API 规范,因为它提供了对 API 组织方式和 API 功能的理解。但 API 定义针对的是机器消费,而不是人类对 API 的消费。
什么是 API 网关?
API 网关就像守门人,控制不同部分如何相互通信以及它们之间如何交换信息。
API 网关为所有客户端提供单一入口点,它可以执行多项任务,包括将请求路由到相应的后端服务、负载平衡、安全性和身份验证、速率限制、缓存和监控。
通过使用 API 网关,组织可以简化其 API 的管理,确保一致的安全性和治理,并提高其后端服务的性能和可扩展性。它们也常用于微服务架构,其中有许多小型的独立服务需要由不同的客户端访问。
使用/实施 API 网关有哪些优势?
优势:
- 简化 API 管理:为所有请求提供单一入口点,简化多个 API 的管理和监控。
- 提高安全性:能够实现身份验证、授权和加密等安全功能,以保护后端服务免受未经授权的访问。
- 增强可扩展性:可以处理流量高峰并将请求分发到后端服务,从而最大限度地提高资源利用率并提高整体系统性能。
- 启用服务组合:可以将不同的后端服务合并到单个 API 中,从而对客户端可以访问的服务进行更精细的控制。
- 促进与外部系统的集成:可用于向外部合作伙伴或客户公开内部服务,使其更容易与外部系统集成并启用新的业务模型。
什么是 API 中的有效负载?
什么是自动化?它与业务流程有何关联或不同?
自动化是自动化任务的行为,以减少与IT技术和系统有关的人为干预或交互。
虽然自动化侧重于任务级别,但编排是自动化流程和/或工作流的过程,它由通常跨多个系统的多个任务组成。
告诉我你发现并修复的有趣错误
什么是调试器及其工作原理?
应用程序可能具有哪些服务?
- 授权
- 伐木
- 认证
- 订购
- 前端
- 后端...
什么是元数据?
有关数据的数据。基本上,它描述了基础数据将包含的信息类型。
你可以使用以下格式之一:JSON、YAML、XML。你会使用哪一个?为什么?
我无法为你回答这个问题:)
什么是关键绩效指标?
什么是OKR?
什么是DSL(域特定语言)?
领域特定语言 (DSL) 用于创建表示领域的自定义语言,以便领域专家可以轻松解释它。
KPI 和 OKR 之间有什么区别?
亚姆
什么是 YAML?
当今许多技术(如Kubernetes,Ansible等)使用的数据序列化语言。
是真是假?任何有效的 JSON 文件也是有效的 YAML 文件
真。因为 YAML 是 JSON 的超集。
以下数据的格式是什么?{
applications: [
{
name: "my_app",
language: "python",
version: 20.17
}
]
}
{
applications: [
{
name: "my_app",
language: "python",
version: 20.17
}
]
}
杰伦
以下数据的格式是什么?applications:
- app: "my_app"
language: "python"
version: 20.17
applications:
- app: "my_app"
language: "python"
version: 20.17
亚姆
如何使用 YAML 编写多行字符串?它适用于哪些用例?
someMultiLineString: | look mama I can write a multi-line string I love YAML
它适用于编写 shell 脚本等用例,其中脚本的每一行都是不同的命令。
有什么区别?someMultiLineString: |
someMultiLineString: >
使用将使多行字符串折叠成单行
>
someMultiLineString: > This is actually a single line do not let appearances fool you
什么是 YAML 中的占位符?
它们允许你引用值而不是直接写入它们,它的用法如下:
username: {{ my.user_name }}
如何在一个文件中定义多个 YAML 组件?
使用这个: 例如:
---
document_number: 1 --- document_number: 2
固件
解释什么是固件
维基百科:“在计算中,固件是一类特定的计算机软件,它为设备的特定硬件提供低级控制。固件,例如个人计算机的BIOS可以包含设备的基本功能,并且可以为操作系统等更高级的软件提供硬件抽象服务。
卡珊德拉
运行 Cassandra 集群时,你需要多久运行一次 nodetool repair 才能保持集群的一致性?
- 在列内家庭GC恩典每周一次
- 小于压缩分区的最小字节数
- 取决于压实策略
HTTP
描述 HTTP 请求生命周期
- 通过请求将主机解析为 DNS 解析程序
- 客户端同步
- 服务器同步+确认
- 客户端同步
- HTTP请求
- HTTP响应
是真是假?HTTP 是有状态的
假。它不维护传入请求的状态。
HTTP 请求是什么样的?
它包括:
- 请求行 - 请求类型
- 标题 - 内容信息,如长度、连接等。
- 正文(并不总是包括在内)
有哪些 HTTP 方法类型?
- 获取
- 发布
- 头
- 放
- 删除
- 连接
- 选项
- 跟踪
有哪些 HTTP 响应代码?
- 1xx - 信息
- 2xx - 成功
- 3xx - 重定向
- 4xx - 错误,客户端故障
- 5xx - 错误,服务器故障
什么是HTTPS?
HTTPS 是 HTTP 协议的安全版本,用于在 Web 浏览器和 Web 服务器之间传输数据。它使用 SSL/TLS 加密对通信进行加密,以确保数据的私密性和安全性。
了解更多: https://www.cloudflare.com/learning/ssl/why-is-http-not-secure/
解释 HTTP 饼干
HTTP 是无状态的。为了共享状态,我们可以使用 Cookie。
TODO:解释什么是真正的 Cookie
什么是 HTTP 流水线?
你收到来自 HTTP 服务器的“504 网关超时”错误。什么意思?
服务器未及时收到来自与其通信的另一台服务器的响应。
什么是代理?
代理是充当客户端设备和目标服务器之间的中间人的服务器。它可以通过隐藏客户端的 IP 地址、筛选内容和缓存经常访问的数据来帮助提高隐私、安全性和性能。
- 代理可用于负载平衡,在多个服务器之间分配流量,以帮助防止服务器过载并提高网站或应用程序性能。它们还可用于数据分析,因为它们可以记录请求和流量,从而提供有关用户行为和偏好的有用见解。
什么是反向代理?
反向代理是一种位于客户端和服务器之间的代理服务器,但它用于管理与传统正向代理相反方向的流量。在转发代理中,客户端将请求发送到代理服务器,然后代理服务器将这些请求转发到目标服务器。但是,在反向代理中,客户端将请求发送到目标服务器,但请求在到达服务器之前被反向代理截获。
- 它们通常用于提高 Web 服务器性能、提供高可用性和容错能力,并通过阻止直接访问后端服务器来增强安全性。它们通常用于大型 Web 应用程序和高流量网站,以管理和分发请求到多个服务器,从而提高可扩展性和可靠性。
发布项目时,通常使用许可证发布项目。你熟悉哪些类型的许可证,你更喜欢使用哪一种?
解释什么是“X转发”
维基百科:“X-Forwarded-For (XFF) HTTP 标头字段是一种常用方法,用于识别通过 HTTP 代理或负载均衡器连接到 Web 服务器的客户端的原始 IP 地址。
负载均衡器
什么是负载均衡器?
负载均衡器接受(或拒绝)来自客户端的传入网络流量,并根据某些条件(应用程序相关、网络等)将这些通信分发到服务器(至少一个)。
为什么要使用负载均衡器?
- 可伸缩性 - 使用负载均衡器,你可以在后端添加更多服务器来处理来自客户端的更多请求/流量,而不是使用一台服务器。
- 冗余 - 如果后端的一台服务器死亡,负载均衡器将继续将流量/请求转发到第二台服务器,因此用户甚至不会注意到后端的其中一台服务器已关闭。
你熟悉哪些负载均衡器技术/算法?
- 循环赛
- 加权循环赛
- 最少连接
- 加权最小连接
- 基于资源
- 固定权重
- 加权响应时间
- 源 IP 哈希
- 网址哈希
负载均衡中循环算法有哪些缺点?
- 简单的轮循机制算法对将请求转发到的每个服务器的负载和规范一无所知。有可能,多个繁重的工作负载请求将到达同一台服务器,而其他服务器将只获得轻量级请求,这将导致一台服务器完成大部分工作,甚至可能在某个时候崩溃,因为它无法自行处理所有繁重的工作负载请求。
- 来自客户端的每个请求都会创建一个全新的会话。对于某些想要执行多个操作的情况,这可能是一个问题,其中服务器必须知道操作的结果,因此基本上,要知道它与客户端的历史记录。在轮循机制中,第一个请求可能会命中服务器 X,而第二个请求可能会命中服务器 Y,并要求继续处理已在服务器 X 上处理的数据。
什么是应用程序负载均衡器?
在哪些情况下会使用 ALB?
负载均衡器可以在哪些层运行?
L4 和 L7
是否可以在不使用专用负载均衡器实例的情况下执行负载均衡?
是的,你可以使用 DNS 执行负载平衡。
什么是 DNS 负载平衡?它有什么优点?你什么时候会使用它?
负载均衡器 - 粘性会话
命名一个使用粘性会话的用例
你希望确保用户不会丢失当前会话数据。
粘性会话使用什么来启用“粘性”?
饼干。有基于应用程序的 Cookie 和基于持续时间的 Cookie。
解释基于应用程序的 Cookie
- 由应用程序和/或负载均衡器生成
- 通常允许包含自定义数据
解释基于持续时间的 Cookie
- 由负载均衡器生成
- 持续时间过后,会话不再粘滞
负载均衡器 - 负载平衡算法
解释以下每种负载平衡技术
- 循环赛
- 加权循环赛
- 最少连接
- 加权最小连接
- 基于资源
- 固定权重
- 加权响应时间
- 源 IP 哈希
- 网址哈希
解释连接耗尽的用例?
要确保 Classic 负载均衡器停止向取消注册或运行状况不佳的实例发送请求,同时保持现有连接处于打开状态,请使用连接耗尽。这使负载均衡器能够完成对正在取消注册或不正常的实例发出的正在进行的请求。
在 GCP 和 AWS 上,最大超时值可以设置为 1 到 3600 秒。
许可证
你熟悉“知识共享”吗?你对此了解多少?
知识共享许可是一组版权许可,允许创作者与公众分享他们的作品,同时保留对如何使用作品的一些控制权。该许可的开发是为了回应传统版权法的限制性标准,这些标准限制了创意作品的获取。其创作者选择其作品可以被他人共享、分发和使用的条款。它们是六种主要类型的知识共享许可证,每种许可证都有不同级别的限制和权限,这六个许可证是:
- 署名(CC BY):允许其他人分发、重新混音和构建作品,即使是商业上的,只要他们归功于原始创作者。
- 署名-相同方式共享(CC BY-SA):允许其他人重新混合和构建作品,即使是商业上的,只要他们注明原创作者并在同一许可下发布任何新创作。
- 署名-无衍生物(CC BY-ND):允许其他人分发作品,即使是商业性的,但他们不能以任何方式重新混合或更改它,并且必须注明原创作者。
- 署名-非商业性(CC BY-NC):允许其他人重新混合和构建作品,但他们不能将其用于商业用途,并且必须注明原创作者。
- 署名-非商业性使用-相同方式共享(CC BY-NC-SA):允许其他人对作品进行混音和构建,但他们不能将其用于商业用途,必须注明原创作者,并且必须在同一许可下发布任何新创作。
- 署名-非商业性-禁止派生(CC BY-NC-ND):允许他人下载和分享作品,但不能将其用于商业用途,以任何方式重新混合或更改作品,并且必须注明原创作者。
简单地说,知识共享许可是创作者与公众分享其作品的一种方式,同时保留对如何使用作品的一些控制权。这些许可促进创造力、创新和协作,同时也尊重创作者的权利,同时仍然鼓励负责任地使用创意作品。
解释 copyleft 许可证和宽松许可证之间的区别
在 Copyleft 中,任何衍生作品都必须使用相同的许可,而在宽松许可中则没有这样的条件。GPL-3 是 copyleft 许可证的一个例子,而 BSD 是宽松许可证的一个例子。
随机
搜索引擎如何工作?
自动完成功能如何工作?
什么是内存泄漏?
内存泄漏是当程序无法释放不再需要的内存时发生的编程错误,导致程序随着时间的推移消耗越来越多的内存。
泄漏可能导致各种问题,包括系统崩溃、性能下降和不稳定。通常在旧系统维护失败以及与新组件的兼容性之后发生。
你最喜欢的协议是什么?
SSH HTTP DHCP DNS ...
什么是缓存 API?
存储
有哪些类型的存储?
- 文件
- 块
- 对象
解释对象存储
- 数据被划分为自包含对象
- 对象可以包含元数据
对象存储的优缺点是什么?
优点:
- 通常,对于对象存储,你需要为使用的内容付费,而其他存储类型则需要为分配的存储空间付费
- 可扩展存储:对象存储主要基于一个模型,在该模型中,你使用的就是你获得的,你可以根据需要添加存储 缺点:
- 通常执行速度比其他类型的存储慢
- 无粒度修改:要更改对象,你必须重新创建它
使用对象存储有哪些用例?
解释文件存储
- 文件存储,用于在分层结构中存储文件中的数据
- 一些用于文件存储的设备:硬盘驱动器,闪存驱动器,基于云的文件存储
- 文件通常组织在目录中
文件存储的优缺点是什么?
优点:
- 用户可以完全控制自己的文件,并且可以对文件运行各种操作:删除、读取、写入和移动。
- 安全机制允许用户更好地控制文件锁定等内容
文件存储有哪些示例?
本地文件系统 Dropbox Google Drive
有哪些类型的存储设备?
IOPS 解释
解释存储吞吐量
什么是文件系统?
文件系统是计算机和其他电子设备组织和存储数据文件的一种方式。它提供了一种结构,有助于将数据组织到文件和目录中,从而更轻松地查找和管理信息。文件系统对于提供以有组织的方式存储和管理数据的方法至关重要。
常用的归档系统: 视窗:
- NTFS
- 前法特
苹果操作系统:
- HFS+ *APFS
解释暗数据
解释 MBR
你可以问的问题
作为候选人,你可以在面试期间或之后向面试官提出的问题清单。这些只是一个建议,请谨慎使用。不是每个面试官都能回答(或乐于回答)这些问题,这也许是对你在这样的地方工作的危险信号警告,但这真的取决于你。
你喜欢在这里工作的什么?
公司如何促进个人成长?
你目前正在处理的技术债务水平是多少?
问这个问题时要小心——所有公司,无论规模大小,都有一定程度的技术债务。根据所有公司都处理这个问题来表达这个问题,但你希望看到他们正在处理的当前痛点
这是了解经理如何处理计划外工作的好方法,以及他们在设定项目期望方面的表现。
为什么我不应该加入你?(或者“你不喜欢在这里工作什么?
你最喜欢做过什么项目?
这可以让你深入了解公司正在从事的一些很酷的项目,如果你喜欢从事此类项目。这也是查看经理是否允许员工在正常工作之外的项目中学习和成长的好方法。
如果你可以改变日常的一件事,那会是什么?
与技术债务问题类似,这可以帮助你确定公司的任何痛点。此外,这可能是展示你将如何成为团队资产的好方法。
例如,如果他们提到他们有问题X,而你过去已经解决了这个问题,你可以展示你如何能够缓解这个问题。
假设我们同意并且你雇用我担任这个职位,X 个月后,你期望我取得什么成就?
这不仅会告诉你对你的期望,它还会为你在工作的头几个月要做的工作类型提供很大的提示。
测试
解释白盒测试
解释黑盒测试
什么是单元测试?
单元测试是一种软件测试技术,涉及系统分解系统并测试程序集的每个单独部分。这些测试是自动化的,可以重复运行,使开发人员能够在开发时快速捕获边缘情况或错误。
单元测试的主要目标是验证每个函数在给定一组输入的情况下是否产生正确的输出。
你将运行哪些类型的测试来测试 Web 应用程序?
解释测试工具?
什么是 A/B 测试?
什么是网络仿真,你如何执行它?
你熟悉哪些类型的性能测试?
解释以下类型的测试:
- 负载测试
- 压力测试
- 容量测试
- 批量测试
- 耐久性测试
正则表达式
给定一个文本文件,执行以下练习
提取
提取所有数字
- “\d+”
提取每行的第一个单词
-
“^\w+” 奖励:提取每行的最后一个单词
-
“\w+(?=\W*$)”(在大多数情况下,取决于行格式)
提取所有 IP 地址
- “\b(?:\d{1,3}\ .){3}\d{1,3}\b“ IPV4:(此格式查找 1 到 3 位数字序列 3 次)
以 yyyy-mm-dd 或 yyyy-dd-mm 格式提取日期
提取电子邮件地址
- “\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\ .[A-Za-z]{2,}\b”
取代
将制表符替换为四个空格
将“红色”改为“绿色”
系统设计
解释什么是“单点故障”?
什么是 CDN?
CDN(内容交付网络)负责按地理位置分发内容。其中一部分是所谓的边缘站点,又名缓存代理,由于缓存功能和地理分布,它允许用户快速获取内容。
解释多 CDN
在单个 CDN 中,整个内容源自内容分发网络。
在多 CDN 中,内容分布在多个不同的 CDN 中,每个 CDN 可能位于完全不同的提供商/云上。
与单个 CDN 相比,多 CDN 有哪些优势?
- 弹性:依赖一个 CDN 意味着没有冗余。使用多个 CDN,你无需担心 CDN 会关闭
- 成本灵活性:使用一个 CDN 会强制你使用该 CDN 的特定速率。对于多个 CDN,你可以考虑使用较便宜的 CDN 来交付内容。
- 性能:使用多CDN,选择更好的位置具有更大的潜力,这些位置更靠近询问内容的客户端
- 缩放:使用多个 CDN,可以扩展服务以支持更极端的条件
解释“3 层架构”(包括优缺点)
解释单存储库与多存储库。每种方法的优缺点是什么?
单片架构的缺点是什么?
- 不适合频繁的代码更改和部署新功能的能力
- 不是为当今的基础架构(如公共云)而设计的
- 扩展团队以使用整体式架构更具挑战性
与整体架构相比,微服务架构有哪些优势?
- 每个服务单独失败,而不会升级为应用程序范围的中断。
- 每个服务都可以由一个单独的团队开发和维护,这个团队可以选择自己的工具和编码语言
解释“松耦合”
什么是消息队列?什么时候使用?
可扩展性
解释可扩展性
该功能可根据需求和使用情况轻松增加大小和容量。
解释弹性
增长的能力,但也根据需要减少
解释灾难恢复
灾难恢复是在发生破坏性事件后恢复关键业务系统和数据的过程。目标是将影响降至最低并快速恢复正常的业务活动。这包括创建计划、测试计划、备份关键数据并将其存储在安全位置。在发生灾难时,将执行计划,恢复备份,并希望使系统重新联机。恢复过程可能需要数小时或数天,具体取决于基础设施的损坏情况。这使得业务规划变得非常重要,因为精心设计和测试的灾难恢复计划可以最大限度地减少灾难的影响并保持运营。
解释容错和高可用性
容错 - 自我修复并恢复正常能力的能力。还具有承受故障并保持功能的能力。
高可用性 - 能够访问资源(在某些用例中,使用不同的平台)
高可用性和灾难恢复之间有什么区别?
wintellect.com:“简单地说,高可用性就是消除单点故障,而灾难恢复是在系统无法运行时使系统恢复到运行状态的过程。从本质上讲,当高可用性失败时,灾难恢复就会开始,所以首先是HA。
解释垂直缩放
垂直扩展是添加资源以增加现有服务器功能的过程。例如,添加更多 CPU、添加更多 RAM 等。
垂直缩放的缺点是什么?
仅通过垂直缩放,组件仍然是单点故障。此外,它还具有硬件限制,如果你没有更多资源,则可能无法垂直扩展。
哪种类型的云服务通常支持垂直扩展?
数据库,缓存。这主要适用于非分布式系统。
解释水平缩放
水平扩展是添加更多资源的过程,这些资源将能够作为一个单元处理请求
水平缩放的缺点是什么?执行水平缩放通常需要什么?
负载均衡器。你可以添加更多资源,但如果你希望它们成为流程的一部分,则必须为他们提供请求/响应。此外,数据不一致是水平扩展的一个问题。
说明你将在哪些用例中使用垂直扩展,以及在哪些用例中使用水平扩展
解释弹性以及有哪些方法可以使系统更具弹性
解释“一致哈希”
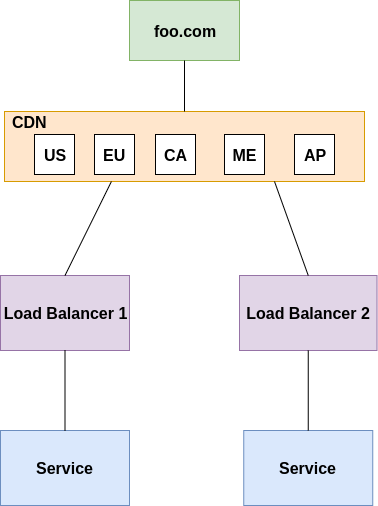
如何在不造成应用 (foo.com) 停机的情况下更新下图中的每个服务?

以下架构有什么问题,你将如何解决它?
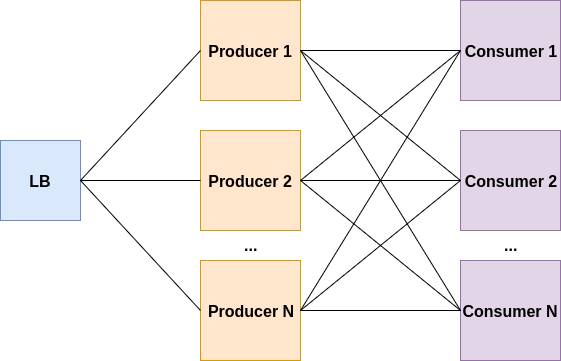

生产者或消费者的负载可能很高,这将导致它们挂起或崩溃。
消费者只有在准备好处理任务时才能拉取任务,而不是在“推送模式”下工作。它可以通过使用Kafka,Kinesis等流媒体平台来修复。该平台将确保处理高负载/流量,并仅在准备好获取任务/消息时才将任务/消息传递给消费者。

用户报告说,当添加更多数据作为输入进行处理时,处理时间会大幅增加。可能有什么问题?
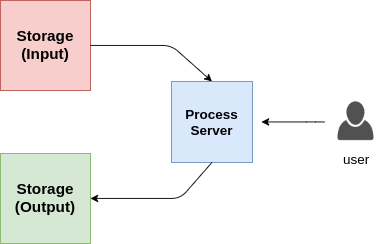

如何将架构从上一个问题扩展到数百个用户?
缓存
什么是“缓存”?在哪些情况下你会使用它?
什么是“分布式缓存”?
为什么不将所有内容写入缓存而不是数据库/数据存储?
缓存和数据库有不同的用途,并针对不同的用例进行了优化。
缓存用于通过将频繁访问的数据存储在内存或快速存储介质上来加快读取操作。通过使数据靠近应用程序,缓存可以减少从较慢、更远的存储系统(如数据库或磁盘)访问数据的延迟和开销。
另一方面,数据库针对存储和管理持久性数据进行了优化。数据库旨在处理并发读写操作,强制实施一致性和完整性约束,并提供索引和查询等功能。
迁移
如何准备迁移?(或计划迁移)
你可以提及:
回滚和前滚剪切彩排 DNS 重定向
解释“抽象分支”技术
设计系统
你能设计一个视频流媒体网站吗?
你能设计一个照片上传网站吗?
你将如何构建 URL 缩短器?
更多系统设计问题
其他练习可以在系统设计笔记本存储库中找到。

硬件
什么是中央处理器?
中央处理器 (CPU) 执行程序中指令指定的基本算术、逻辑、控制和输入/输出 (I/O) 操作。这与主存储器和 I/O 电路等外部组件以及图形处理单元 (GPU) 等专用处理器形成鲜明对比。
什么是内存?
RAM(随机存取存储器)是计算设备中的硬件,其中保存了操作系统 (OS)、应用程序和当前使用的数据,以便设备的处理器可以快速访问它们。RAM 是计算机中的主存储器。它的读取和写入速度比其他类型的存储(如硬盘驱动器 (HDD)、固态驱动器 (SSD) 或光盘驱动器)快得多。
什么是 GPU?
什么是嵌入式系统?
嵌入式系统是一种计算机系统,由计算机处理器、计算机内存和输入/输出外围设备组成,在较大的机械或电子系统中具有专用功能。它作为完整设备的一部分嵌入,通常包括电气或电子硬件和机械部件。
你能举一个嵌入式系统的例子吗?
树莓派
有哪些类型的存储?
有几种类型的存储,包括硬盘驱动器 (HDD)、固态驱动器 (SSD) 和光盘驱动器 (CD/DVD/蓝光)。其他类型的存储包括 USB 闪存驱动器、存储卡和网络连接存储 (NAS)。
DevOps 团队在为其工作选择硬件时应牢记哪些注意事项?
硬件在灾难恢复规划和实施中的作用是什么?
什么是突袭?
什么是微控制器?
什么是网络接口控制器或网卡?
大数据
解释什么是大数据
正如道格·莱尼(Doug Laney)所定义的那样:
- 数据量:数据量极大
- 速度:实时、批处理、数据流
- 多样性:各种形式的数据,结构化,半结构化和非结构化
- 准确性或可变性:不一致、有时不准确、变化的数据
什么是数据运营?它与DevOps有什么关系?
DataOps 旨在缩短数据分析的端到端周期时间,从想法的起源到创造价值的图表、图形和模型的字面创建。DataOps 结合了敏捷开发、DevOps 和统计流程控制,并将其应用于数据分析。
解释不同格式的数据
- 结构化 - 已定义格式和长度的数据(例如数字、单词)
- 半结构化 - 不符合特定格式,但具有自我描述性(例如.XML SWIFT)
- 非结构化 - 不遵循特定格式(例如图像、测试消息)
你能解释一下数据湖和数据仓库之间的区别吗?
什么是“数据版本控制”?有哪些模型的“数据版本控制”?
什么是 ETL?
Apache Hadoop
解释Hadoop YARN
负责管理集群中的计算资源和调度用户的应用程序
解释Hadoop MapReduce
用于大规模数据处理的编程模型
解释 Hadoop 分布式文件系统 (HDFS)
- 分布式文件系统,提供跨集群的高聚合带宽。
- 对于用户来说,它看起来像一个常规的文件系统结构,但在幕后它分布在集群中的多台机器上。
- 典型的文件大小为 TB,它可以扩展并支持数百万个文件
- 它具有容错能力,这意味着它可以从故障中自动恢复
- 它最适合运行长时间的批处理操作,而不是实时分析
头孢
解释什么是 Ceph
是真是假?Ceph 偏爱一致性和正确性,而不是性能
真
Ceph 支持哪些服务或存储类型?
- 对象 (RGW)
- 块(RBD)
- 文件 (CephFS)
什么是雷达表?
- 可靠的自主分布式对象存储
- 提供低级数据对象存储服务
- 一致性强
- 简化更高层(块、文件、对象)的设计和实现
描述雷达表软件组件
- 监控
- 用于身份验证、数据放置、策略的中央机构
- 所有其他集群组件的协调点
- 使用 Paxos 保护关键集群状态
- 经理
- 聚合实时指标(吞吐量、磁盘使用情况等)
- 用于可插拔管理功能的主机
- 每个集群 1 个活动,1+ 个备用
- OSD(对象存储守护程序)
- Stores data on an HDD or SSD
- Services client IO requests
从 Ceph 检索数据的工作流程是什么?
从 Ceph 检索数据的工作流程是什么?
什么是“归置组”?
详细描述以下内容:对象 ->池 ->归置组 -> OSD
什么是 OMAP?
什么是元数据服务器?它是如何工作的?
包装者
什么是包装机?它的用途是什么?
通常,Packer会自动创建机器映像。它允许你在创建映像时专注于部署之前的配置。在大多数情况下,这使你可以更快地启动实例。
Packer follows a "configuration->deployment" model or "deployment->configuration"?
具有以下优点的配置>部署:
- 部署速度 - 在部署之前配置一次,而不是每次部署时都配置。这使你可以更快地启动实例/服务。
- 更不可变的基础结构 - 使用配置>部署,不太可能有非常不同的部署,因为大多数配置都是在部署之前完成的。在此模型中部署之前,将处理/发现依赖项错误等问题。
释放
解释语义版本控制
本页完美地解释了它:
Given a version number MAJOR.MINOR.PATCH, increment the: MAJOR version when you make incompatible API changes MINOR version when you add functionality in a backwards compatible manner PATCH version when you make backwards compatible bug fixes Additional labels for pre-release and build metadata are available as extensions to the MAJOR.MINOR.PATCH format.
证书
如果你正在寻找一种准备某种考试的方法,那么本节就是适合你的部分。在这里,你将找到证书列表,每个证书都引用一个单独的文件,其中包含重点问题,可帮助你准备考试。祝你好运:)
自主技术
天蓝色
- AZ-900(最新更新:2021)
Kubernetes
- 认证 Kubernetes 管理员 (CKA)(最新更新:2022 年)
其他开发运营和 SRE 项目




捐赠
感谢我们所有出色的贡献者,他们让每个人都可以轻松学习新事物:)
徽标信用可以在这里找到
许可证
About
