system-design - 了解如何大规模设计系统并准备系统设计面试
系统设计
嘿,欢迎来到课程。我希望这门课程能提供很好的学习体验。
本课程也可以在我的网站上找到,也可以作为 leanpub 上的电子书获得。如果这有帮助,请留下一个⭐作为动力!
目录
-
开始
-
第一章
-
第二章
-
第三章
-
第四章
-
第五章
-
附录
什么是系统设计?
在开始本课程之前,让我们先谈谈什么是系统设计。
系统设计是为满足特定要求的系统定义体系结构、接口和数据的过程。系统设计通过连贯而高效的系统满足你的业务或组织的需求。它需要一种系统的方法来构建和工程系统。一个好的系统设计需要我们考虑一切,从基础设施一直到数据及其存储方式。
为什么系统设计如此重要?
系统设计帮助我们定义满足业务需求的解决方案。这是我们在构建系统时可以做出的最早的决定之一。通常,必须从高层次思考,因为这些决定以后很难纠正。随着系统的发展,它还可以更轻松地推理和管理架构更改。
知识产权
IP 地址是标识 Internet 或本地网络上设备的唯一地址。IP 代表“互联网协议”,它是管理通过互联网或本地网络发送的数据格式的一组规则。
从本质上讲,IP 地址是允许在网络上的设备之间发送信息的标识符。它们包含位置信息,并使设备可供通信。互联网需要一种方法来区分不同的计算机、路由器和网站。IP 地址提供了一种执行此操作的方法,并构成了互联网工作方式的重要组成部分。
版本
现在,让我们了解不同版本的 IP 地址:
IPv4的
最初的互联网协议是 IPv4,它使用 32 位数字点十进制表示法,只允许大约 40 亿个 IP 地址。最初,这已经绰绰有余,但随着互联网采用率的增长,我们需要更好的东西。
示例:102.22.192.181
IPv6的
IPv6 是 1998 年推出的一种新协议。部署始于 2000 年代中期,由于互联网用户呈指数级增长,因此仍在进行中。
这个新协议使用 128 位字母数字十六进制表示法。这意味着 IPv6 可以提供大约 ~340e+36 个 IP 地址。这足以满足未来几年不断增长的需求。
示例:2001:0db8:85a3:0000:0000:8a2e:0370:7334
类型
让我们讨论一下 IP 地址的类型:
公共
公共 IP 地址是一个主地址与整个网络关联的地址。在这种类型的 IP 地址中,每个连接的设备都具有相同的 IP 地址。
示例:ISP 提供给路由器的 IP 地址。
私有
私有 IP 地址是分配给连接到你的互联网网络的每台设备的唯一 IP 号码,其中包括你家庭中使用的计算机、平板电脑和智能手机等设备。
示例:家庭路由器为设备生成的 IP 地址。
静态的
静态 IP 地址不会更改,并且是手动创建的,而不是已分配的。这些地址通常更昂贵,但更可靠。
示例:它们通常用于重要的事情,例如可靠的地理位置服务、远程访问、服务器托管等。
动态
动态 IP 地址会不时更改,并且并不总是相同的。它已由动态主机配置协议 (DHCP) 服务器分配。动态 IP 地址是最常见的 Internet 协议地址类型。它们的部署成本更低,并允许我们根据需要在网络中重复使用 IP 地址。
示例:它们更常用于消费类设备和个人使用。
OSI 模型
OSI 模型是一个逻辑和概念模型,用于定义开放互连和与其他系统通信的系统使用的网络通信。开放系统互连(OSI 模型)还定义了一个逻辑网络,并通过使用各种协议层有效地描述了计算机数据包传输。
OSI模型可以看作是计算机网络的通用语言。它基于将通信系统分成七个抽象层的概念,每个层堆叠在最后一个层上。
为什么 OSI 模型很重要?
开放系统互连 (OSI) 模型定义了网络讨论和文档中使用的通用术语。这使我们能够拆解一个非常复杂的通信过程并评估其组成部分。
虽然这个模型没有直接在当今最常见的 TCP/IP 网络中实现,但它仍然可以帮助我们做更多的事情,例如:
- 更轻松地进行故障排除,并帮助识别整个堆栈中的威胁。
- 鼓励硬件制造商创建可以通过网络相互通信的网络产品。
- 对于培养安全第一的思维方式至关重要。
- 将复杂的功能分离为更简单的组件。
层
OSI 模型的七个抽象层可以按如下方式定义,从上到下:
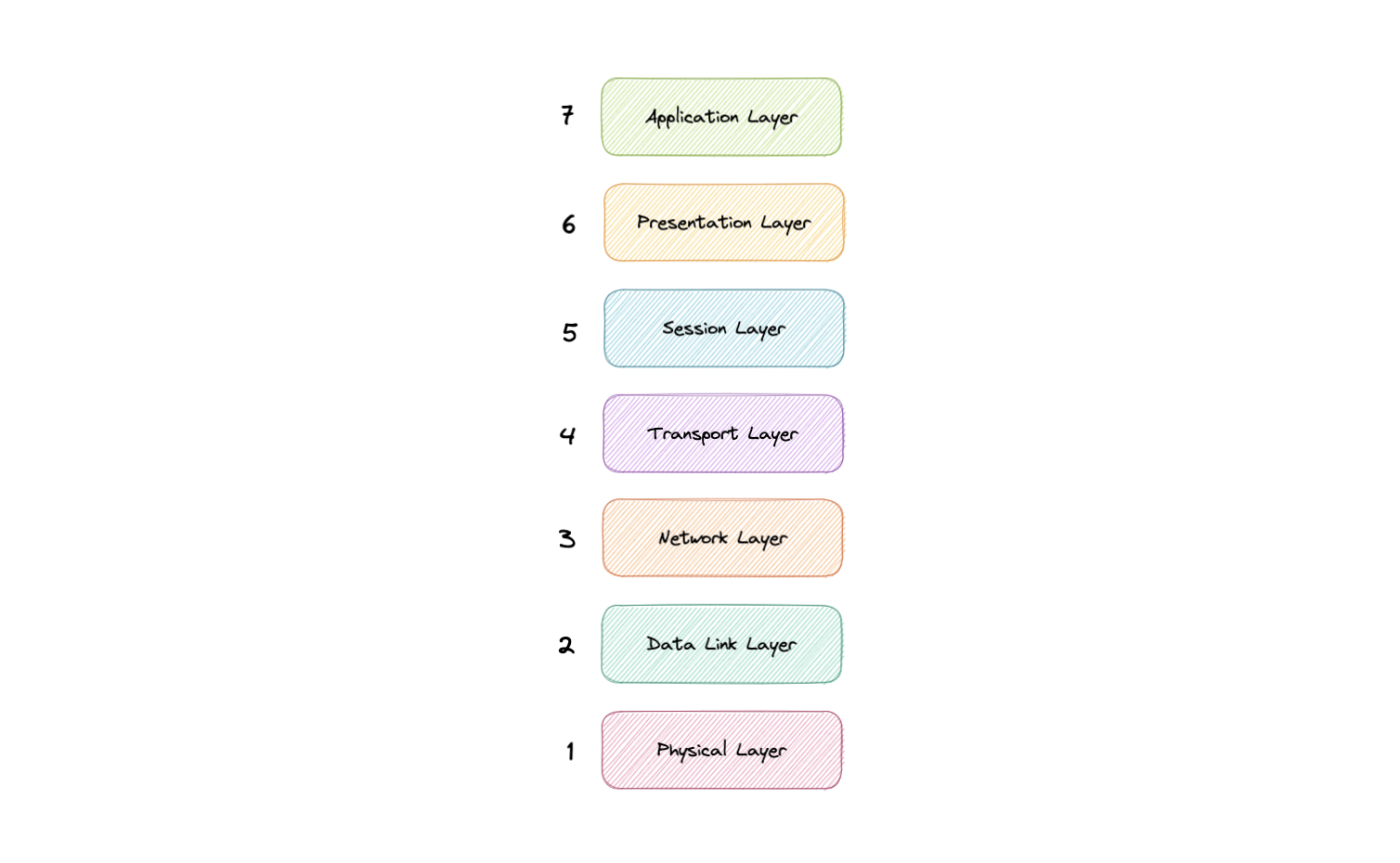
应用
这是唯一直接与来自用户的数据交互的层。Web 浏览器和电子邮件客户端等软件应用程序依赖于应用层来启动通信。但应该明确的是,客户端软件应用程序不是应用层的一部分,而是应用层负责软件所依赖的协议和数据操作,以便向用户呈现有意义的数据。应用层协议包括 HTTP 和 SMTP。
介绍
表示层也称为翻译层。来自应用层的数据在这里被提取出来,并按照通过网络传输所需的格式进行操作。表示层的功能是翻译、加密/解密和压缩。
会期
这是负责打开和关闭两个设备之间的通信的层。打开和关闭通信之间的时间称为会话。会话层确保会话保持打开足够长的时间以传输正在交换的所有数据,然后立即关闭会话以避免浪费资源。会话层还与检查点同步数据传输。
运输
传输层(也称为第 4 层)负责两个设备之间的端到端通信。这包括从会话层获取数据并将其分解为称为段的块,然后再将其发送到网络层(第 3 层)。它还负责将接收设备上的段重新组合为会话层可以使用的数据。
网络
网络层负责促进两个不同网络之间的数据传输。网络层在发送方的设备上将传输层的段分解为更小的单元(称为数据包),并在接收设备上重新组合这些数据包。网络层还为数据找到到达目的地的最佳物理路径,这称为路由。如果通信的两个设备位于同一网络上,则不需要网络层。
数据链路
数据链路层与网络层非常相似,只是数据链路层促进了同一网络上两个设备之间的数据传输。数据链路层从网络层获取数据包,并将它们分解成更小的部分,称为帧。
物理的
该层包括数据传输中涉及的物理设备,例如电缆和交换机。这也是将数据转换为比特流的层,该比特流是 1 和 0 的字符串。两个器件的物理层还必须就信号约定达成一致,以便可以将两个器件上的 1 与 0 区分开来。
TCP 和 UDP
TCP协议
传输控制协议 (TCP) 是面向连接的,这意味着一旦建立了连接,数据就可以双向传输。TCP 具有内置系统来检查错误并保证数据将按发送顺序传递,使其成为传输静止图像、数据文件和网页等信息的完美协议。
但是,虽然TCP本质上是可靠的,但它的反馈机制也会导致更大的开销,从而更多地使用网络上的可用带宽。
UDP协议
用户数据报协议 (UDP) 是一种更简单的无连接互联网协议,其中不需要错误检查和恢复服务。使用 UDP,打开连接、维护连接或终止连接不会产生开销。数据会持续发送给接收者,无论他们是否收到数据。
它在很大程度上是实时通信(如广播或组播网络传输)的首选。当我们需要最低的延迟并且延迟数据比数据丢失更糟糕时,我们应该使用 UDP over TCP。
TCP 与 UDP
TCP 是面向连接的协议,而 UDP 是无连接协议。TCP 和 UDP 之间的一个关键区别是速度,因为 TCP 比 UDP 慢。总体而言,UDP 是一种更快、更简单、更高效的协议,但是,只有使用 TCP 才能重新传输丢失的数据包。
TCP 提供从用户到服务器的有序数据传递(反之亦然),而 UDP 不专用于端到端通信,也不检查接收方的准备情况。
| 特征 | TCP协议 | UDP协议 |
|---|---|---|
| 连接 | 需要已建立的连接 | 无连接协议 |
| 保证交货 | 可以保证数据的交付 | 无法保证数据的交付 |
| 重传 | 可以重新传输丢失的数据包 | 不会重新传输丢失的数据包 |
| 速度 | 比 UDP 慢 | 比TCP更快 |
| 广播 | 不支持广播 | 支持广播 |
| 使用案例 | HTTPS、HTTP、SMTP、POP、FTP 等 | 视频流、DNS、VoIP等 |
域名系统 (DNS)
之前,我们了解了使每台计算机能够与其他计算机连接的 IP 地址。但正如我们所知,人类对名字比数字更舒服。记住类似的名字比记住类似的名字更容易。
google.com
122.250.192.232
这就把我们带到了域名系统 (DNS),它是一种分层和去中心化的命名系统,用于将人类可读的域名转换为 IP 地址。
DNS 的工作原理

DNS查找包括以下八个步骤:
- 客户端在 Web 浏览器中键入 example.com,查询传输到 Internet 并由 DNS 解析器接收。
- 然后,解析器以递归方式查询 DNS 根名称服务器。
- 根服务器使用顶级域 (TLD) 的地址响应解析器。
- 然后,解析器向 TLD 发出请求。
.com
- 然后,TLD 服务器使用域名称服务器的 IP 地址 example.com 进行响应。
- 最后,递归解析器向域的名称服务器发送查询。
- 然后,example.com 的 IP 地址将从名称服务器返回到解析器。
- 然后,DNS 解析器使用最初请求的域的 IP 地址响应 Web 浏览器。
解析 IP 地址后,客户端应该能够从解析的 IP 地址请求内容。例如,解析的 IP 可能会返回要在浏览器中呈现的网页。
服务器类型
现在,让我们看一下构成 DNS 基础结构的四个关键服务器组。
DNS 解析器
DNS 解析器(也称为 DNS 递归解析器)是 DNS 查询中的第一站。递归解析器充当客户端和 DNS 名称服务器之间的中间人。从 Web 客户端收到 DNS 查询后,递归解析器将使用缓存数据进行响应,或者向根域名服务器发送请求,然后向 TLD 域名服务器发送另一个请求,然后向权威域名服务器发送最后一个请求。在收到来自包含请求的 IP 地址的权威名称服务器的响应后,递归解析器随后向客户端发送响应。
DNS 根服务器
根服务器接受递归解析器的查询,其中包含域名,根域名服务器根据该域的扩展名(、、等)将递归解析器定向到 TLD 域名服务器进行响应。根域名服务器由一家名为互联网名称与数字地址分配机构 (ICANN) 的非营利组织监督。
.com
.net
.org
每个递归解析器已知 13 个 DNS 根域名服务器。请注意,虽然有 13 个根域名服务器,但这并不意味着根域名服务器系统中只有 13 台机器。根域名服务器有 13 种类型,但每种类型在世界各地都有多个副本,它们使用 Anycast 路由来提供快速响应。
TLD 域名服务器
TLD 名称服务器维护共享公共域扩展名的所有域名的信息,例如 、 或 URL 中最后一个点之后的任何内容。
.com
.net
TLD 域名服务器的管理由互联网号码分配机构 (IANA) 负责,该机构是 ICANN 的一个分支机构。IANA 将 TLD 服务器分为两大类:
-
通用顶级域:这些域包括 、 、 、 和 。
.com
.org
.net
.edu
.gov
-
国家/地区代码顶级域名:这些域名包括特定于某个国家或州的任何域名。示例包括 、 、 和 。
.uk
.us
.ru
.jp
权威DNS服务器
权威域名服务器通常是解析器获取 IP 地址的最后一步。权威域名服务器包含特定于其所服务的域名的信息(例如 google.com),它可以为递归解析器提供在 DNS A 记录中找到的该服务器的 IP 地址,或者如果域有 CNAME 记录(别名),它将为递归解析器提供别名域,此时递归解析器必须执行全新的 DNS 查找才能从权威获取记录名称服务器(通常是包含 IP 地址的 A 记录)。如果找不到域,则返回 NXDOMAIN 消息。
查询类型
DNS 系统中有三种类型的查询:
递归的
在递归查询中,DNS 客户端要求 DNS 服务器(通常是 DNS 递归解析程序)将使用请求的资源记录或错误消息(如果解析程序找不到记录)来响应客户端。
迭 代
在迭代查询中,DNS 客户端提供主机名,DNS 解析程序返回它所能返回的最佳答案。如果 DNS 解析程序的缓存中有相关的 DNS 记录,则会返回这些记录。否则,它会将 DNS 客户端引用到根服务器或最接近所需 DNS 区域的其他权威名称服务器。然后,DNS 客户端必须直接对它被引用的 DNS 服务器重复查询。
非递归
非递归查询是 DNS 解析器已经知道答案的查询。它要么立即返回 DNS 记录,因为它已经将其存储在本地缓存中,要么查询对记录具有权威性的 DNS 名称服务器,这意味着它肯定拥有该主机名的正确 IP。在这两种情况下,都不需要额外的查询轮次(如递归查询或迭代查询)。相反,响应会立即返回给客户端。
记录类型
DNS 记录(又称区域文件)是位于权威 DNS 服务器中的指令,提供有关域的信息,包括与该域关联的 IP 地址以及如何处理该域的请求。
这些记录由一系列以所谓的 DNS 语法编写的文本文件组成。DNS 语法只是一串字符,用作指示 DNS 服务器执行操作的命令。所有 DNS 记录还具有“TTL”,它代表生存时间,指示 DNS 服务器刷新该记录的频率。
还有更多的记录类型,但现在,让我们看一些最常用的记录类型:
- A(地址记录):这是保存域 IP 地址的记录。
- AAAA(IP 版本 6 地址记录):包含域的 IPv6 地址的记录(与存储 IPv4 地址的 A 记录相反)。
- CNAME(规范名称记录):将一个域或子域转发到另一个域,不提供 IP 地址。
- MX(邮件交换器记录):将邮件定向到电子邮件服务器。
- TXT(文本记录):此记录允许管理员在记录中存储文本注释。这些记录通常用于电子邮件安全。
- NS(名称服务器记录):存储 DNS 条目的名称服务器。
- SOA(起始授权机构):存储有关域的管理员信息。
- SRV(服务位置记录):指定特定服务的端口。
- PTR(反向查找指针记录):在反向查找中提供域名。
- CERT(证书记录):存储公钥证书。
子域
子域名是我们主域名的附加部分。它通常用于在逻辑上将网站分隔为多个部分。我们可以在主域上创建多个子域或子域。
例如,其中是子域,是主域,是顶级域 (TLD)。类似的示例可以是 或 。
blog.example.com
blog
example
.com
support.example.com
careers.example.com
DNS 区域
DNS 区域是域命名空间的一个独特部分,它被委派给负责维护 DNS 区域的法人实体(如个人、组织或公司)。DNS 区域也是一项管理功能,允许对 DNS 组件(例如权威名称服务器)进行精细控制。
DNS 缓存
DNS缓存(有时称为DNS解析器缓存)是由计算机操作系统维护的临时数据库,其中包含最近访问和尝试访问网站和其他Internet域的所有记录。换句话说,DNS缓存只是最近DNS查找的内存,我们的计算机在想弄清楚如何加载网站时可以快速参考。
域名系统对每条 DNS 记录实施生存时间 (TTL)。TTL 指定 DNS 客户端或服务器可以缓存记录的秒数。当记录存储在缓存中时,它附带的任何 TTL 值也会被存储。服务器继续更新缓存中存储的记录的 TTL,每秒倒计时一次。当它达到零时,记录将被删除或从缓存中清除。此时,如果收到对该记录的查询,则 DNS 服务器必须启动解析过程。
反向 DNS
反向 DNS 查找是对与给定 IP 地址关联的域名的 DNS 查询。这与更常用的正向 DNS 查找相反,在正向 DNS 查找中,查询 DNS 系统以返回 IP 地址。反向解析 IP 地址的过程使用 PTR 记录。如果服务器没有 PTR 记录,则无法解析反向查找。
反向查找通常由电子邮件服务器使用。电子邮件服务器在将电子邮件引入其网络之前,请检查并查看电子邮件是否来自有效的服务器。许多电子邮件服务器会拒绝来自任何不支持反向查找的服务器或来自极不可能合法的服务器的邮件。
注意:反向DNS查找并未被普遍采用,因为它们对互联网的正常功能并不重要。
例子
以下是一些广泛使用的托管 DNS 解决方案:
负载均衡
负载均衡允许我们在多个资源之间分配传入的网络流量,通过仅向联机资源发送请求来确保高可用性和可靠性。这提供了根据需求添加或减少资源的灵活性。
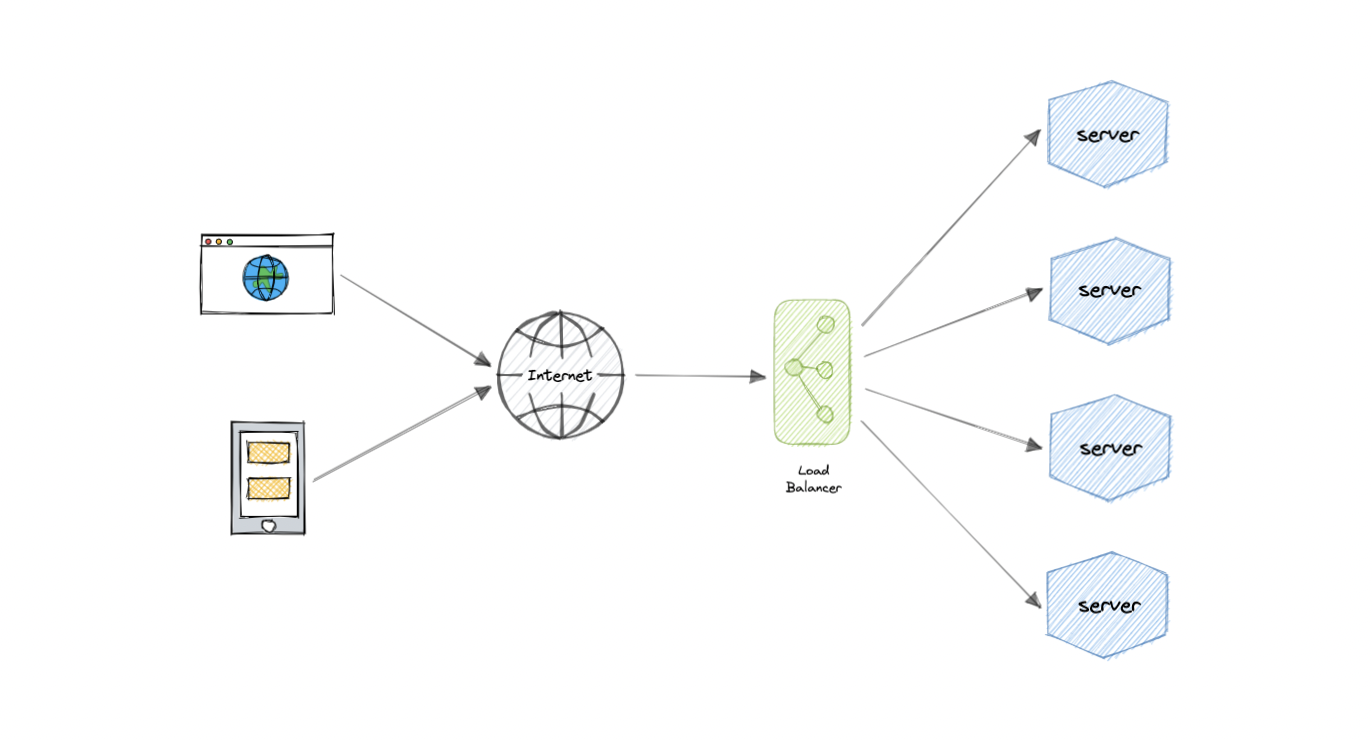
为了获得额外的可扩展性和冗余性,我们可以尝试在系统的每一层进行负载均衡:
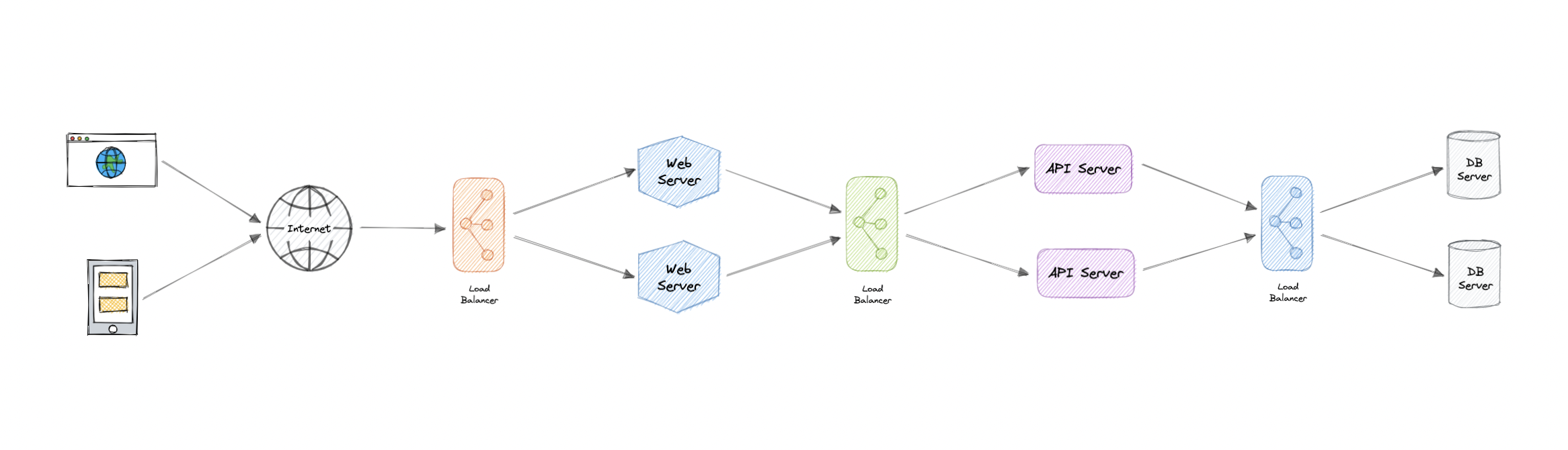
但是为什么?
现代高流量网站必须为来自用户或客户端的数十万甚至数百万个并发请求提供服务。为了经济高效地扩展以满足这些高容量的需求,现代计算最佳实践通常需要添加更多服务器。
负载平衡器可以位于服务器前面,并在能够以最大化速度和容量利用率的方式满足这些请求的所有服务器之间路由客户端请求。这样可以确保不会有单个服务器过度工作,从而降低性能。如果单个服务器出现故障,负载均衡器会将流量重定向到其余联机服务器。将新服务器添加到服务器组时,负载均衡器会自动开始向其发送请求。
工作负载分布
这是负载均衡器提供的核心功能,具有几种常见变体:
- 基于主机:根据请求的主机名分发请求。
- 基于路径:使用整个 URL 来分发请求,而不仅仅是主机名。
- 基于内容:检查请求的消息内容。这允许基于参数值等内容进行分发。
层
一般来说,负载均衡器在以下两个级别之一运行:
网络层
这是在网络传输层(也称为第 4 层)工作的负载平衡器。这将根据 IP 地址等网络信息执行路由,并且无法执行基于内容的路由。这些通常是可以高速运行的专用硬件设备。
应用层
这是在应用程序层(也称为第 7 层)运行的负载均衡器。负载均衡器可以完整读取请求并执行基于内容的路由。这允许在充分了解流量的基础上管理负载。
类型
让我们看一下不同类型的负载均衡器:
软件
软件负载均衡器通常比硬件版本更易于部署。它们也往往更具成本效益和灵活性,并且与软件开发环境结合使用。软件方法使我们能够灵活地根据环境的特定需求配置负载均衡器。灵活性的提高可能是以必须执行更多工作来设置负载均衡器为代价的。与提供更多封闭式方法的硬件版本相比,软件平衡器为我们提供了更多的更改和升级自由。
软件负载均衡器被广泛使用,既可以作为需要配置和管理的可安装解决方案使用,也可以作为托管云服务使用。
硬件
顾名思义,硬件负载平衡器依赖于物理本地硬件来分配应用程序和网络流量。这些设备可以处理大量流量,但通常价格昂贵,并且在灵活性方面相当有限。
硬件负载平衡器包括专有固件,这些固件需要维护和更新为新版本,并发布安全补丁。
DNS解析
DNS 负载平衡是在域名系统 (DNS) 中配置域的做法,以便对域的客户端请求分布在一组服务器计算机上。
不幸的是,DNS负载平衡存在固有的问题,限制了其可靠性和效率。最重要的是,DNS 不会检查服务器和网络中断或错误。它始终为域返回同一组 IP 地址,即使服务器已关闭或无法访问也是如此。
路由算法
现在,我们来讨论一下常用的路由算法:
- 循环:将请求轮流分发到应用程序服务器。
- 加权循环:基于简单的循环技术构建,使用管理员可通过 DNS 记录分配的权重来考虑不同的服务器特征,例如计算和流量处理能力。
- 最少连接:将新请求发送到当前与客户端连接最少的服务器。每台服务器的相对计算能力在确定哪台服务器的连接最少时都会被考虑在内。
- 最短响应时间:将请求发送到由公式选择的服务器,该公式将最快的响应时间和最少的活动连接组合在一起。
- 最小带宽:此方法以兆比特每秒 (Mbps) 为单位测量流量,将客户端请求发送到流量最少的服务器。
- 哈希:根据我们定义的密钥(例如客户端 IP 地址或请求 URL)分发请求。
优势
负载均衡在防止停机方面也起着关键作用,负载均衡的其他优点包括:
- 可扩展性
- 冗余
- 灵活性
- 效率
冗余负载均衡器
正如你一定已经猜到的那样,负载均衡器本身可能是单点故障。为了克服这个问题,可以在集群模式下使用第二个或多个负载均衡器。
N
而且,如果检测到故障并且主动负载均衡器发生故障,则可以接管另一个被动负载均衡器,这将使我们的系统更具容错能力。
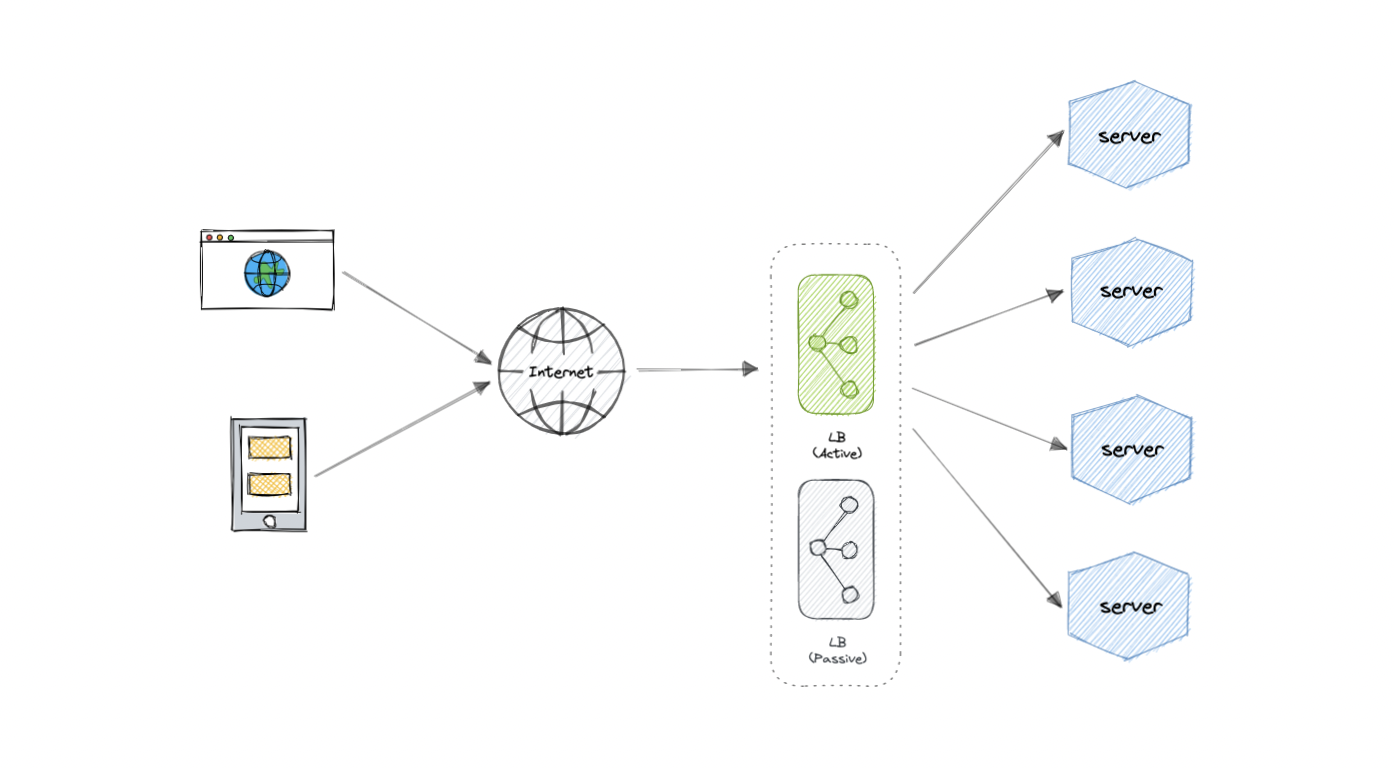
特征
以下是负载均衡器的一些常见功能:
- 自动缩放:根据需求条件启动和关闭资源。
- 粘性会话:能够将同一用户或设备分配给同一资源,以维护资源上的会话状态。
- 运行状况检查:能够确定资源是否关闭或性能不佳,以便从负载平衡池中删除该资源。
- 持久性连接:允许服务器打开与客户端(如 WebSocket)的持久性连接。
- 加密:处理加密连接,例如 TLS 和 SSL。
- 证书:向客户端提供证书并验证客户端证书。
- 压缩:压缩响应。
- 缓存:应用层负载均衡器可能提供缓存响应的功能。
- 日志记录:记录请求和响应元数据可以作为重要的审核跟踪或分析数据的来源。
- 请求跟踪:为每个请求分配一个唯一的 ID,以便进行日志记录、监视和故障排除。
- 重定向:根据请求的路径等因素重定向传入请求的能力。
- 修复响应:返回请求的静态响应,例如错误消息。
例子
以下是一些业界常用的负载均衡解决方案:
聚类
概括地说,计算机群集是一组由两台或多台计算机或节点组成的组,它们并行运行以实现共同目标。这允许由大量单独的、可并行化的任务组成的工作负载分布在集群中的节点之间。因此,这些任务可以利用每台计算机的组合内存和处理能力来提高整体性能。
若要生成计算机群集,应将各个节点连接到网络以启用节点间通信。然后,该软件可用于将节点连接在一起并形成集群。它可能在每个节点上都有一个共享存储设备和/或本地存储。
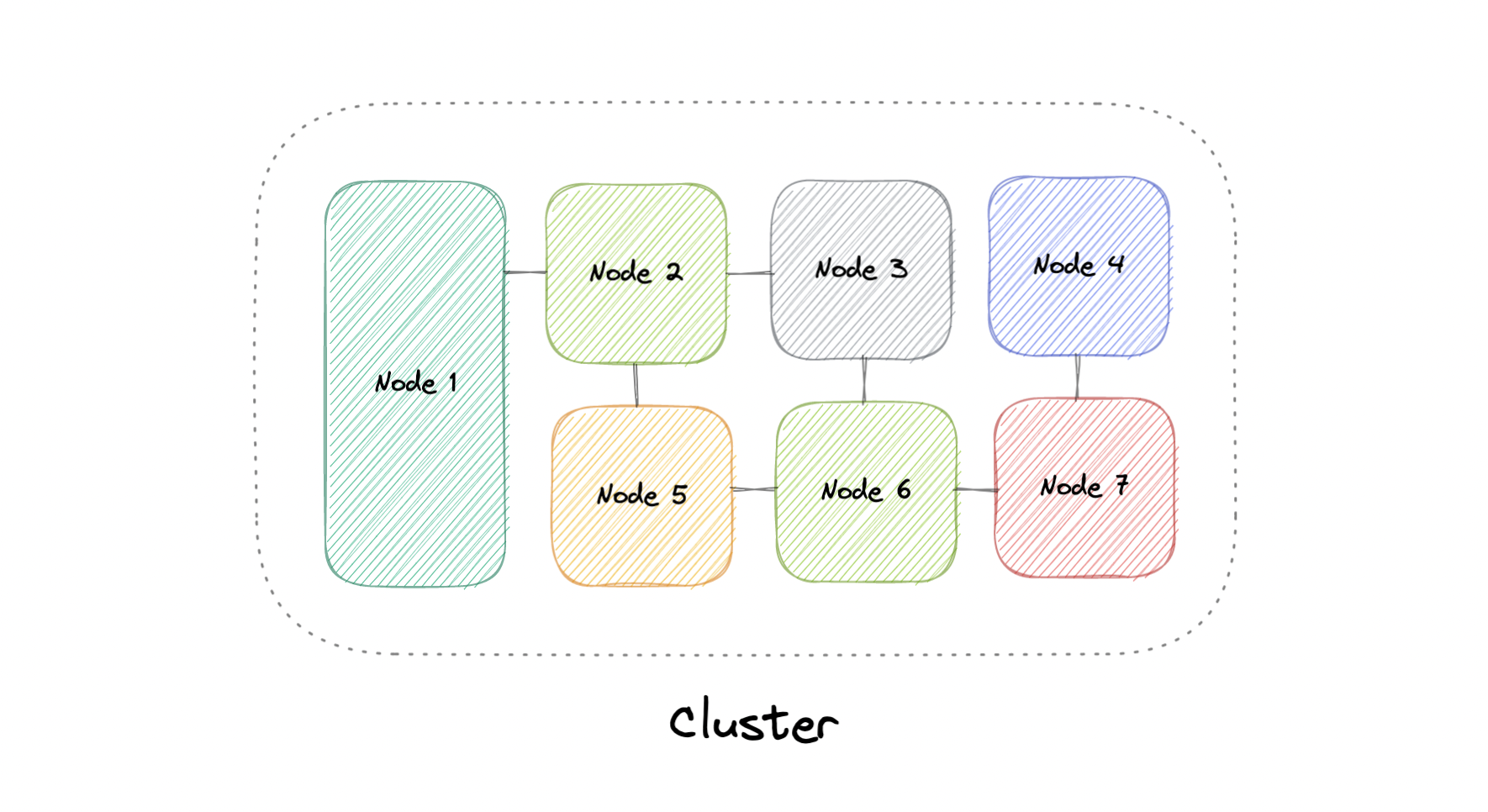
通常,至少有一个节点被指定为领导节点,并充当集群的入口点。领导节点可能负责将传入的工作委派给其他节点,并在必要时聚合结果并向用户返回响应。
理想情况下,集群的功能就像它是单个系统一样。访问群集的用户不需要知道系统是群集还是单个计算机。此外,集群的设计应最大程度地减少延迟并防止节点间通信出现瓶颈。
类型
计算机群集通常可分为三种类型:
- 高可用性或故障转移
- 负载均衡
- 高性能计算
配置
两种最常用的高可用性 (HA) 群集配置是主动-主动和主动-被动。
主动-主动
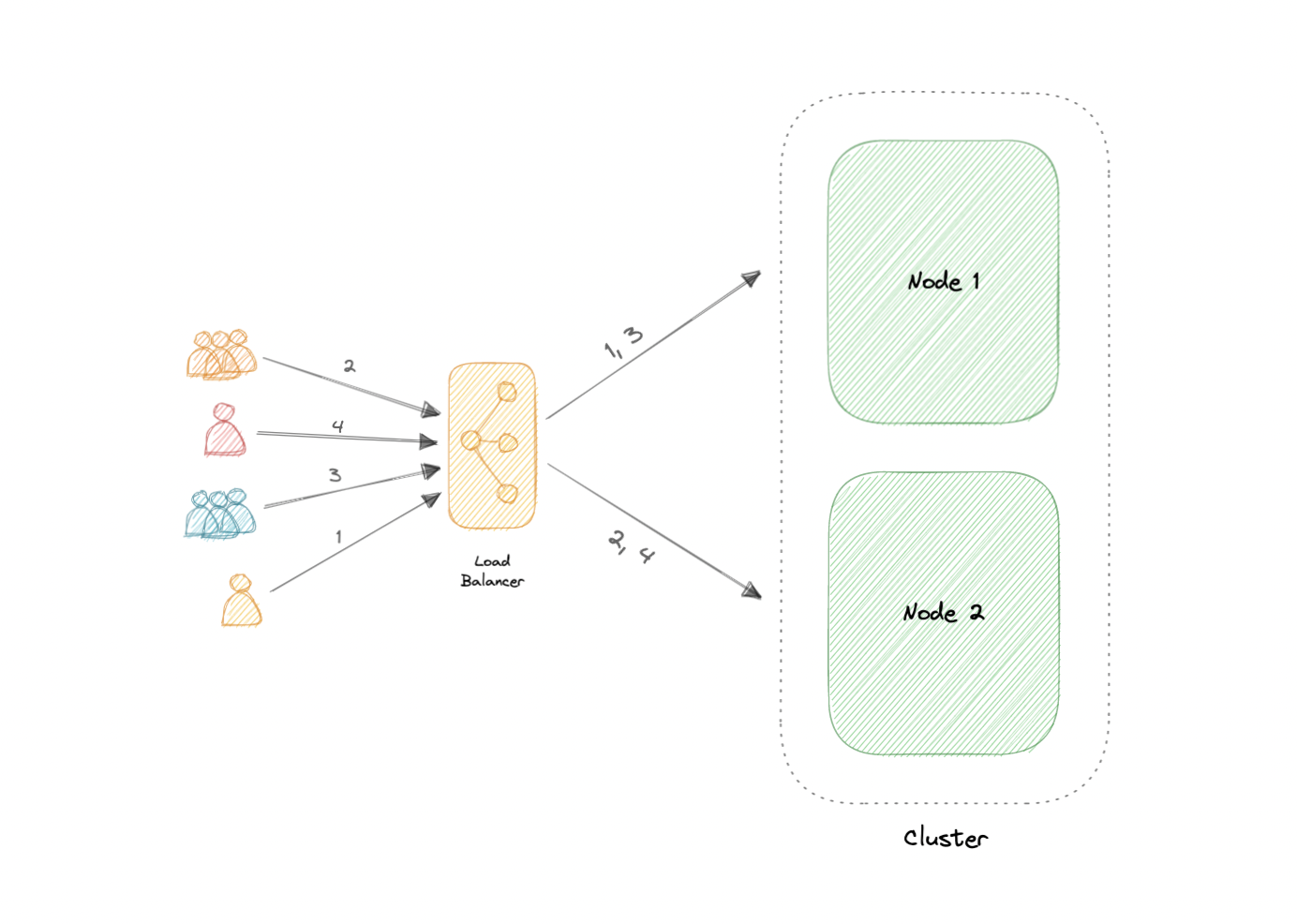
主动-主动群集通常由至少两个节点组成,这两个节点同时主动运行相同类型的服务。双活集群的主要目的是实现负载均衡。负载均衡器将工作负载分布在所有节点上,以防止任何单个节点过载。由于有更多的节点可供服务,因此吞吐量和响应时间也将有所改善。
主动-被动
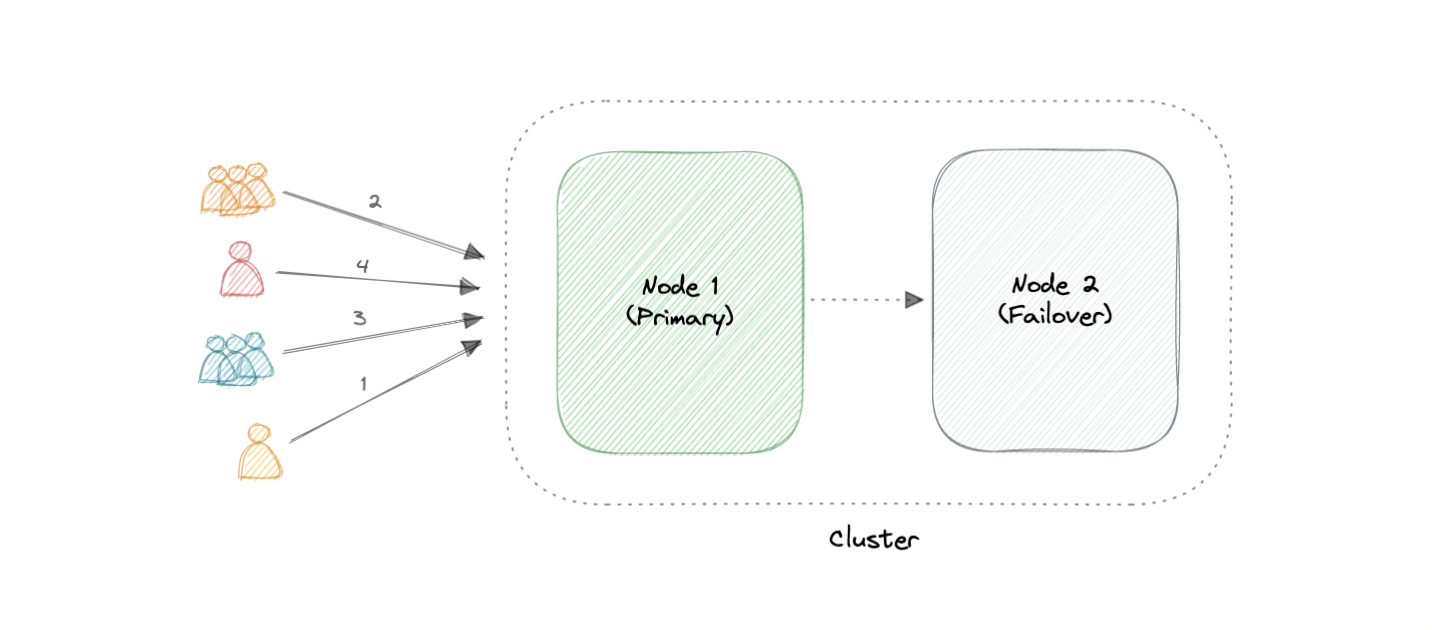
与主动-主动群集配置一样,主动-被动群集也由至少两个节点组成。但是,正如名称“主动-被动”所暗示的那样,并非所有节点都将处于活动状态。例如,在有两个节点的情况下,如果第一个节点已经处于活动状态,则第二个节点必须处于被动状态或处于备用状态。
优势
集群计算的四大优势如下:
- 高可用性
- 可扩展性
- 性能
- 高性价比
负载均衡与群集
负载平衡与群集具有一些共同特征,但它们是不同的过程。群集提供冗余并提高容量和可用性。群集中的服务器相互了解,并朝着共同的目标协同工作。但是,通过负载平衡,服务器无法相互识别。相反,它们会对从负载均衡器收到的请求做出 React 。
我们可以将负载平衡与集群结合使用,但它也适用于涉及具有共同目的的独立服务器的情况,例如运行网站、业务应用程序、Web 服务或其他一些 IT 资源。
挑战
集群带来的最明显的挑战是安装和维护的复杂性增加。必须在每个节点上安装和更新操作系统、应用程序及其依赖项。
如果群集中的节点不是同构的,则情况会变得更加复杂。还必须密切监视每个节点的资源利用率,并应汇总日志以确保软件正常运行。
此外,存储变得更加难以管理,共享存储设备必须防止节点相互覆盖,并且分布式数据存储必须保持同步。
例子
聚类在行业中是常用的,通常许多技术都提供某种聚类模式。例如:
- 容器(例如 Kubernetes、Amazon ECS)
- 数据库(例如 Cassandra、MongoDB)
- 缓存(例如 Redis)
缓存
“计算机科学中只有两件难事:缓存失效和命名。”
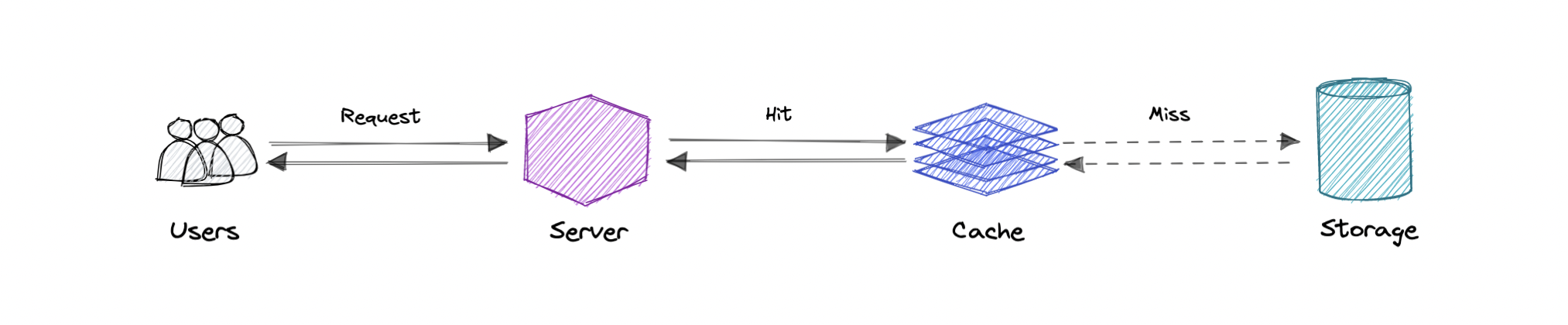
缓存的主要目的是通过减少访问底层较慢存储层的需要来提高数据检索性能。缓存通常以容量换取速度,通常暂时存储数据子集,而数据库的数据通常是完整且持久的。
缓存利用了引用的局部性原则“最近请求的数据可能会再次被请求”。
缓存和内存
与计算机的内存一样,缓存是一种紧凑、性能快速的内存,它以级别层次结构存储数据,从第一级开始,然后依次进行。它们被标记为 L1、L2、L3 等。如果请求,也会写入缓存,例如当有更新并且需要将新内容保存到缓存中时,替换已保存的旧内容。
无论缓存是读取还是写入,它都是一次完成一个块。每个块还有一个标签,其中包括数据在缓存中的存储位置。当从缓存中请求数据时,将通过标记进行搜索,以查找内存第一级 (L1) 中所需的特定内容。如果未找到正确的数据,则会在 L2 中执行更多搜索。
如果在那里找不到数据,则在 L3 中继续搜索,然后在 L4 中继续搜索,依此类推,直到找到它,然后读取并加载它。如果在缓存中根本没有找到数据,则会将其写入缓存中,以便下次快速检索。
缓存命中和缓存未命中
缓存命中
缓存命中描述从缓存成功提供内容的情况。标签在内存中快速搜索,当找到并读取数据时,它被视为缓存命中。
冷缓存、温缓存和热缓存
缓存命中也可以描述为冷、暖或热。在每一项中,都描述了读取数据的速度。
热缓存是以尽可能快的速率从内存中读取数据的实例。当从 L1 检索数据时,会发生这种情况。
冷缓存是读取数据的最慢速率,但它仍然成功,因此仍被视为缓存命中。数据只是在内存层次结构的较低位置(例如在 L3 或更低位置)中找到。
热缓存用于描述在 L2 或 L3 中找到的数据。它不如热缓存快,但仍然比冷缓存快。通常,将缓存称为 warm 用于表示它比热缓存更慢且更接近冷缓存。
缓存未命中
缓存未命中是指搜索内存时未找到数据的实例。发生这种情况时,内容将被传输并写入缓存中。
缓存失效
缓存失效是计算机系统将缓存条目声明为无效并删除或替换它们的过程。如果数据被修改,则应在缓存中使其失效,否则,这可能会导致应用程序行为不一致。缓存系统有三种类型:
直写缓存
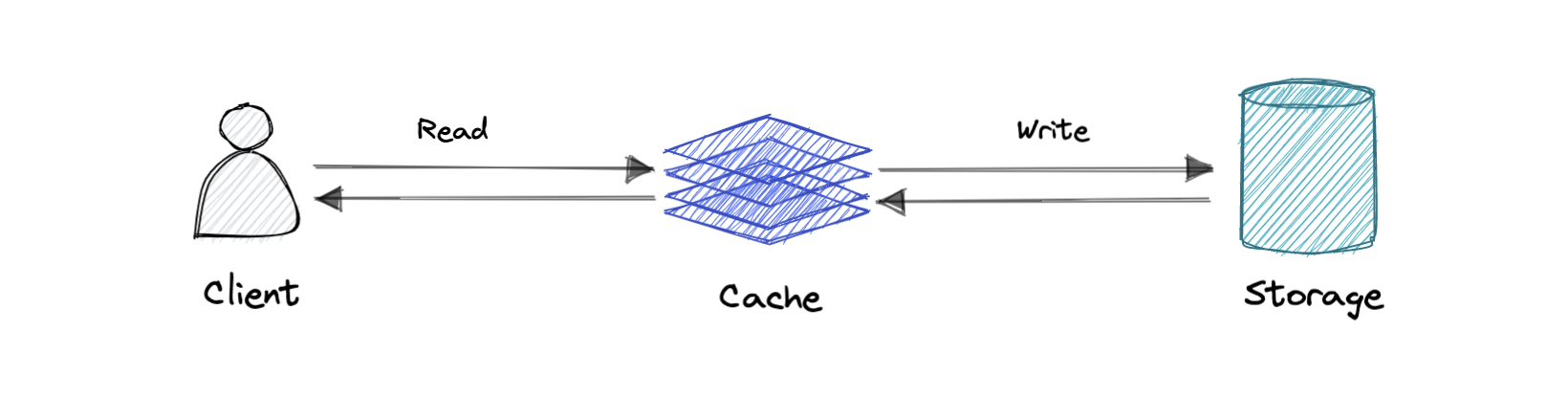
数据同时写入缓存和相应的数据库。
优点:快速检索,缓存和存储之间完全一致的数据。
缺点:写入操作的延迟较高。
绕写缓存
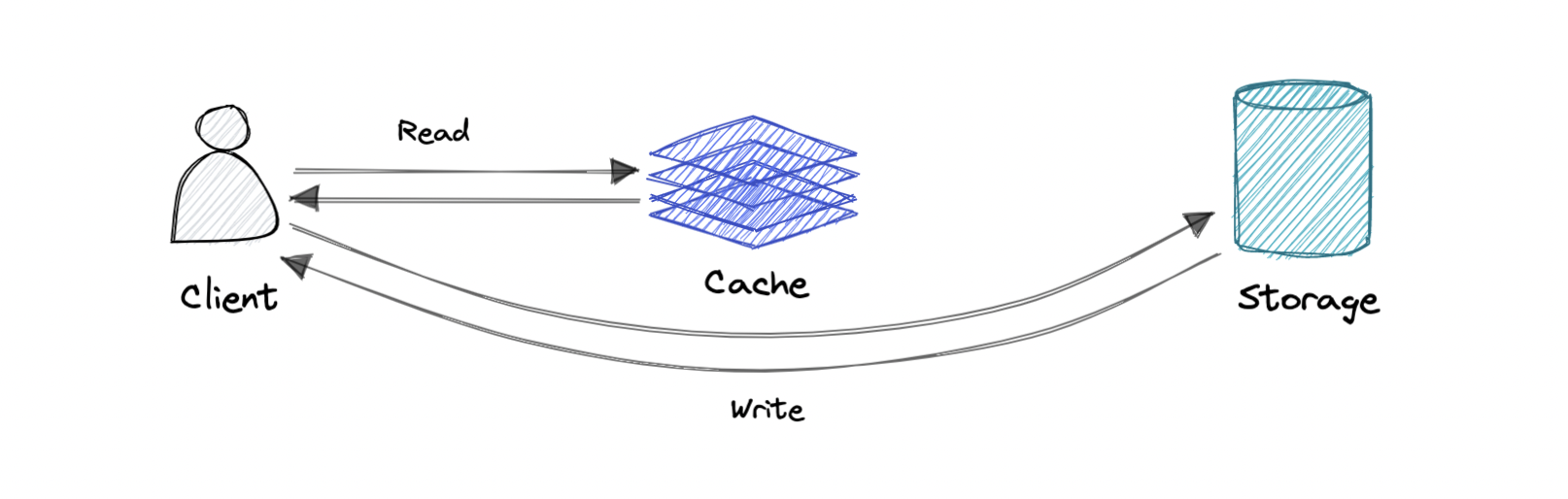
其中写入直接进入数据库或永久存储,绕过缓存。
优点:这可以减少延迟。
缺点:它会增加缓存未命中,因为缓存系统必须在缓存未命中的情况下从数据库中读取信息。因此,对于快速写入和重新读取信息的应用程序,这可能会导致更高的读取延迟。读取发生在较慢的后端存储中,并经历更高的延迟。
回写式缓存
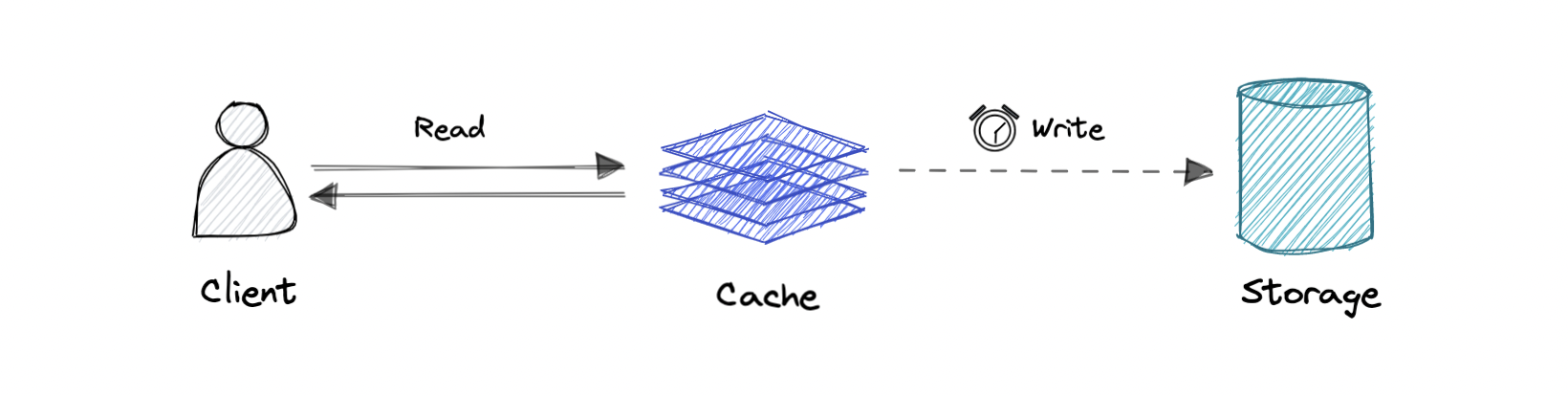
其中仅对缓存层进行写入,并在对缓存的写入完成后立即确认写入。然后,缓存将此写入异步同步到数据库。
优点:这将减少写入密集型应用程序的延迟和高吞吐量。
缺点:如果缓存层崩溃,则存在数据丢失的风险。我们可以通过让多个副本在缓存中确认写入来改进这一点。
逐出策略
以下是一些最常见的缓存逐出策略:
- 先进先出 (FIFO):缓存会逐出第一个首先访问的块,而不考虑之前访问的频率或次数。
- 后进先出 (LIFO):缓存会逐出最近首先访问的块,而不考虑之前访问的频率或次数。
- 最近最少使用 (LRU):首先丢弃最近最少使用的项目。
- 最近使用的项目 (MRU):与 LRU 相比,首先丢弃最近使用的项目。
- 最不常用 (LFU):计算需要某个项目的频率。那些最不经常使用的东西首先被丢弃。
- 随机替换 (RR):随机选择一个候选项目,并在必要时将其丢弃以腾出空间。
分布式缓存
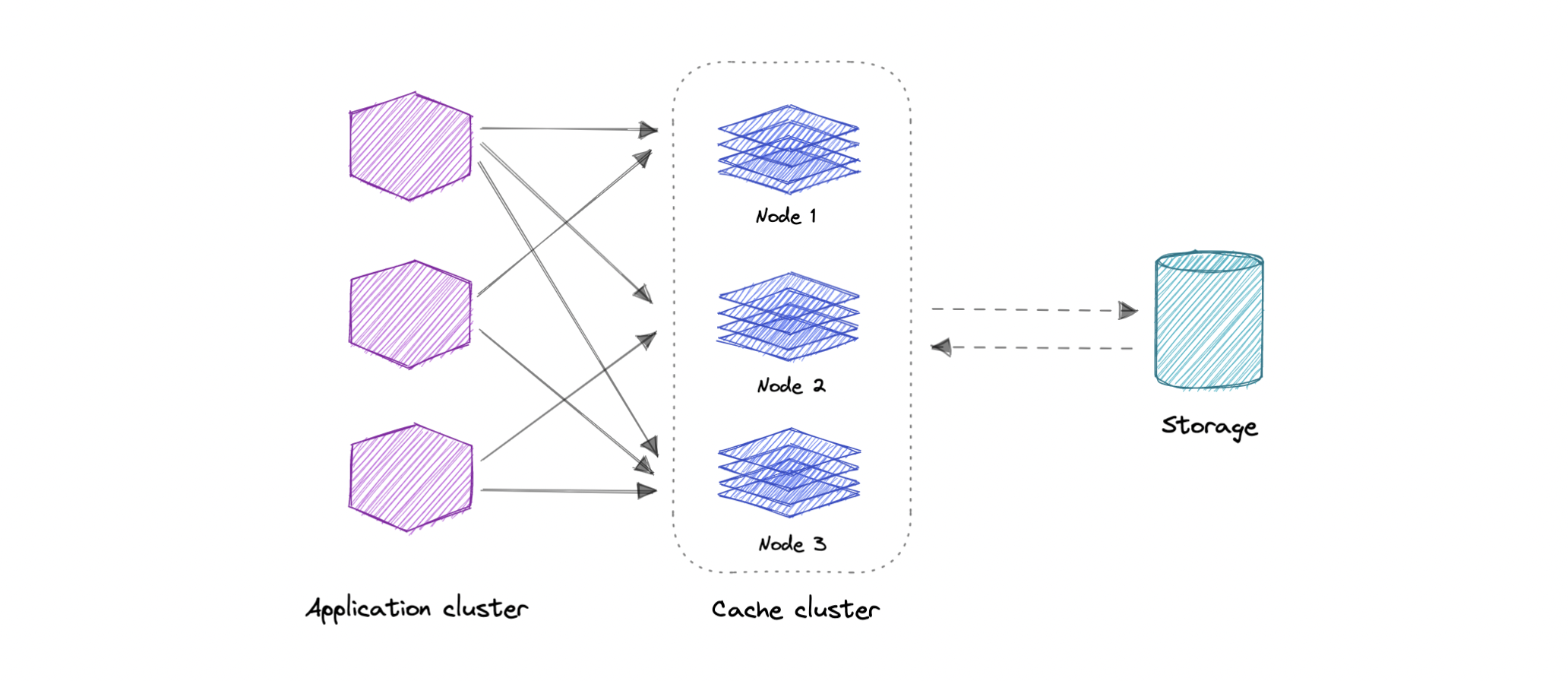
分布式缓存是一种系统,它将多台联网计算机的随机存取内存 (RAM) 汇集到一个用作数据缓存的内存中数据存储中,以提供对数据的快速访问。虽然大多数缓存传统上位于一个物理服务器或硬件组件中,但分布式缓存可以通过将多台计算机链接在一起而超出单台计算机的内存限制。
全局缓存
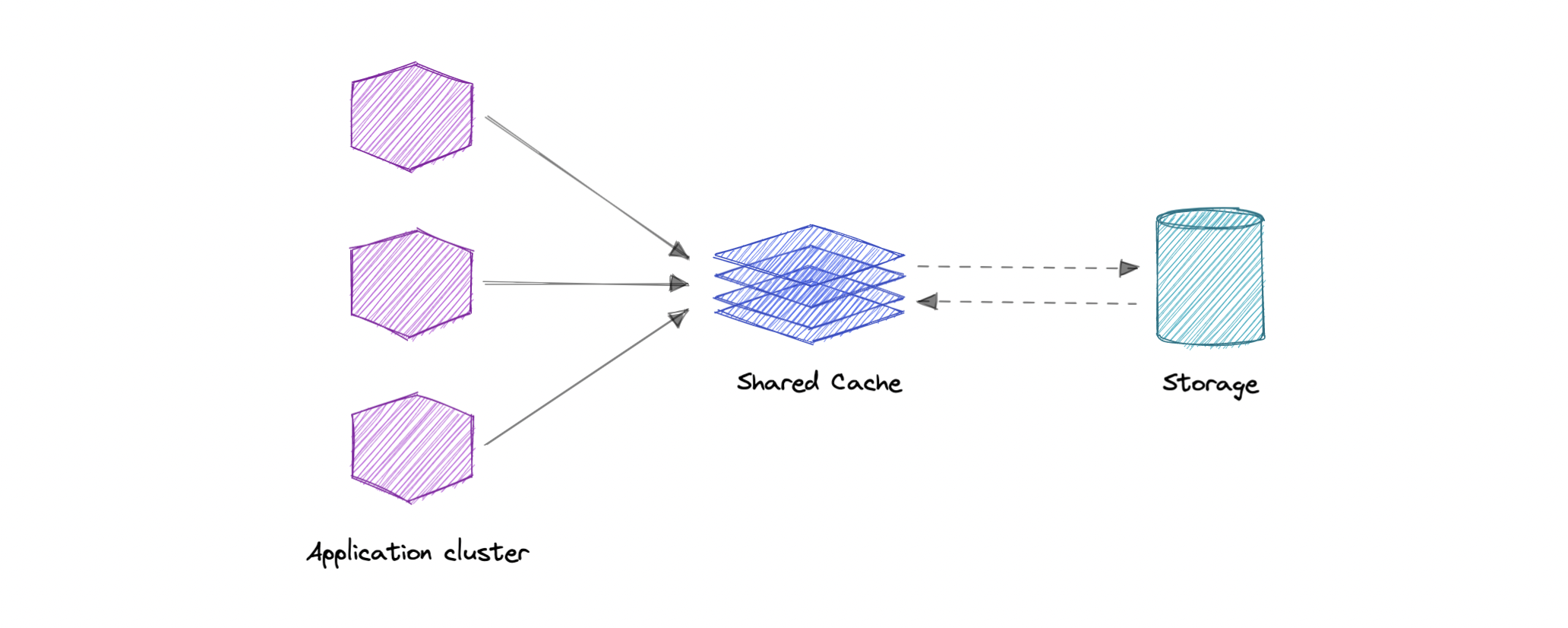
顾名思义,我们将拥有一个所有应用程序节点都将使用的共享缓存。当在全局缓存中找不到请求的数据时,缓存负责从基础数据存储中找出缺失的数据片段。
使用案例
缓存可以有许多实际用例,例如:
- 数据库缓存
- 内容分发网络 (CDN)
- 域名系统 (DNS) 缓存
- API 缓存
何时不使用缓存?
让我们再看一些不应该使用缓存的场景:
- 当访问缓存所需的时间与访问主数据存储所需的时间一样长时,缓存没有帮助。
- 当请求具有低重复性(较高随机性)时,缓存无法正常工作,因为缓存性能来自重复的内存访问模式。
- 当数据频繁更改时,缓存没有帮助,因为缓存的版本会不同步,并且每次都必须访问主数据存储。
需要注意的是,缓存不应用作永久数据存储。它们几乎总是在易失性内存中实现,因为它速度更快,因此应被视为瞬态的。
优势
以下是缓存的一些优点:
- 提高性能
- 减少延迟
- 减少数据库负载
- 降低网络成本
- 提高读取吞吐量
例子
以下是一些常用的缓存技术:
内容分发网络 (CDN)
内容交付网络 (CDN) 是一组地理位置分散的服务器,它们协同工作以提供 Internet 内容的快速交付。通常,HTML/CSS/JS、照片和视频等静态文件由 CDN 提供。
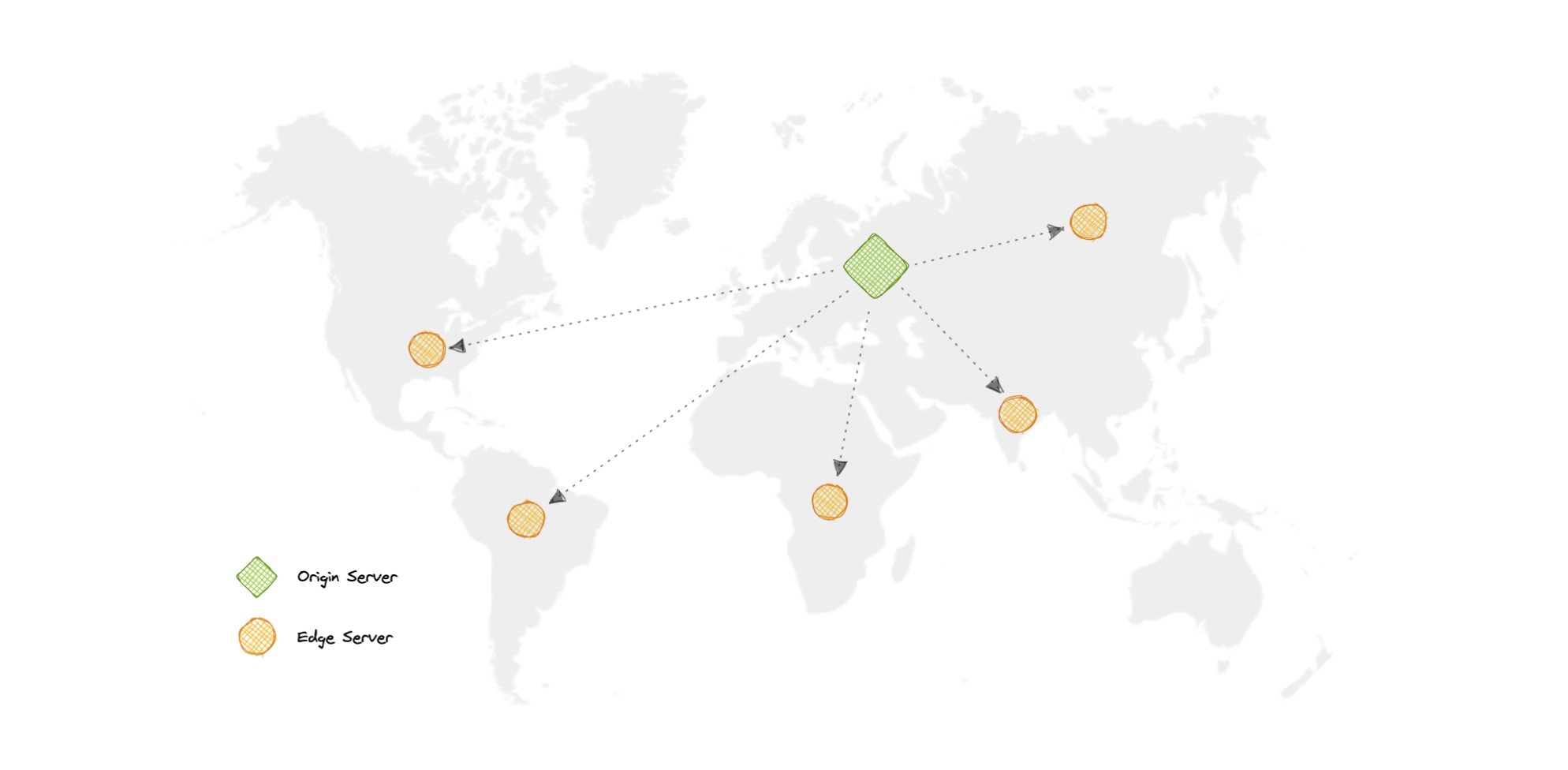
为什么要使用 CDN?
内容分发网络 (CDN) 可提高内容可用性和冗余度,同时降低带宽成本并提高安全性。从 CDN 提供内容可以显着提高性能,因为用户从他们附近的数据中心接收内容,而我们的服务器不必为 CDN 满足的请求提供服务。
CDN 是如何工作的?
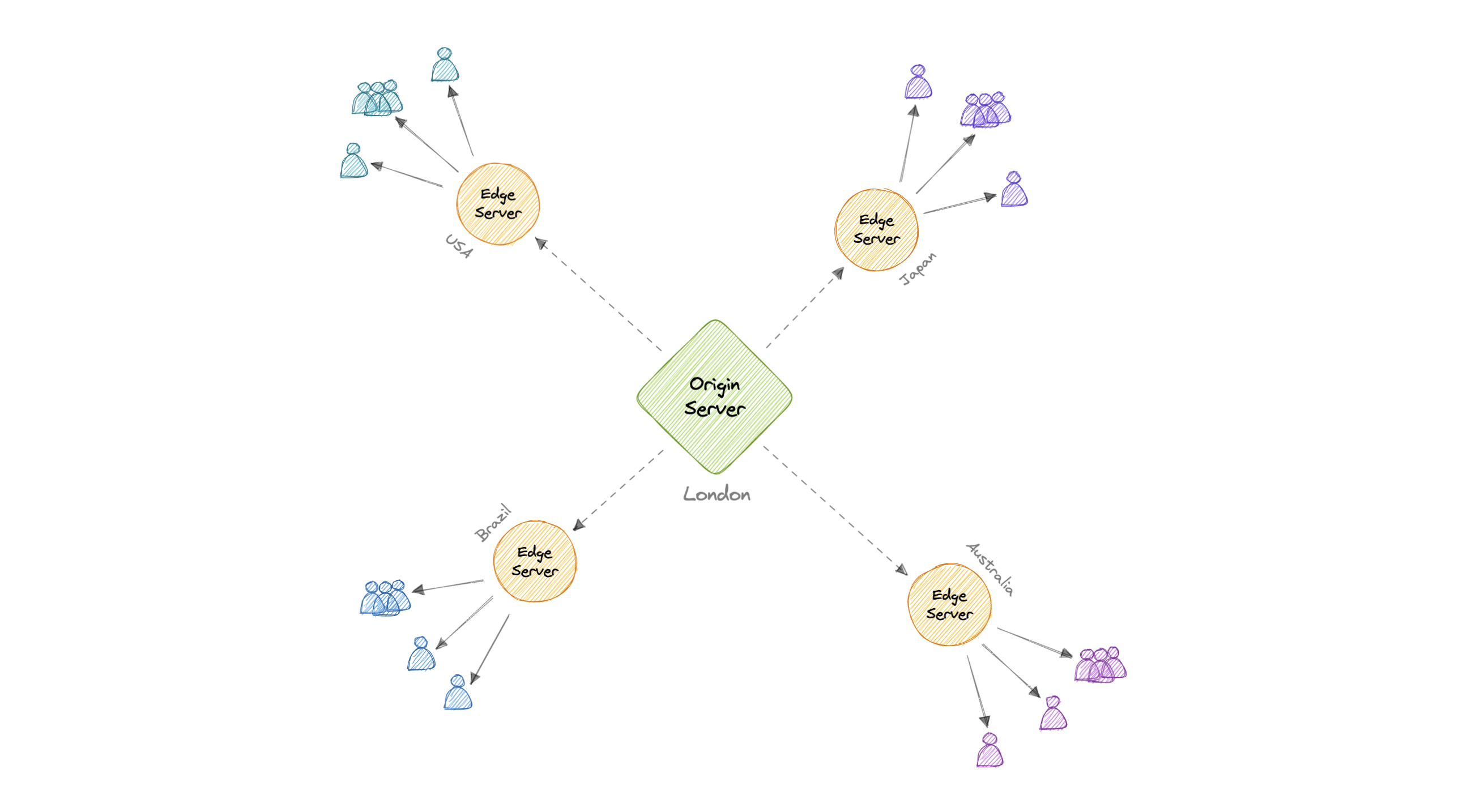
在 CDN 中,源服务器包含内容的原始版本,而边缘服务器数量众多,分布在世界各地的不同位置。
为了最小化访问者与网站服务器之间的距离,CDN 将其内容的缓存版本存储在多个地理位置(称为边缘位置)中。每个边缘站点都包含多个缓存服务器,负责将内容交付给附近的访问者。
一旦静态资产缓存在特定位置的所有 CDN 服务器上,所有后续网站访问者对静态资产的请求都将从这些边缘服务器而不是源站发送,从而减少源站负载并提高可扩展性。
例如,当英国的某个人请求我们的网站(可能托管在美国)时,他们将从最近的边缘站点(例如伦敦边缘站点)提供服务。这比让访问者向源服务器发出完整的请求要快得多,这将增加延迟。
类型
CDN一般分为两种类型:
推送 CDN
每当服务器上发生更改时,推送 CDN 都会接收新内容。我们全权负责提供内容、直接上传到 CDN 以及重写 URL 以指向 CDN。我们可以配置内容何时过期以及何时更新。仅当内容是新的或更改的内容时才上传,从而最大限度地减少流量,但最大化存储空间。
流量较小的网站或内容不经常更新的网站可以很好地与推送 CDN 配合使用。 内容在 CDN 上放置一次,而不是定期重新拉取。
拉取 CDN
在拉取 CDN 情况下,缓存会根据请求进行更新。当客户端发送请求时,如果 CDN 没有静态资产,则要求从 CDN 获取静态资产,它将从源服务器获取新更新的资产,并用此新资产填充其缓存,然后将此新缓存资产发送给用户。
与推送 CDN 相反,这需要较少的维护,因为 CDN 节点上的缓存更新是根据从客户端到源服务器的请求执行的。流量大的网站与拉式 CDN 配合得很好,因为流量分布得更均匀,CDN 上只保留最近请求的内容。
弊
众所周知,好东西会带来额外的成本,所以让我们讨论一下 CDN 的一些缺点:
- 额外费用:使用 CDN 可能很昂贵,尤其是对于高流量服务。
- 限制:一些组织和国家/地区已阻止流行 CDN 的域或 IP 地址。
- 位置:如果我们的大多数受众位于 CDN 没有服务器的国家/地区,则我们网站上的数据可能必须比不使用任何 CDN 传播得更远。
例子
以下是一些广泛使用的 CDN:
代理
代理服务器是位于客户端和后端服务器之间的中间硬件/软件。它接收来自客户端的请求,并将其中继到源服务器。通常,代理用于过滤请求、记录请求,有时还用于转换请求(通过添加/删除标头、加密/解密或压缩)。
类型
有两种类型的代理:
转发代理
转发代理(通常称为代理、代理服务器或 Web 代理)是位于一组客户端计算机前面的服务器。当这些计算机向 Internet 上的站点和服务发出请求时,代理服务器会截获这些请求,然后代表这些客户端与 Web 服务器进行通信,就像中间人一样。
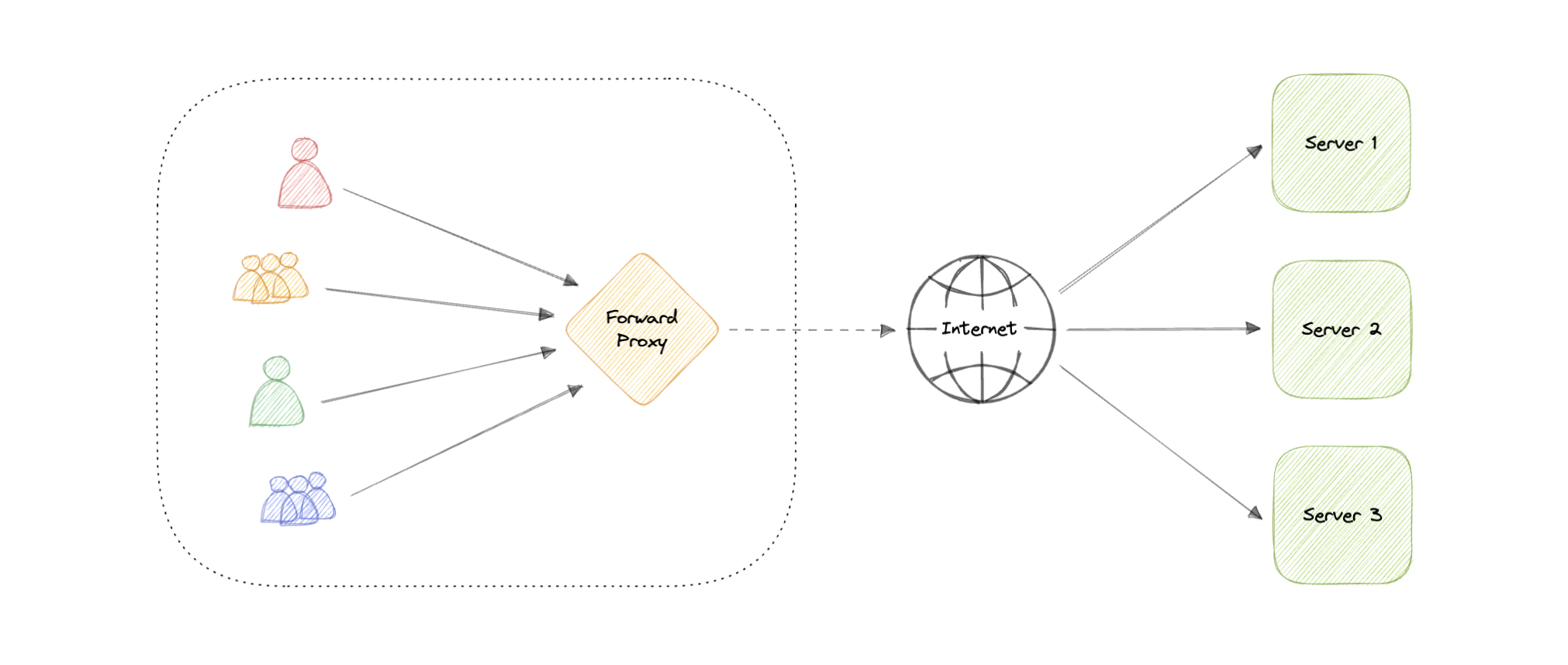
优势
以下是转发代理的一些优点:
- 阻止访问某些内容
- 允许访问受地理限制的内容
- 提供匿名性
- 避免其他浏览限制
尽管代理提供了匿名的好处,但它们仍然可以跟踪我们的个人信息。代理服务器的设置和维护可能成本高昂,并且需要配置。
反向代理
反向代理是位于一个或多个 Web 服务器前面的服务器,用于拦截来自客户端的请求。当客户端向网站的源服务器发送请求时,这些请求会被反向代理服务器拦截。
正向代理和反向代理之间的区别很微妙,但很重要。总结它的简化方法是说,转发代理位于客户端的前面,并确保没有源服务器直接与该特定客户端通信。另一方面,反向代理位于源服务器的前面,并确保没有客户端直接与该源服务器通信。
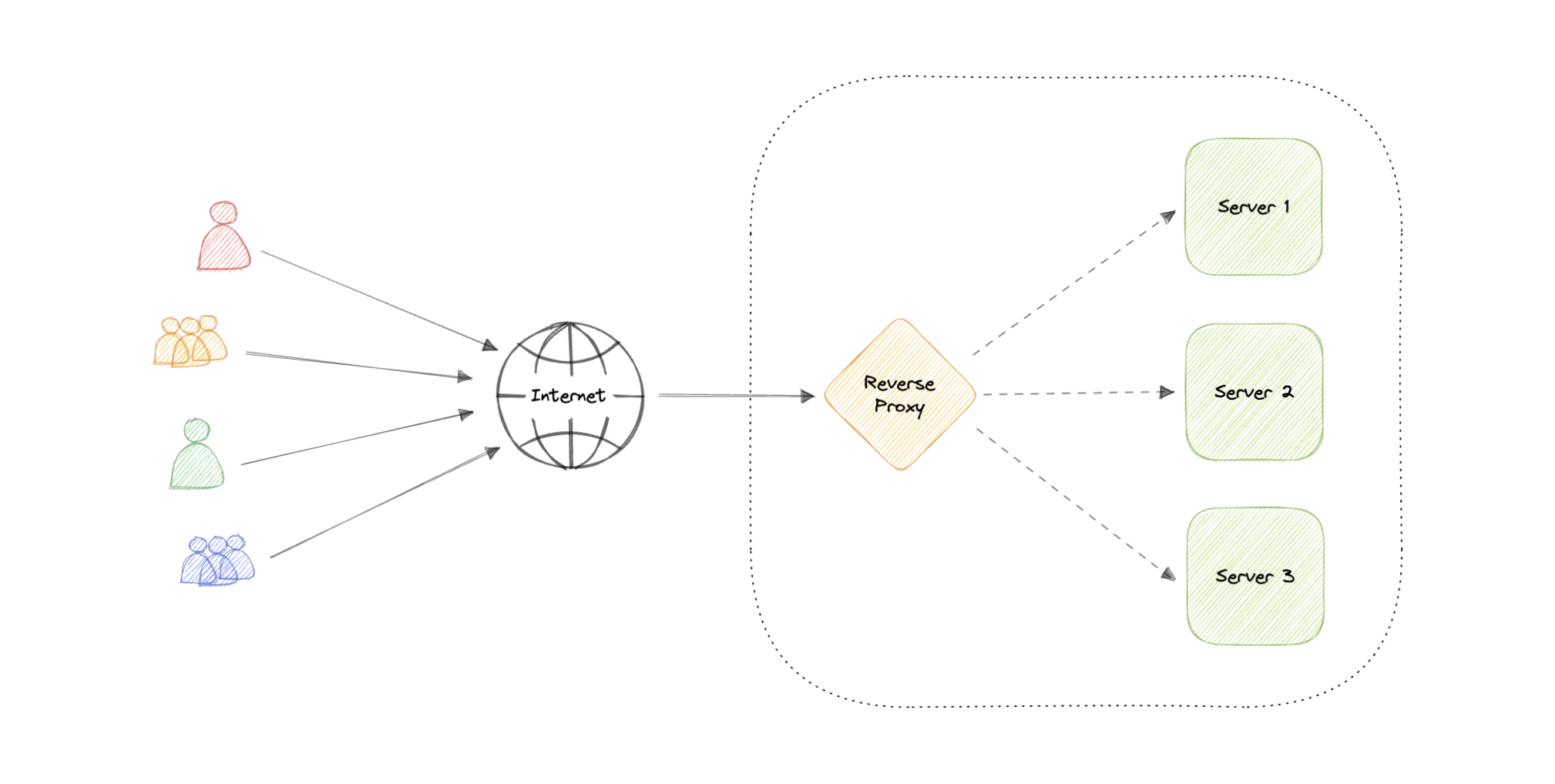
引入反向代理会导致复杂性增加。单个反向代理是单点故障,配置多个反向代理(即故障转移)会进一步增加复杂性。
优势
以下是使用反向代理的一些优点:
- 提高安全性
- 缓存
- SSL加密
- 负载均衡
- 可扩展性和灵活性
负载均衡器与反向代理
等等,反向代理不是类似于负载均衡器吗?好吧,不,因为当我们有多个服务器时,负载平衡器很有用。通常,负载均衡器将流量路由到一组提供相同功能的服务器,而反向代理即使只有一个 Web 服务器或应用程序服务器也很有用。反向代理也可以充当负载平衡器,但不能充当负载均衡器。
例子
以下是一些常用的代理技术:
可用性
可用性是指系统在特定时间段内保持运行以执行其所需功能的时间。它是系统、服务或机器在正常条件下保持运行时间百分比的简单度量。
可用性的九
可用性通常通过正常运行时间(或停机时间)来量化,作为服务可用时间的百分比。一般以9s的数量来衡量。
$$ 可用性 = \frac{正常运行时间}{(正常运行时间 + 停机时间)} $$
如果可用性为 99.00% 可用,则称为“2 个 9”的可用性,如果为 99.9%,则称为“3 个 9”,依此类推。
| 可用性(百分比) | 停机时间(年) | 停机时间(月) | 停机时间(周) |
|---|---|---|---|
| 90%(一九) | 36.53 天 | 72小时 | 16.8 小时 |
| 99%(两个 9) | 3.65 天 | 7.20 小时 | 1.68 小时 |
| 99.9%(三个九) | 8.77 小时 | 43.8分钟 | 10.1 分钟 |
| 99.99%(四个九) | 52.6分钟 | 4.32分钟 | 1.01分钟 |
| 99.999%(五个九) | 5.25分钟 | 25.9 秒 | 6.05 秒 |
| 99.9999%(6个9) | 31.56 秒 | 2.59 秒 | 604.8 毫秒 |
| 99.99999%(七个九) | 3.15 秒 | 263 毫秒 | 60.5 毫秒 |
| 99.999999%(8个9) | 315.6 毫秒 | 26.3 毫秒 | 6 毫秒 |
| 99.9999999%(九个九) | 31.6 毫秒 | 2.6 毫秒 | 0.6 毫秒 |
顺序可用性与并行可用性
如果服务由多个容易发生故障的组件组成,则服务的整体可用性取决于这些组件是按顺序还是并行。
序列
当两个组件按顺序排列时,整体可用性会降低。
$$ 可用性 \space (Total) = 可用性 \space (Foo) * 可用性 \space (Bar) $$
例如,如果两者和每个都有 99.9% 的可用性,则它们的总可用性依次为 99.8%。
Foo
Bar
平行
当两个组件并行时,整体可用性会提高。
$$ 可用性 \space (Total) = 1 - (1 - 可用性 \space (Foo)) * (1 - 可用性 \space (bar)) $$
例如,如果两者和每个都有 99.9% 的可用性,则它们的并行总可用性将为 99.9999%。
Foo
Bar
可用性与可靠性
如果一个系统是可靠的,它就是可用的。但是,如果它可用,则不一定可靠。换言之,高可靠性有助于实现高可用性,但即使系统不可靠,也可以实现高可用性。
高可用性与容错
高可用性和容错性都适用于提供高正常运行时间级别的方法。但是,它们以不同的方式实现目标。
容错系统不会中断服务,但成本要高得多,而高可用性系统的服务中断最小。容错需要完全的硬件冗余,就像主系统发生故障一样,在不损失正常运行时间的情况下,另一个系统应该接管。
可扩展性
可伸缩性是衡量系统通过添加或删除资源来满足需求来响应更改的程度。
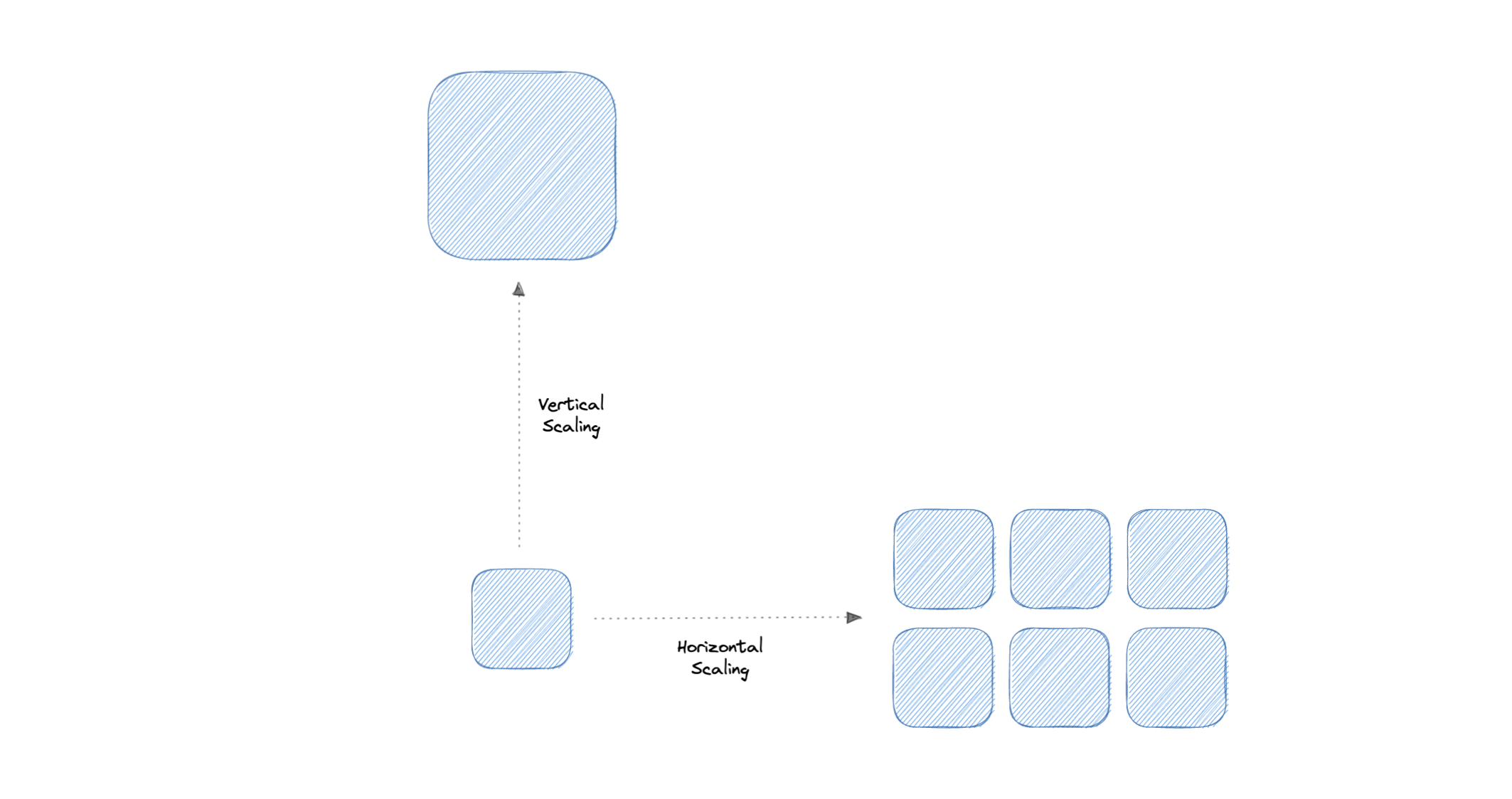
让我们讨论不同类型的缩放:
垂直缩放
垂直扩展(也称为纵向扩展)通过为现有计算机增加更多功能来扩展系统的可扩展性。换句话说,垂直扩展是指通过增加硬件容量来提高应用程序的功能。
优势
- 易于实施
- 更易于管理
- 数据一致
弊
- 高停机时间风险
- 更难升级
- 可能是单点故障
水平缩放
水平扩展(也称为横向扩展)通过添加更多计算机来扩展系统的规模。它通过向现有服务器池添加更多实例来提高服务器的性能,从而允许更均匀地分配负载。
优势
- 增加冗余
- 更好的容错能力
- 灵活高效
- 更易于升级
弊
- 复杂性增加
- 数据不一致
- 下游服务负载增加
存储
存储是一种机制,使系统能够临时或永久保留数据。在系统设计的上下文中,这个主题大多被跳过,但是,对一些常见的存储技术类型有一个基本的了解是很重要的,这些技术可以帮助我们微调我们的存储组件。让我们讨论一些重要的存储概念:
袭击
RAID(独立磁盘冗余阵列)是一种将相同数据存储在多个硬盘或固态硬盘 (SSD) 上的方法,以在驱动器发生故障时保护数据。
但是,有不同的 RAID 级别,并且并非所有级别都以提供冗余为目标。让我们讨论一些常用的RAID级别:
- RAID 0:也称为条带化,数据在阵列中的所有驱动器上均匀分配。
- RAID 1:也称为镜像,至少两个驱动器包含一组数据的精确副本。如果一个驱动器发生故障,其他驱动器仍将工作。
- RAID 5:带奇偶校验的条带化。需要使用至少 3 个驱动器,在多个驱动器(如 RAID 0)之间条带化数据,但也在驱动器之间分配奇偶校验。
- RAID 6:具有双奇偶校验的条带化。RAID 6 与 RAID 5 类似,但奇偶校验数据写入两个驱动器。
- RAID 10:将 RAID 0 和 RAID 1 的条带化和镜像相结合。它通过镜像辅助驱动器上的所有数据来提供安全性,同时在每组驱动器上使用条带化来加快数据传输速度。
比较
让我们比较一下不同RAID级别的所有功能:
| 特征 | RAID 0 磁盘阵列 | RAID 1 磁盘阵列 | RAID 5 磁盘阵列 | RAID 6 磁盘阵列 | RAID 10 磁盘阵列 |
|---|---|---|---|---|---|
| 描述 | 条带化 | 镜像 | 带奇偶校验的条带化 | 具有双奇偶校验的条带化 | 条带化和镜像 |
| 最小磁盘数 | 2 | 2 | 3 | 4 | 4 |
| 读取性能 | 高 | 高 | 高 | 高 | 高 |
| 写入性能 | 高 | 中等 | 高 | 高 | 中等 |
| 成本 | 低 | 高 | 低 | 低 | 高 |
| 容错 | 没有 | 单驱动器故障 | 单驱动器故障 | 双驱动器故障 | 每个子阵列中最多有一个磁盘故障 |
| 容量利用率 | 100% | 50% | 67%-94% | 50%-80% | 50% |
卷
卷是磁盘或磁带上的固定存储量。术语“卷”通常用作存储本身的同义词,但单个磁盘可以包含多个卷,或者卷可以跨越多个磁盘。
文件存储
文件存储是一种将数据存储为文件并将其作为分层目录结构呈现给最终用户的解决方案。主要优点是提供用户友好的解决方案来存储和检索文件。若要在文件存储中查找文件,需要文件的完整路径。它经济且易于构建,通常位于硬盘驱动器上,这意味着它们对用户和硬盘驱动器的外观完全相同。
示例:Amazon EFS、Azure 文件、Google Cloud Filestore 等。
块存储
块存储将数据划分为块(块),并将它们存储为单独的块。每个数据块都有一个唯一的标识符,允许存储系统将较小的数据块放置在最方便的地方。
块存储还可以将数据与用户环境分离,从而允许数据分布在多个环境中。这将创建数据的多个路径,并允许用户快速检索数据。当用户或应用程序从块存储系统请求数据时,底层存储系统会重新组合数据块并将数据呈现给用户或应用程序
示例:Amazon EBS。
对象存储
对象存储(也称为基于对象的存储)将数据文件分解为称为对象的部分。然后,它将这些对象存储在单个存储库中,该存储库可以分布在多个网络系统中。
示例:Amazon S3、Azure Blob Storage、Google Cloud Storage 等。
NAS网络存储
NAS(网络附加存储)是一种连接到网络的存储设备,允许授权网络用户从中心位置存储和检索数据。NAS设备非常灵活,这意味着当我们需要额外的存储空间时,我们可以增加现有的存储空间。它速度更快、成本更低,并且提供了现场公有云的所有优势,让我们能够完全控制。
HDFS的
Hadoop 分布式文件系统 (HDFS) 是一种分布式文件系统,旨在在商用硬件上运行。HDFS 具有高度的容错能力,旨在部署在低成本硬件上。HDFS提供对应用数据的高吞吐访问,适用于数据集较大的应用。它与现有的分布式文件系统有许多相似之处。
HDFS 旨在可靠地跨大型集群中的计算机存储非常大的文件。它将每个文件存储为一系列块,除了最后一个块之外,文件中的所有块都是相同的大小。复制文件的块以实现容错。
数据库和 DBMS
什么是数据库?
数据库是结构化信息或数据的有组织的集合,通常以电子方式存储在计算机系统中。数据库通常由数据库管理系统 (DBMS) 控制。数据和 DBMS 以及与之关联的应用程序统称为数据库系统,通常简称为数据库。
什么是DBMS?
数据库通常需要一个称为数据库管理系统 (DBMS) 的综合数据库软件程序。DBMS 充当数据库与其最终用户或程序之间的接口,允许用户检索、更新和管理信息的组织和优化方式。DBMS 还有助于监督和控制数据库,支持各种管理操作,例如性能监视、调整以及备份和恢复。
组件
以下是在不同数据库中发现的一些常见组件:
图式
架构的作用是定义数据结构的形状,并指定哪些类型的数据可以去哪里。架构可以在整个数据库中严格强制执行,也可以在数据库的一部分上松散地强制执行,或者它们可能根本不存在。
桌子
每个表都包含各种列,就像在电子表格中一样。一个表可以有两列,也可以有一百列或更多列,具体取决于表中放置的信息类型。
列
列包含一组特定类型的数据值,数据库的每一行对应一个值。列可以包含文本值、数字、枚举、时间戳等。
排
表中的数据以行的形式记录。表中可能有数千或数百万行包含任何特定信息。
类型

以下是不同类型的数据库:
SQL 和 NoSQL 数据库是广泛的主题,将在 SQL 数据库和 NoSQL 数据库中单独讨论。了解它们在 SQL 与 NoSQL 数据库中的比较情况。
挑战
大规模运行数据库时面临的一些常见挑战:
- 吸收数据量的显著增长:来自传感器、联网机器和数十个其他来源的数据爆炸式增长。
- 确保数据安全:如今,数据泄露无处不在,确保数据安全且用户易于访问比以往任何时候都更加重要。
- 紧跟需求:公司需要实时访问其数据,以支持及时决策并利用新机会。
- 管理和维护数据库和基础设施:随着数据库变得越来越复杂,数据量不断增长,公司面临着雇用更多人才来管理其数据库的费用。
- 消除可扩展性限制:企业要想生存下去,就需要发展壮大,其数据管理也必须随之发展。但是,很难预测公司需要多少容量,尤其是对于本地数据库。
- 确保数据驻留、数据主权或延迟要求:某些组织具有更适合在本地运行的用例。在这些情况下,为运行数据库而预先配置和预先优化的集成系统是理想的选择。
SQL 数据库
SQL(或关系)数据库是数据项的集合,它们之间具有预定义的关系。这些项目被组织为一组包含列和行的表。表用于保存有关要在数据库中表示的对象的信息。表中的每一列都包含某种类型的数据,字段存储属性的实际值。表中的行表示一个对象或实体的相关值的集合。
表中的每一行都可以用一个称为主键的唯一标识符进行标记,并且可以使用外键使多个表之间的行相关。可以通过多种不同的方式访问此数据,而无需重新组织数据库表本身。SQL 数据库通常遵循 ACID 一致性模型。
具体化视图
具体化视图是从查询规范派生并存储以供以后使用的预先计算的数据集。由于数据是预先计算的,因此查询具体化视图比对视图的基表执行查询要快。当查询频繁运行或足够复杂时,这种性能差异可能很大。
它还支持数据子集,并提高了在大型数据集上运行的复杂查询的性能,从而减少了网络负载。实例化视图还有其他用途,但它们主要用于性能和复制。
N+1查询问题
当数据访问层执行 N 个额外的 SQL 语句来获取在执行主 SQL 查询时可以检索到的相同数据时,就会发生 N+1 查询问题。N 的值越大,执行的查询越多,对性能的影响就越大。
这在 GraphQL 和 ORM(对象关系映射)工具中很常见,可以通过优化 SQL 查询或使用数据加载器来解决,该加载器对连续请求进行批处理并在后台发出单个数据请求。
优势
让我们看一下使用关系数据库的一些优点:
- 简单而准确
- 可及性
- 数据一致性
- 灵活性
弊
以下是关系数据库的缺点:
- 维护成本高昂
- 架构演进困难
- 性能命中(联接、非规范化等)
- 由于水平可扩展性差,难以扩展
例子
以下是一些常用的关系数据库:
NoSQL 数据库
NoSQL 是一个广泛的类别,包括任何不使用 SQL 作为其主要数据访问语言的数据库。这些类型的数据库有时也称为非关系数据库。与关系数据库不同,NoSQL 数据库中的数据不必符合预定义的架构。NoSQL 数据库遵循 BASE 一致性模型。
以下是不同类型的 NoSQL 数据库:
公文
文档数据库(也称为面向文档的数据库或文档存储)是将信息存储在文档中的数据库。它们是通用数据库,适用于事务和分析应用程序的各种用例。
优势
- 直观灵活
- 轻松水平扩展
- 无架构
弊
- 无架构
- 非关系型
例子
键值
键值数据库是最简单的 NoSQL 数据库类型之一,它将数据保存为一组键值对,每个键值对由两个数据项组成。它们有时也称为键值存储。
优势
- 简单且高性能
- 高度可扩展,适用于大量流量
- 会话管理
- 优化的查找
弊
- 基本 CRUD
- 无法筛选值
- 缺乏索引和扫描功能
- 未针对复杂查询进行优化
例子
图
图形数据库是一种 NoSQL 数据库,它使用图形结构进行语义查询,其中包含节点、边缘和属性来表示和存储数据,而不是表或文档。
该图将存储中的数据项与节点和边的集合相关联,这些边表示节点之间的关系。这些关系允许将存储中的数据直接链接在一起,并且在许多情况下,只需一个操作即可检索。
优势
- 查询速度
- 敏捷灵活
- 显式数据表示
弊
- 复杂
- 没有标准化的查询语言
使用案例
- 欺诈检测
- 推荐引擎
- 社交网络
- 网络映射
例子
时间序列
时序数据库是针对带时间戳或时序的数据进行优化的数据库。
优势
- 快速插入和检索
- 高效的数据存储
使用案例
- IoT 数据
- 指标分析
- 应用程序监控
- 了解财务趋势
例子
宽柱
宽列数据库(也称为宽列存储)与架构无关。数据存储在列族中,而不是存储在行和列中。
优势
- 高度可扩展,可处理 PB 级数据
- 实时大数据应用的理想选择
弊
- 贵
- 写入时间增加
使用案例
- 业务分析
- 基于属性的数据存储
例子
多模型
多模型数据库将不同的数据库模型(即关系、图形、键值、文档等)组合到一个单一的集成后端中。这意味着它们可以容纳各种数据类型、索引、查询,并将数据存储在多个模型中。
优势
- 灵活性
- 适用于复杂项目
- 数据一致
弊
- 复杂
- 不太成熟
例子
SQL 与 NoSQL 数据库
在数据库领域,有两种主要类型的解决方案,SQL(关系)和 NoSQL(非关系)数据库。它们两者的构建方式、存储信息的类型以及存储方式都不同。关系数据库是结构化的,具有预定义的架构,而非关系数据库是非结构化的、分布式的,并且具有动态架构。
高级差异
以下是 SQL 和 NoSQL 之间的一些高级差异:
存储
SQL 将数据存储在表中,其中每行表示一个实体,每列表示有关该实体的数据点。
NoSQL数据库有不同的数据存储模型,如键值、图形、文档等。
图式
在 SQL 中,每条记录都符合一个固定的架构,这意味着必须在数据输入之前确定和选择列,并且每行必须包含每列的数据。架构可以在以后更改,但它涉及使用迁移修改数据库。
而在 NoSQL 中,模式是动态的。字段可以动态添加,并且每条记录(或等效记录)不必包含每个字段的数据。
查询
SQL数据库使用SQL(结构化查询语言)来定义和操作数据,非常强大。
在 NoSQL 数据库中,查询集中在文档集合上。不同的数据库具有不同的查询语法。
可扩展性
在大多数常见情况下,SQL 数据库是可垂直扩展的,这可能会变得非常昂贵。可以跨多个服务器扩展关系数据库,但这是一个具有挑战性且耗时的过程。
另一方面,NoSQL 数据库是可水平扩展的,这意味着我们可以轻松地将更多服务器添加到我们的 NoSQL 数据库基础设施中,以处理大量流量。任何廉价的商用硬件或云实例都可以托管 NoSQL 数据库,因此比垂直扩展更具成本效益。许多 NoSQL 技术还会自动在服务器之间分发数据。
可靠性
绝大多数关系数据库都符合 ACID 标准。因此,在数据可靠性和执行事务的安全保证方面,SQL 数据库仍然是更好的选择。
大多数 NoSQL 解决方案为了性能和可伸缩性而牺牲了 ACID 合规性。
原因
与往常一样,我们应该始终选择更符合要求的技术。因此,让我们看一下选择基于SQL或NoSQL的数据库的一些原因:
对于 SQL
- 具有严格架构的结构化数据
- 关系数据
- 需要复杂的联接
- 交易
- 按索引查找非常快
对于 NoSQL
- 动态或灵活的架构
- 非关系型数据
- 无需复杂的连接
- 数据密集型工作负载
- IOPS 的超高吞吐量
数据库复制
复制是一个过程,涉及共享信息以确保冗余资源(如多个数据库)之间的一致性,以提高可靠性、容错能力或可访问性。
主从复制
主服务器提供读取和写入服务,将写入复制到一个或多个仅提供读取服务的从服务器。从属服务器还可以以树状的方式复制其他从属服务器。如果主设备脱机,系统可以继续以只读模式运行,直到从设备升级为主设备或配置新的主设备。
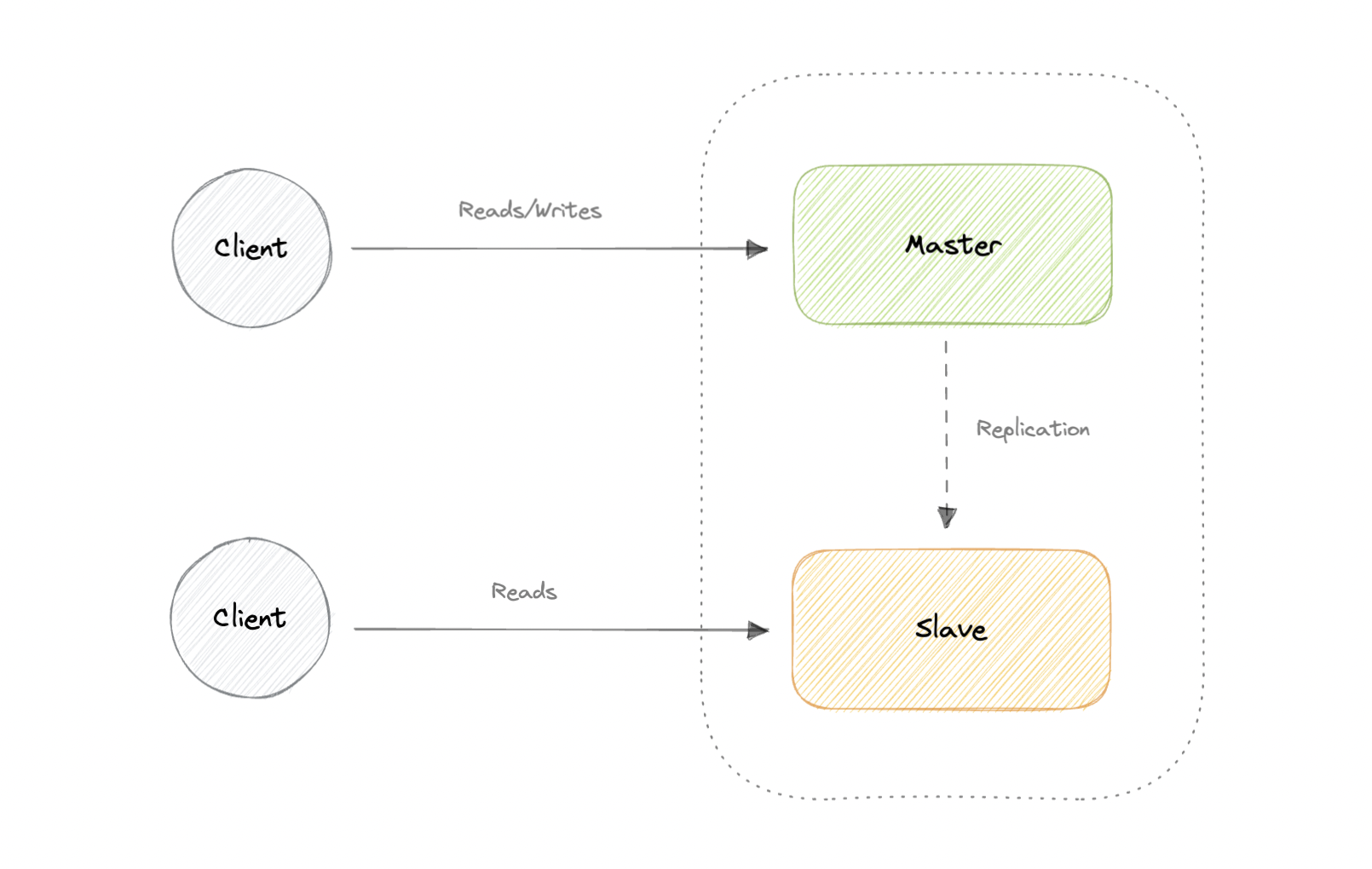
优势
- 备份整个数据库对主数据库相对没有影响。
- 应用程序可以从从站读取数据,而不会影响主站。
- 从站可以脱机并同步回主站,而无需任何停机时间。
弊
- 复制增加了更多的硬件和额外的复杂性。
- 当主站发生故障时,停机和可能丢失的数据。
- 在主从架构中,还必须对主设备进行所有写入。
- 读取从站越多,我们必须复制的就越多,这将增加复制滞后。
主-主复制
两个主服务器都提供读/写服务并相互协调。如果任一主设备出现故障,系统可以继续进行读取和写入操作。
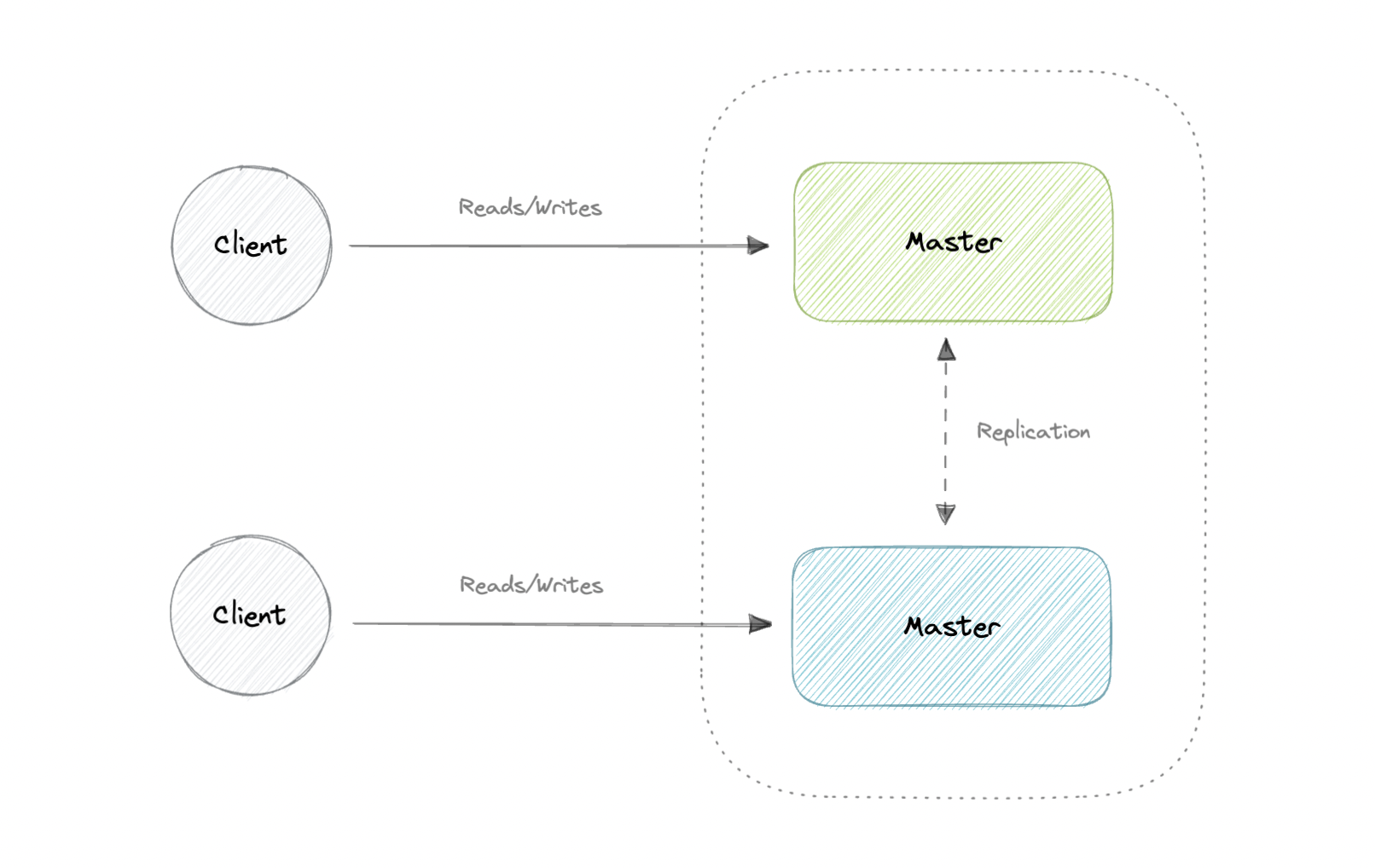
优势
- 应用程序可以从两个主节点读取数据。
- 在两个主节点之间分配写入负载。
- 简单、自动、快速的故障转移。
弊
- 不像主从配置和部署那么简单。
- 要么是松散的一致性,要么是由于同步而增加了写入延迟。
- 随着添加更多写入节点和延迟增加,冲突解决开始发挥作用。
同步复制与异步复制
同步复制和异步复制之间的主要区别在于如何将数据写入副本。在同步复制中,数据同时写入主存储和副本。因此,主副本和副本应始终保持同步。
相反,异步复制会在数据写入主存储后将数据复制到副本。尽管复制过程可能近乎实时地进行,但按计划进行复制更为常见,而且更具成本效益。
指标
索引在数据库方面是众所周知的,它们用于提高数据存储上数据检索操作的速度。索引在增加存储开销和较慢的写入(因为我们不仅必须写入数据,还必须更新索引)之间做出权衡,以获得更快的读取速度。索引用于快速查找数据,而无需检查数据库表中的每一行。可以使用数据库表的一列或多列创建索引,从而为快速随机查找和高效访问有序记录奠定了基础。
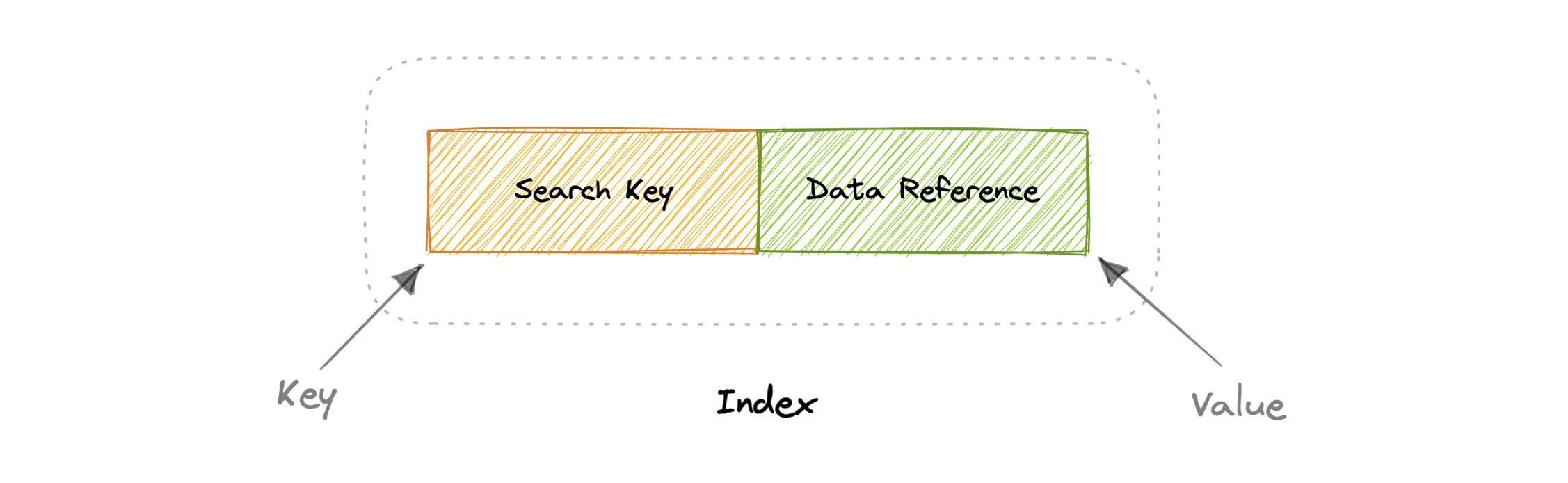
索引是一种数据结构,可以将其视为将我们指向实际数据所在的位置的目录。因此,当我们在表的列上创建索引时,我们会将该列和指向索引中整行的指针存储。索引还用于创建相同数据的不同视图。对于大型数据集,这是指定不同筛选器或排序方案的绝佳方法,而无需创建多个额外的数据副本。
数据库索引可以具有的一个特性是它们可以是密集的,也可以是稀疏的。这些指数质量中的每一个都有自己的权衡。让我们看看每种索引类型的工作方式:
密集指数
在密集索引中,为表的每一行创建一个索引记录。可以直接定位记录,因为索引的每条记录都包含搜索键值和指向实际记录的指针。
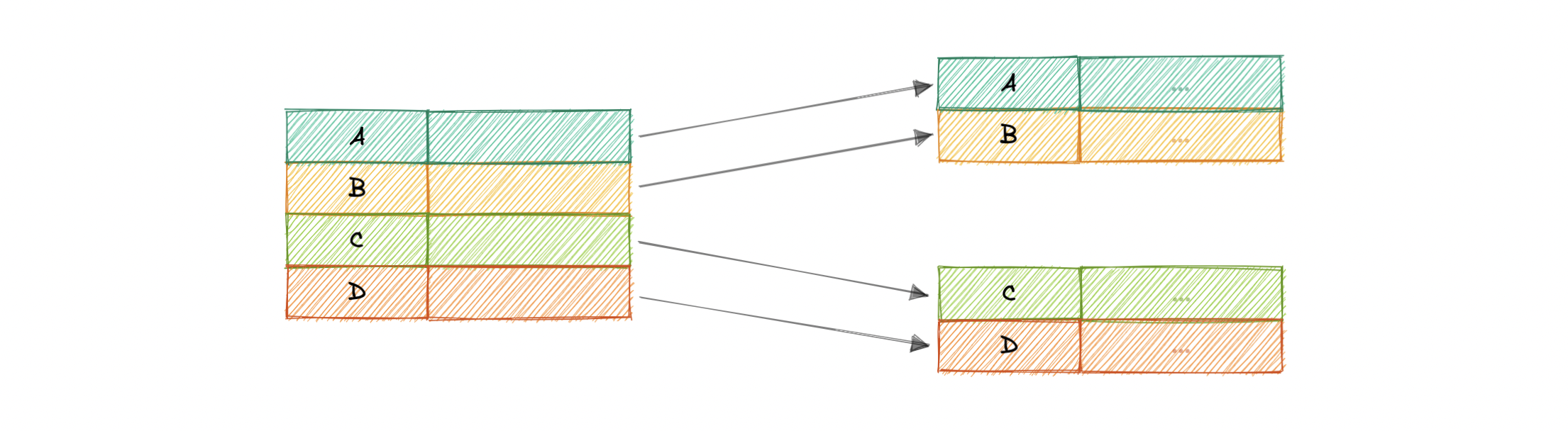
密集索引在写入时比稀疏索引需要更多的维护。由于每行都必须有一个条目,因此数据库必须在插入、更新和删除时维护索引。每行都有一个条目也意味着密集索引将需要更多的内存。密集索引的好处是,只需二进制搜索即可快速找到值。密集索引也不会对数据施加任何排序要求。
稀疏索引
在稀疏索引中,仅为某些记录创建记录。

稀疏索引在写入时比密集索引需要更少的维护,因为它们只包含值的子集。这种较轻的维护负担意味着插入、更新和删除将更快。条目较少还意味着索引将使用较少的内存。查找数据的速度较慢,因为整个页面的扫描通常遵循二进制搜索。在处理有序数据时,稀疏索引也是可选的。
规范化和非规范化
条款
在我们进一步讨论之前,让我们先看一下规范化和非规范化中的一些常用术语。
钥匙
主键:可用于唯一标识表的每一行的列或列组。
复合键:由多个列组成的主键。
超级键:可以唯一标识表中所有行的所有键的集合。
候选键:在表中唯一标识行的属性。
外键:它是对另一个表的主键的引用。
备用键:非主键的键称为备用键。
代理键:系统生成的值,当没有其他列能够保存主键的属性时,该值唯一标识表中的每个条目。
依赖
部分依赖性:当主键确定某些其他属性时发生。
功能依赖:它是存在于两个属性之间的关系,通常存在于表中的主键和非键属性之间。
传递函数依赖关系:当某些非键属性决定其他属性时发生。
异常
当数据库中由于不正确的规划或将所有内容存储在平面数据库中而导致存在缺陷时,就会发生数据库异常。这通常通过规范化过程来解决。
有三种类型的数据库异常:
插入异常:当我们无法在数据库中插入某些属性而没有其他属性时,就会发生。
更新异常:在数据冗余和部分更新的情况下发生。换言之,数据库的正确更新需要其他操作,例如添加和/或删除。
删除异常:在删除某些数据需要删除其他数据时发生。
例
让我们考虑下表,该表未规范化:
| 编号 | 名字 | 角色 | 团队 |
|---|---|---|---|
| 1 | 彼得 | 软件工程师 | 一个 |
| 2 | 布莱恩 | DevOps工程师 | B |
| 3 | 海利 | 产品经理 | C |
| 4 | 海利 | 产品经理 | C |
| 5 | 史蒂夫 | 前端工程师 | D |
让我们想象一下,我们雇用了一个新人“约翰”,但他们可能不会立即被分配一个团队。这将导致插入异常,因为团队属性尚不存在。
接下来,假设 C 团队的 Hailey 晋升了,为了反映数据库中的这种变化,我们需要更新 2 行以保持一致性,这可能会导致更新异常。
最后,我们想删除团队 B,但要做到这一点,我们还需要删除其他信息,例如名称和角色,这是删除异常的一个示例。
正常化
规范化是在数据库中组织数据的过程。这包括创建表,并根据旨在保护数据并通过消除冗余和不一致依赖关系使数据库更加灵活的规则在这些表之间建立关系。
为什么我们需要规范化?
规范化的目标是消除冗余数据并确保数据一致。完全规范化的数据库允许扩展其结构以适应新类型的数据,而无需过多地更改现有结构。因此,与数据库交互的应用程序受到的影响最小。
正常形式
普通形式是确保数据库规范化的一系列准则。让我们讨论一些基本的范式:
1NF系列
对于第一范式 (1NF) 的表,它应遵循以下规则:
- 不允许重复组。
- 使用主键标识每组相关数据。
- 相关数据集应具有单独的表。
- 不允许在同一列中混合数据类型。
2NF型
对于采用第二范式 (2NF) 的表,它应遵循以下规则:
- 满足第一范式 (1NF)。
- 不应有任何部分依赖关系。
3NF系列
对于采用第三范式 (3NF) 的表,它应遵循以下规则:
- 满足第二范式 (2NF)。
- 不允许传递功能依赖关系。
BCNF系列
Boyce-Codd 范式(或 BCNF)是第三范式 (3NF) 的稍强版本,用于解决最初定义的 3NF 未处理的某些类型的异常。有时它也被称为 3.5 正常形式 (3.5NF)。
对于采用 Boyce-Codd 范式 (BCNF) 的表,它应遵循以下规则:
- 满足第三范式(3NF)。
- 对于每个功能依赖项 X → Y,X 应该是超级键。
还有更多正常形式,例如 4NF、5NF 和 6NF,但我们不会在这里讨论它们。看看这个精彩的视频,里面有详细的信息。
在关系数据库中,如果关系满足第三范式,则通常将其描述为“规范化”。大多数 3NF 关系没有插入、更新和删除异常。
与许多正式的规则和规范一样,实际场景并不总是允许完全合规。如果决定违反规范化的前三个规则之一,请确保应用程序预见到可能发生的任何问题,例如冗余数据和不一致的依赖项。
优势
以下是规范化的一些优点:
- 减少数据冗余。
- 更好的数据设计。
- 提高数据一致性。
- 强制执行引用完整性。
弊
让我们看一下归一化的一些缺点:
- 数据设计很复杂。
- 性能较慢。
- 维护开销。
- 需要更多联接。
非规范化
非规范化是一种数据库优化技术,其中我们将冗余数据添加到一个或多个表中。这可以帮助我们避免在关系数据库中进行成本高昂的联接。它想以牺牲一些写入性能为代价来提高读取性能。数据的冗余副本写入多个表中,以避免成本高昂的联接。
一旦数据通过联合和分片等技术进行分发,管理整个网络的联接将进一步增加复杂性。非规范化可能会规避对这种复杂连接的需求。
注意:非规范化并不意味着反转规范化。
优势
让我们看一下非规范化的一些优点:
- 检索数据的速度更快。
- 编写查询更容易。
- 减少表的数量。
- 管理方便。
弊
以下是非规范化的一些缺点:
- 昂贵的插入和更新。
- 增加了数据库设计的复杂性。
- 增加数据冗余。
- 数据不一致的可能性更大。
ACID 和 BASE 一致性模型
让我们讨论一下 ACID 和 BASE 一致性模型。
酸
术语 ACID 代表原子性、一致性、隔离性和持久性。ACID 属性用于在事务处理期间维护数据完整性。
为了在事务之前和之后保持一致性,关系数据库遵循 ACID 属性。让我们了解这些术语:
原子
事务中的所有操作都成功或每个操作都回滚。
一致
事务完成后,数据库在结构上是健全的。
孤立
事务之间不会相互竞争。对数据的有争议的访问由数据库进行调节,以便事务看起来按顺序运行。
耐用
一旦事务完成并且写入和更新已写入磁盘,即使发生系统故障,它仍将保留在系统中。
基础
随着数据量的增加和高可用性要求的增加,数据库设计方法也发生了巨大变化。为了提高扩展能力,同时保持高可用性,我们将逻辑从数据库移动到单独的服务器。这样,数据库变得更加独立,并专注于存储数据的实际过程。
在 NoSQL 数据库世界中,ACID 事务不太常见,因为一些数据库已经放宽了对即时一致性、数据新鲜度和准确性的要求,以获得其他好处,如规模和弹性。
BASE 属性比 ACID 保证的要宽松得多,但两个一致性模型之间没有直接的一对一映射。让我们了解这些术语:
基本可用性
数据库似乎大部分时间都在工作。
软状态
存储不必是写入一致性的,不同的副本也不必始终相互一致。
最终一致性
数据可能不会立即保持一致,但最终会变得一致。系统中的读取仍然是可能的,即使它们可能由于不一致而无法给出正确的响应。
ACID 与 BASE 的权衡
对于我们的应用程序是否需要 ACID 或 BASE 一致性模型,没有正确的答案。这两种型号都旨在满足不同的要求。在选择数据库时,我们需要牢记模型的属性和应用程序的要求。
鉴于 BASE 的松散一致性,如果开发人员为其应用程序选择 BASE 存储,则需要对一致性数据更加了解和严格。熟悉所选数据库的 BASE 行为并在这些约束下工作至关重要。
另一方面,与 ACID 事务的简单性相比,围绕 BASE 限制进行规划有时可能是一个主要缺点。完全 ACID 数据库非常适合数据可靠性和一致性至关重要的用例。
CAP定理
CAP 定理指出,分布式系统只能提供三个所需特征中的两个:一致性、可用性和分区容错 (CAP)。
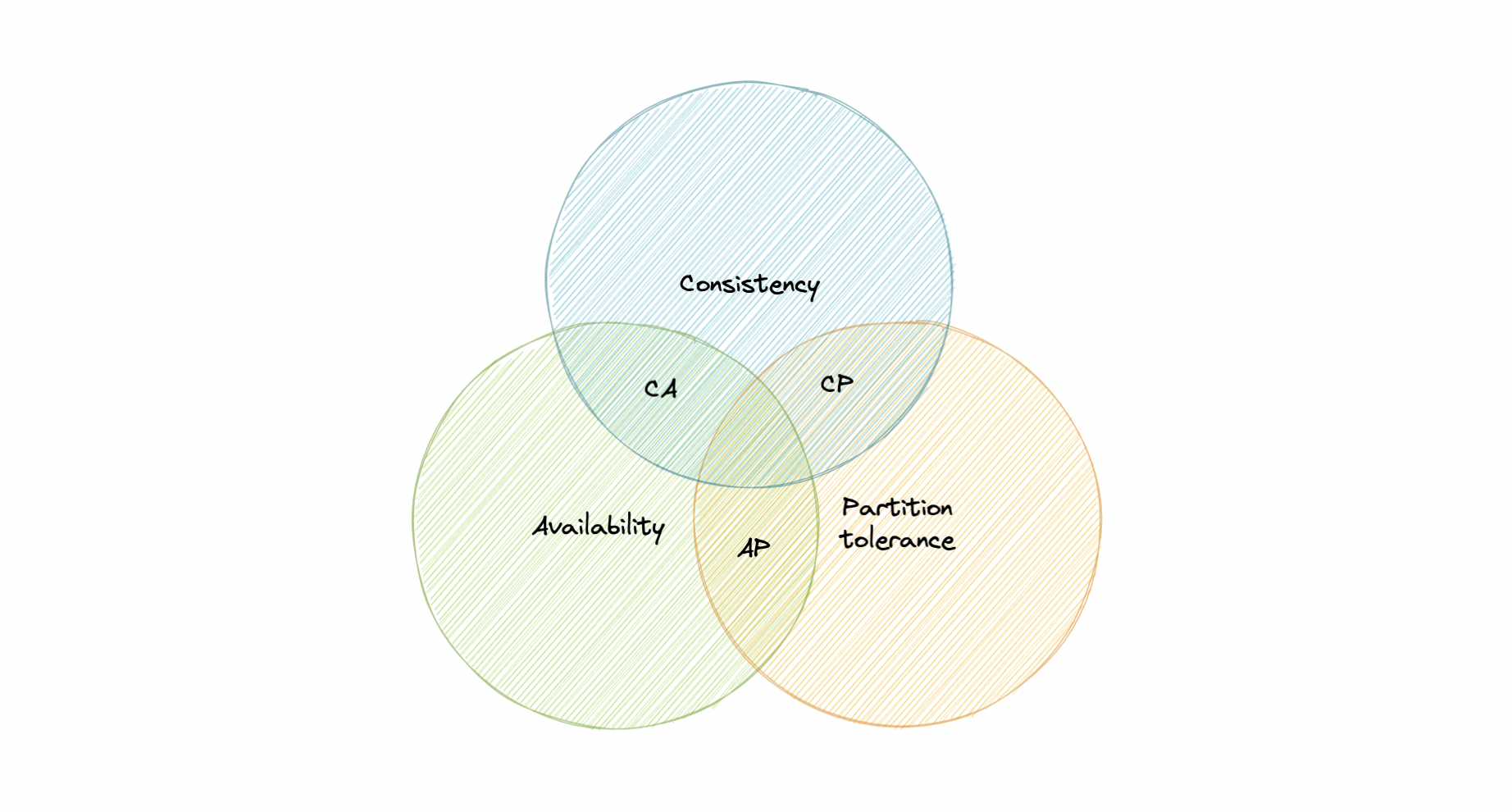
让我们详细了解一下 CAP 定理所指的三个分布式系统特征。
一致性
一致性意味着所有客户端都在同一时间看到相同的数据,无论它们连接到哪个节点。为此,每当将数据写入一个节点时,都必须立即将其转发或复制到系统中的所有节点,然后才能将写入视为“成功”。
可用性
可用性意味着任何发出数据请求的客户端都会得到响应,即使一个或多个节点已关闭也是如此。
分区容错
分区容错意味着即使消息丢失或部分故障,系统仍能继续工作。分区容错系统可以承受任何数量的网络故障,而不会导致整个网络故障。数据在节点和网络组合之间充分复制,以保持系统在间歇性中断期间正常运行。
一致性-可用性权衡
我们生活在一个物理世界,无法保证网络的稳定性,所以分布式数据库必须选择分区容错(P)。这意味着在一致性 (C) 和可用性 (A) 之间进行权衡。
CA 数据库
CA 数据库可在所有节点之间提供一致性和可用性。如果系统中的任何两个节点之间存在分区,则无法执行此操作,因此无法提供容错能力。
CP 数据库
CP 数据库以牺牲可用性为代价来提供一致性和分区容错性。当任意两个节点之间发生分区时,系统必须关闭不一致的节点,直到分区解析为止。
示例:MongoDB、Apache HBase。
AP 数据库
AP 数据库以牺牲一致性为代价来提供可用性和分区容错性。当发生分区时,所有节点都保持可用,但位于分区错误端的节点可能会返回比其他节点更旧版本的数据。解析分区后,AP 数据库通常会重新同步节点以修复系统中的所有不一致。
PACELC定理
PACELC 定理是 CAP 定理的扩展。CAP 定理指出,在分布式系统中进行网络分区 (P) 的情况下,必须在可用性 (A) 和一致性 (C) 之间进行选择。
PACELC 通过引入延迟 (L) 作为分布式系统的附加属性来扩展 CAP 定理。该定理指出,否则(E),即使系统在没有分区的情况下正常运行,也必须在延迟(L)和一致性(C)之间做出选择。
PACELC定理最早由Daniel J. Abadi描述。
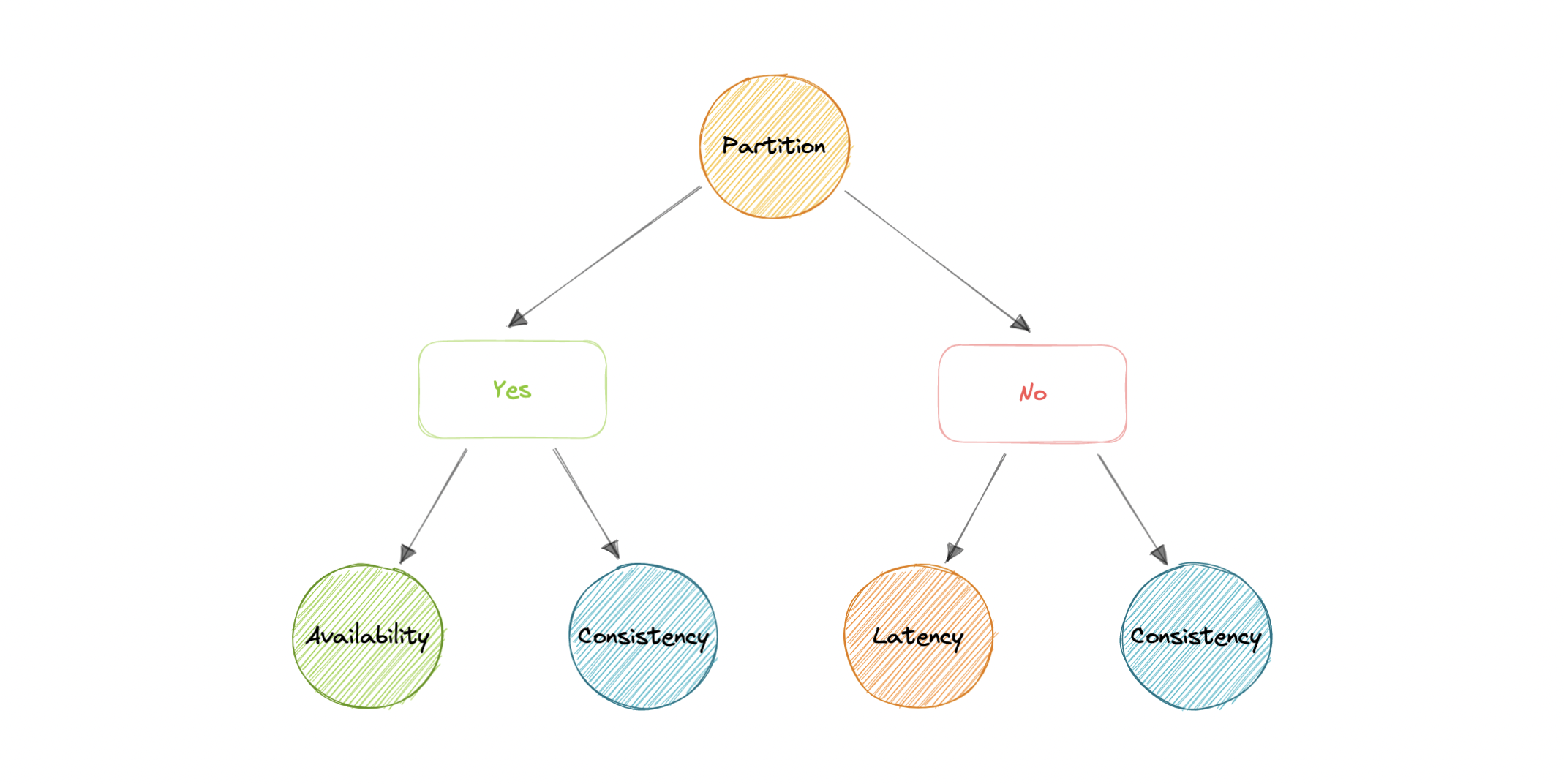
PACELC 定理的开发是为了解决 CAP 定理的一个关键限制,因为它没有提供性能或延迟。
例如,根据 CAP 定理,如果查询在 30 天后返回响应,则可以认为数据库可用。显然,对于任何实际应用程序来说,这种延迟都是不可接受的。
交易
事务是一系列被视为“单个工作单元”的数据库操作。事务中的操作要么全部成功,要么全部失败。这样,当系统的一部分发生故障时,事务的概念支持数据完整性。并非所有数据库都选择支持 ACID 事务,通常是因为它们优先考虑其他难以或理论上不可能一起实现的优化。
通常,关系数据库支持 ACID 事务,而非关系数据库不支持(也有例外)。
国家
数据库中的事务可以处于以下状态之一:
![]()
积极
在此状态下,正在执行事务。这是每个事务的初始状态。
部分承诺
当事务执行其最终操作时,它被称为处于部分提交状态。
承诺
如果一个事务成功执行了它的所有操作,则称它已被提交。它的所有效果现在都永久地建立在数据库系统上。
失败
如果数据库恢复系统所做的任何检查失败,则称该事务处于失败状态。失败的事务无法再继续进行。
中止
如果任何检查失败并且事务已达到失败状态,则恢复管理器将回滚其对数据库的所有写入操作,以使数据库恢复到执行事务之前的原始状态。处于此状态的事务将中止。
数据库恢复模块可以在事务中止后选择以下两个操作之一:
- 重新启动事务
- 终止交易
终止
如果没有任何回滚或事务来自已提交状态,则系统是一致的,并准备好进行新事务,并且旧事务将终止。
分布式事务
分布式事务是跨两个或多个数据库对数据执行的一组操作。它通常在通过网络连接的单独节点之间进行协调,但也可能跨越单个服务器上的多个数据库。
为什么我们需要分布式事务?
与单个数据库上的 ACID 事务不同,分布式事务涉及更改多个数据库上的数据。因此,分布式事务处理更加复杂,因为数据库必须将事务中更改的提交或回滚作为一个独立的单元进行协调。
换句话说,所有节点都必须提交,或者所有节点都必须中止,整个事务都会回滚。这就是我们需要分布式事务的原因。
现在,让我们看一些流行的分布式事务解决方案:
两阶段提交
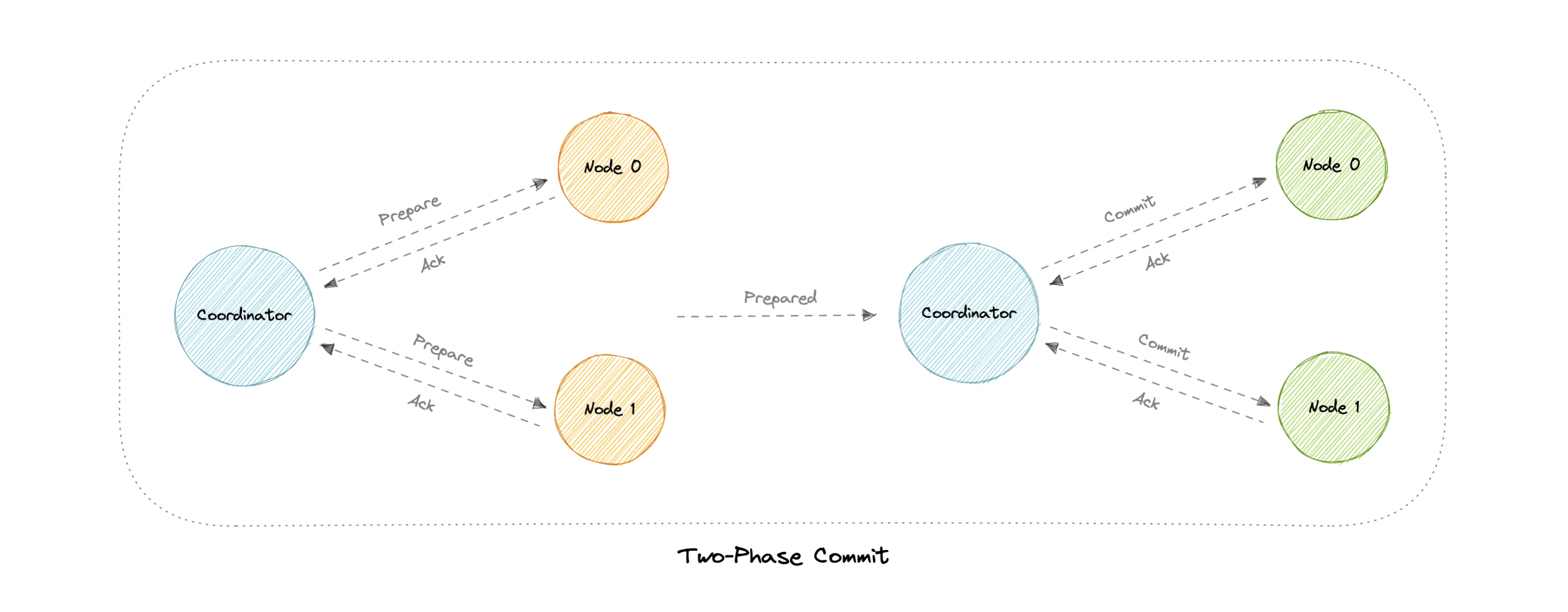
两阶段提交 (2PC) 协议是一种分布式算法,用于协调参与分布式事务的所有进程,以确定是提交还是中止(回滚)事务。
即使在许多临时系统故障的情况下,该协议也能实现其目标,因此被广泛使用。但是,它无法适应所有可能的故障配置,在极少数情况下,需要手动干预来纠正结果。
该协议需要一个协调节点,它基本上协调和监督不同节点之间的交易。协调员想在两个阶段的一组流程之间建立共识,因此得名。
阶段
两阶段提交包括以下阶段:
准备阶段
准备阶段涉及协调器节点从每个参与者节点收集共识。除非每个节点都响应它们已准备好,否则事务将被中止。
提交阶段
如果所有参与者都响应协调器,表示他们已准备好,则协调器会要求所有节点提交事务。如果发生故障,事务将回滚。
问题
在两阶段提交协议中可能会出现以下问题:
- 如果其中一个节点崩溃怎么办?
- 如果协调器本身崩溃怎么办?
- 它是一种阻塞协议。
三阶段提交
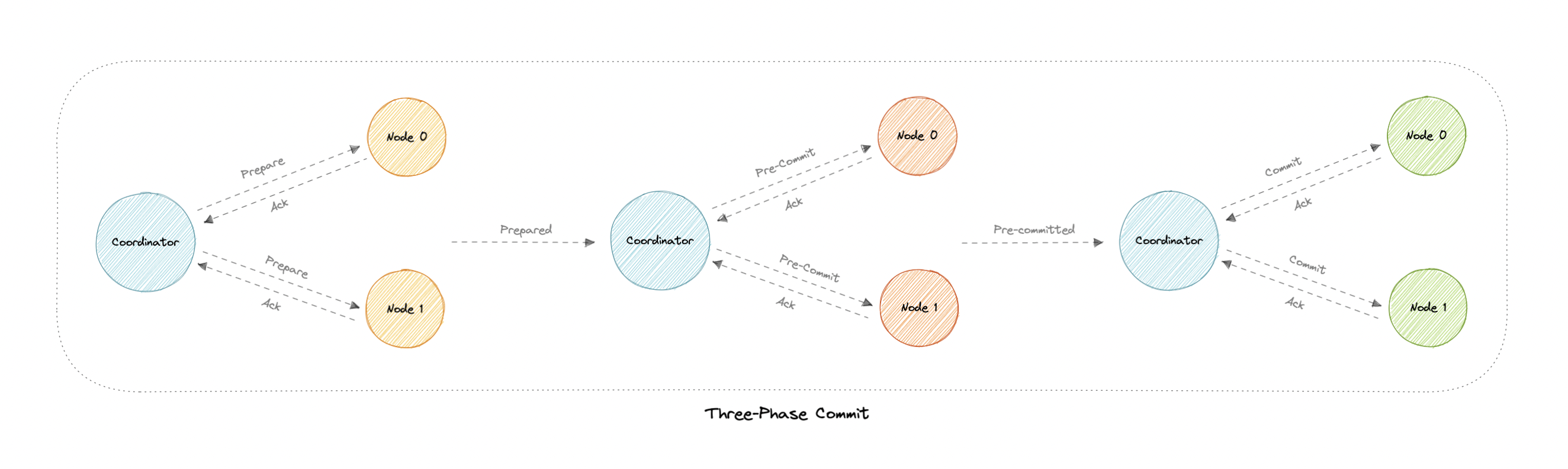
三阶段提交 (3PC) 是两阶段提交的扩展,其中提交阶段分为两个阶段。这有助于解决两阶段提交协议中出现的阻塞问题。
阶段
三阶段提交包括以下阶段:
准备阶段
此阶段与两阶段提交相同。
预提交阶段
协调器发出预提交消息,所有参与节点都必须确认它。如果参与者未能及时收到此消息,则交易将中止。
提交阶段
此步骤也类似于两阶段提交协议。
为什么提交前阶段有帮助?
提交前阶段完成以下任务:
- 如果在此阶段找到参与者节点,则意味着每个参与者都已完成第一阶段。准备阶段的完成是有保证的。
- 现在,每个阶段都可以超时并避免无限期等待。
传说
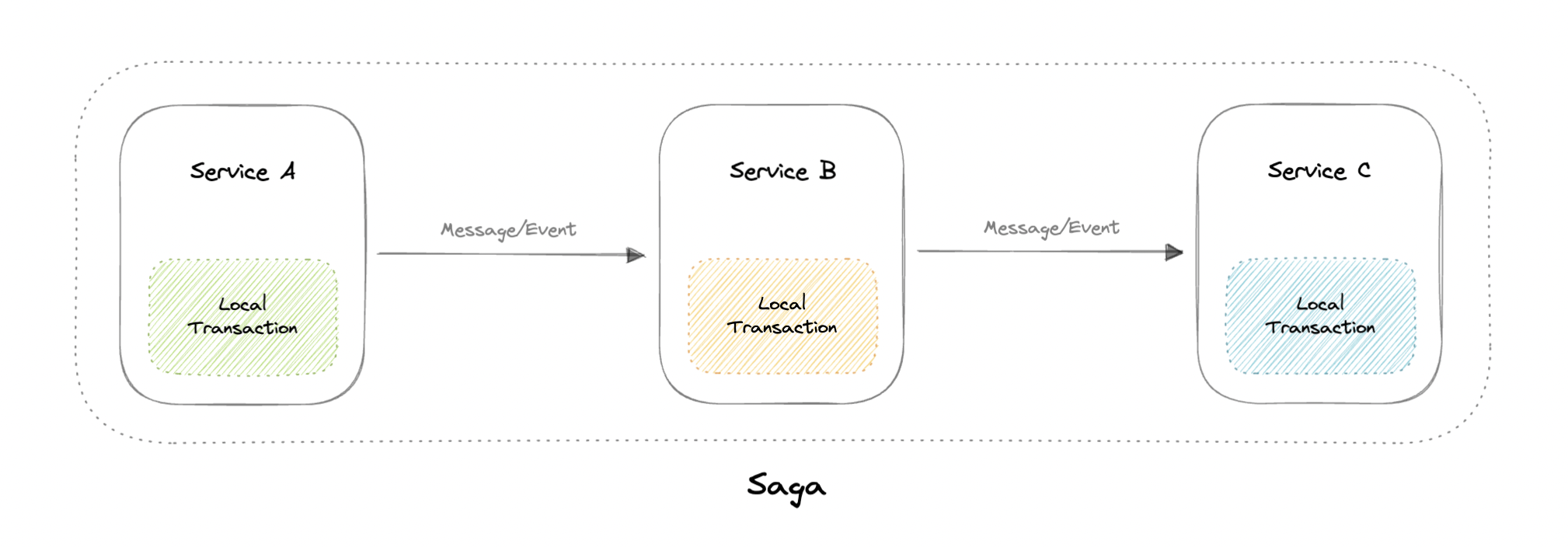
saga 是一系列本地事务。每个本地事务都会更新数据库并发布一条消息或事件,以触发 saga 中的下一个本地事务。如果本地事务因违反业务规则而失败,则 saga 将执行一系列补偿事务,以撤消先前的本地事务所做的更改。
协调
有两种常见的实现方法:
- 编排:每个本地事务都会发布域事件,这些事件会触发其他服务中的本地事务。
- 业务流程:业务流程协调程序告诉参与者要执行哪些本地事务。
问题
- Saga 模式特别难以调试。
- saga 参与者之间存在周期性依赖性的风险。
- 缺乏参与者数据隔离会给持久性带来挑战。
- 测试很困难,因为必须运行所有服务才能模拟事务。
分片
在讨论分片之前,我们先来谈谈数据分区:
数据分区
数据分区是一种将数据库分解为许多较小部分的技术。它是在多台计算机上拆分数据库或表以提高数据库的可管理性、性能和可用性的过程。
方法
有许多不同的方法可用于决定如何将应用程序数据库分解为多个较小的数据库。 以下是各种大型应用程序使用的两种最流行的方法:
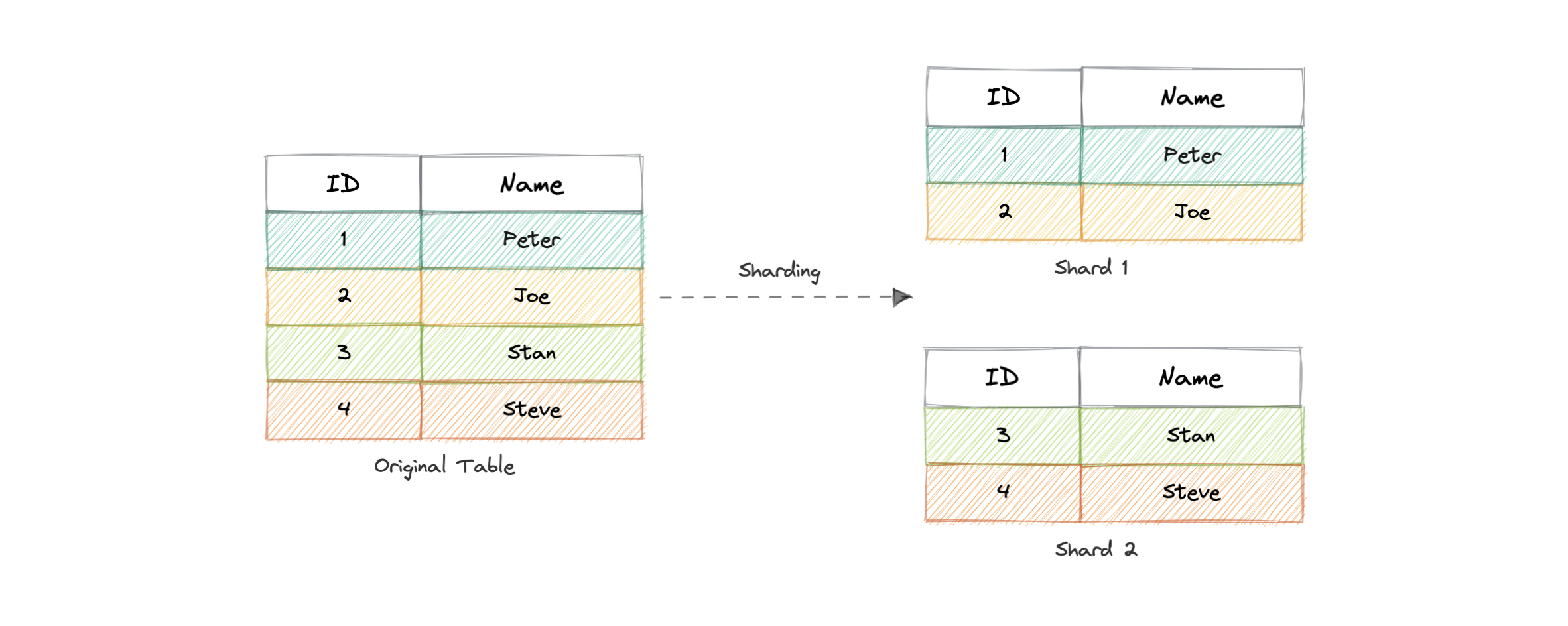
水平分区(或分片)
在此策略中,我们根据分区键定义的值范围水平拆分表数据。它也称为数据库分片。
垂直分区
在垂直分区中,我们根据列对数据进行垂直分区。我们将表划分为具有很少元素的相对较小的表,并且每个部分都存在于单独的分区中。
在本教程中,我们将特别关注分片。
什么是分片?
分片是一种与水平分区相关的数据库架构模式,水平分区是将一个表的行分成多个不同的表(称为分区或分片)的做法。每个分区都具有相同的架构和列,但也有共享数据的子集。同样,每个分区中保存的数据都是唯一的,并且独立于其他分区中保存的数据。
数据分片的理由是,在某个时间点之后,通过添加更多机器进行水平扩展比通过添加强大的服务器进行垂直扩展更便宜、更可行。分片可以在应用程序或数据库级别实现。
分区条件
有大量可用于数据分区的条件。一些最常用的标准是:
基于哈希
此策略基于哈希算法将行划分为不同的分区,而不是基于连续索引对数据库行进行分组。
此方法的缺点是动态添加/删除数据库服务器的成本会很高。
基于列表
在基于列表的分区中,每个分区都是根据列上的值列表而不是一组连续的值范围来定义和选择的。
基于范围
范围分区根据分区键的值范围将数据映射到各个分区。换句话说,我们以这样一种方式对表进行分区,即每个分区都包含分区键定义的给定范围内的行。
范围应该是连续的,但不能重叠,其中每个范围都指定分区的非包容性下限和上限。任何等于或高于范围上限的分区键值都将添加到下一个分区。
复合
顾名思义,复合分区基于两种或多种分区技术对数据进行分区。在这里,我们首先使用一种技术对数据进行分区,然后使用相同或其他方法将每个分区进一步细分为子分区。
优势
但是为什么我们需要分片呢?以下是一些优点:
- 可用性:为分区数据库提供逻辑独立性,确保应用程序的高可用性。在这里,各个分区可以独立管理。
- 可伸缩性:证明通过跨多个分区分布数据来提高可伸缩性。
- 安全性:通过将敏感和非敏感数据存储在不同的分区中来帮助提高系统的安全性。这可以为敏感数据提供更好的可管理性和安全性。
- 查询性能:提高系统性能。现在,系统无需查询整个数据库,只需查询较小的分区。
- 数据可管理性:将表和索引划分为更小、更易于管理的单元。
弊
- 复杂性:分片通常会增加系统的复杂性。
- 跨分片联接:一旦数据库被分区并分布在多台计算机上,执行跨多个数据库分片的联接通常不可行。这种联接不会提高性能效率,因为必须从多个服务器检索数据。
- 重新平衡:如果数据分布不均匀或单个分片上存在大量负载,在这种情况下,我们必须重新平衡分片,以便请求尽可能平均地分布在分片之间。
何时使用分片?
以下是分片可能是正确的选择的一些原因:
- 利用现有硬件而不是高端机器。
- 在不同的地理区域维护数据。
- 通过添加更多分片来快速扩展。
- 性能更好,因为每台机器的负载都更少。
- 当需要更多并发连接时。
一致的哈希
让我们首先了解我们要解决的问题。
我们为什么需要这个?
在传统的基于哈希的分发方法中,我们使用哈希函数来对分区键(即请求 ID 或 IP)进行哈希处理。然后,如果我们对节点总数(服务器或数据库)使用模。这将为我们提供要路由请求的节点。
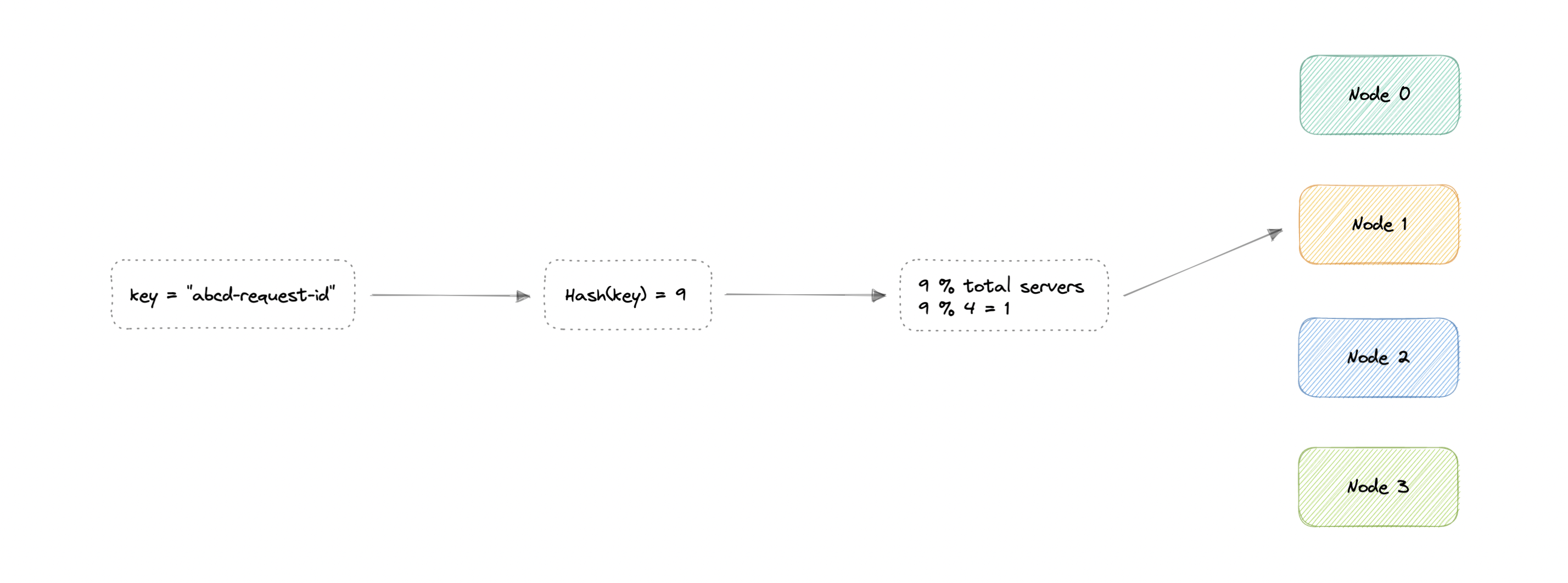
$$ \begin{align*} & hash(key_1) \to H_1 \bmod n = Node_0 \ & Hash(key_2) \to H_2 \bmod N = Node_1 \ & Hash(key_3) \to H_3 \bmod N = Node_2 \ & ... \ & Hash(key_n) \to H_n \bmod N = Node_{n-1} \end{align*} $$
哪里
key:请求 ID 或 IP。
H:哈希函数结果。
N:节点总数。
Node:将路由请求的节点。
这样做的问题是,如果我们添加或删除一个节点,它将导致更改,这意味着我们的映射策略将中断,因为相同的请求现在将映射到不同的服务器。因此,大多数请求都需要重新分发,效率非常低。
N
我们希望在不同的节点之间统一分配请求,以便我们应该能够以最小的努力添加或删除节点。因此,我们需要一个不直接依赖于节点(或服务器)数量的分配方案,以便在添加或删除节点时,将需要重新定位的密钥数量降至最低。
一致的哈希处理解决了这个水平可伸缩性问题,确保每次我们向上或向下扩展时,我们不必重新排列所有键或接触所有服务器。
现在我们了解了问题所在,让我们详细讨论一致性哈希。
它是如何工作的
一致哈希是一种分布式哈希方案,它通过在抽象圆圈或哈希环上为节点分配一个位置,独立于分布式哈希表中的节点数运行。这允许服务器和对象在不影响整个系统的情况下进行扩展。
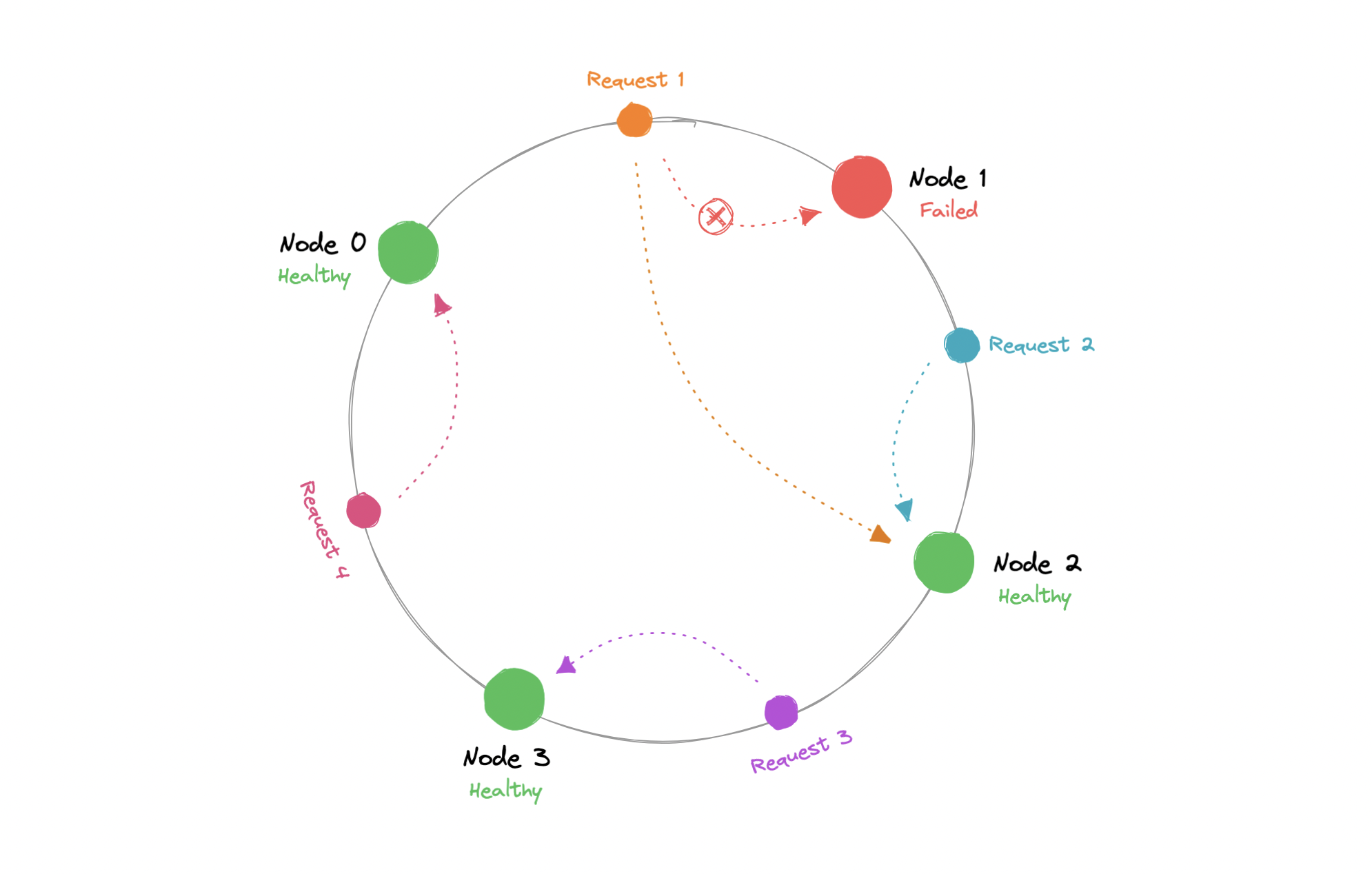
使用一致的哈希,只有数据需要重新分发。
K/N
$$ R = K/N $$
哪里
R:需要重新分发的数据。
K:分区键数。
N:节点数。
哈希函数的输出是一个范围,比方说我们可以在哈希环上表示。我们对请求进行哈希处理,并根据输出结果将它们分布在环上。同样,我们也对节点进行哈希处理,并将它们分布在同一个环上。
0...m-1
$$ \begin{align*} & Hash(key_1) = P_1 \ & Hash(key_2) = P_2 \ & Hash(key_3) = P_3 \ & ... \ & Hash(key_n) = P_{m-1} \end{align*} $$
哪里
key:请求/节点 ID 或 IP。
P:在哈希环上的位置。
m:哈希环的总范围。
现在,当请求传入时,我们可以简单地以顺时针(也可以逆时针)的方式将其路由到最近的节点。这意味着,如果添加或删除了新节点,我们可以使用最近的节点,并且只需要重新路由一小部分请求。
从理论上讲,一致的哈希应该均匀地分配负载,但在实践中不会发生。通常,负载分布是不均匀的,一台服务器最终可能会处理大部分请求成为热点,这基本上是系统的瓶颈。我们可以通过添加额外的节点来解决这个问题,但这可能很昂贵。
让我们看看如何解决这些问题。
虚拟节点
为了确保负载分布更均匀,我们可以引入虚拟节点的概念,有时也称为 VNode。
哈希范围不是为节点分配单个位置,而是划分为多个较小的范围,并且每个物理节点都分配了几个较小的范围。这些子范围中的每一个都被视为一个 VNode。因此,虚拟节点基本上是在哈希环中多次映射的现有物理节点,以最大程度地减少对节点分配范围的更改。
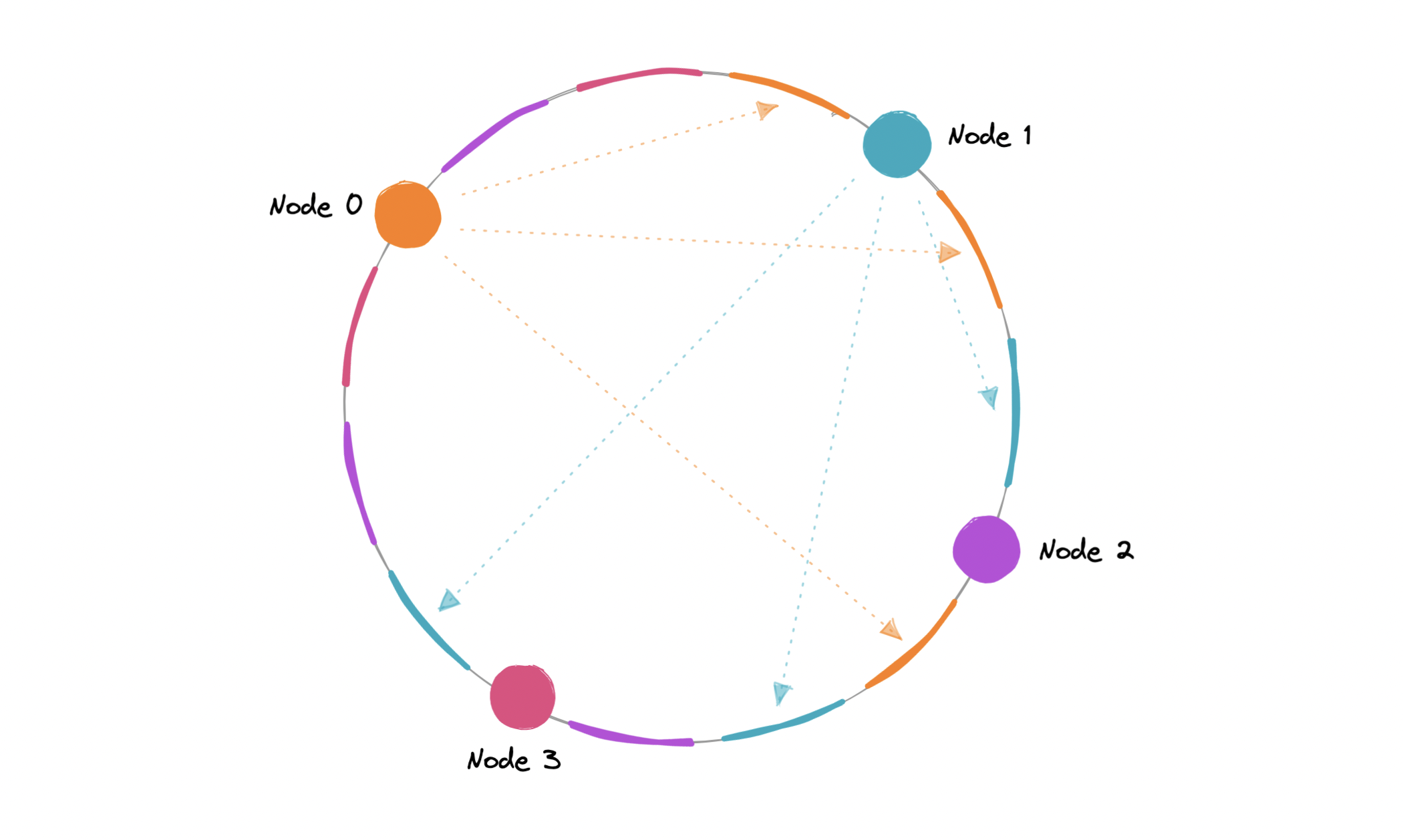
为此,我们可以使用哈希函数的数量。
k
$$ \begin{align*} & Hash_1(key_1) = P_1 \ & Hash_2(key_2) = P_2 \ & Hash_3(key_3) = P_3 \ & . . . \ & Hash_k(key_n) = P_{m-1} \end{align*} $$
哪里
key:请求/节点 ID 或 IP。
k:哈希函数的数量。
P:在哈希环上的位置。
m:哈希环的总范围。
由于 VNode 通过将哈希范围细分为更小的子范围来帮助将负载更均匀地分布在集群上的物理节点上,因此这加快了添加或删除节点后的重新平衡过程。这也有助于我们降低热点的概率。
数据复制
为了确保高可用性和持久性,一致哈希将每个数据项复制到系统中的多个节点上,其中的值等同于复制因子。
N
N
复制因子是将接收相同数据副本的节点数。在最终一致性系统中,这是异步完成的。
优势
让我们看一下一致性哈希的一些优点:
- 使快速扩展和缩减更具可预测性。
- 便于跨节点进行分区和复制。
- 实现可扩展性和可用性。
- 减少热点。
弊
以下是一致性哈希的一些缺点:
- 增加复杂性。
- 级联故障。
- 负载分布仍然不均匀。
- 当节点暂时发生故障时,密钥管理可能会很昂贵。
例子
让我们看一些使用一致哈希的示例:
- Apache Cassandra 中的数据分区。
- 在 Amazon DynamoDB 中的多个存储主机之间分配负载。
数据库联合
联合(或功能分区)按功能拆分数据库。联合体系结构使多个不同的物理数据库在最终用户看来是一个逻辑数据库。
联合中的所有组件都由一个或多个联邦架构绑定在一起,这些架构表示整个联盟中数据的通用性。这些联合架构用于指定联合组件可以共享的信息,并为它们之间的通信提供通用基础。
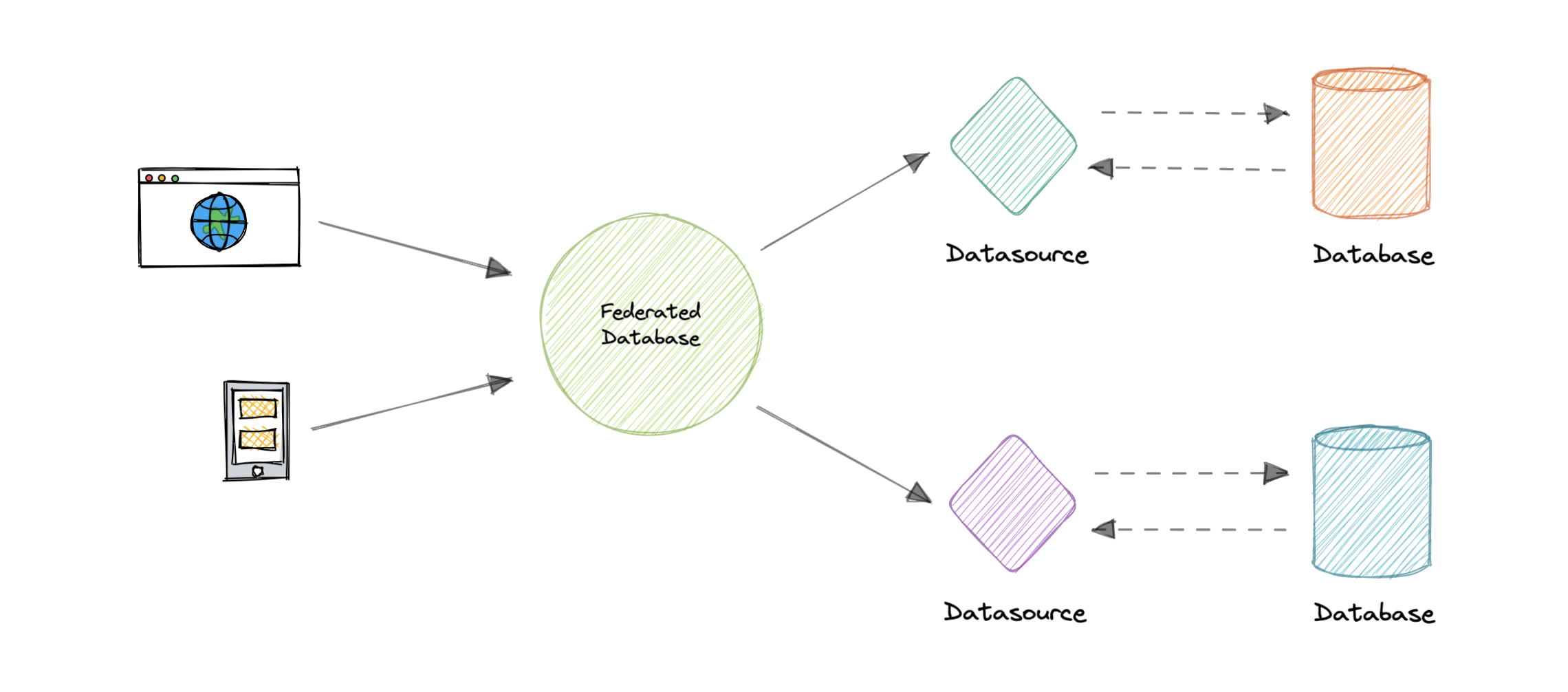
联合还为派生自多个源的数据提供了一致的统一视图。联合系统的数据源可以包括数据库和各种其他形式的结构化和非结构化数据。
特性
让我们看一下联合数据库的一些关键特征:
- 透明度:联合数据库掩盖了用户差异和基础数据源的实现。因此,用户不需要知道数据的存储位置。
- 异构性:数据源可能在许多方面有所不同。联合数据库系统可以处理不同的硬件、网络协议、数据模型等。
- 可扩展性:可能需要新的源来满足不断变化的业务需求。一个好的联合数据库系统需要使添加新源变得容易。
- 自治:联合数据库不会更改现有数据源,接口应保持不变。
- 数据集成:联合数据库可以集成来自不同协议、数据库管理系统等的数据。
优势
以下是联合数据库的一些优点:
- 灵活的数据共享。
- 数据库组件之间的自治性。
- 统一访问异构数据。
- 没有应用程序与旧数据库的紧密耦合。
弊
以下是联合数据库的一些缺点:
- 增加更多硬件和复杂性。
- 联接来自两个数据库的数据很复杂。
- 对自治数据源的依赖。
- 查询性能和可伸缩性。
N 层体系结构
N 层体系结构将应用程序划分为逻辑层和物理层。层是分离职责和管理依赖关系的一种方式。每一层都有特定的职责。较高层可以使用较低层中的服务,但反之则不行。
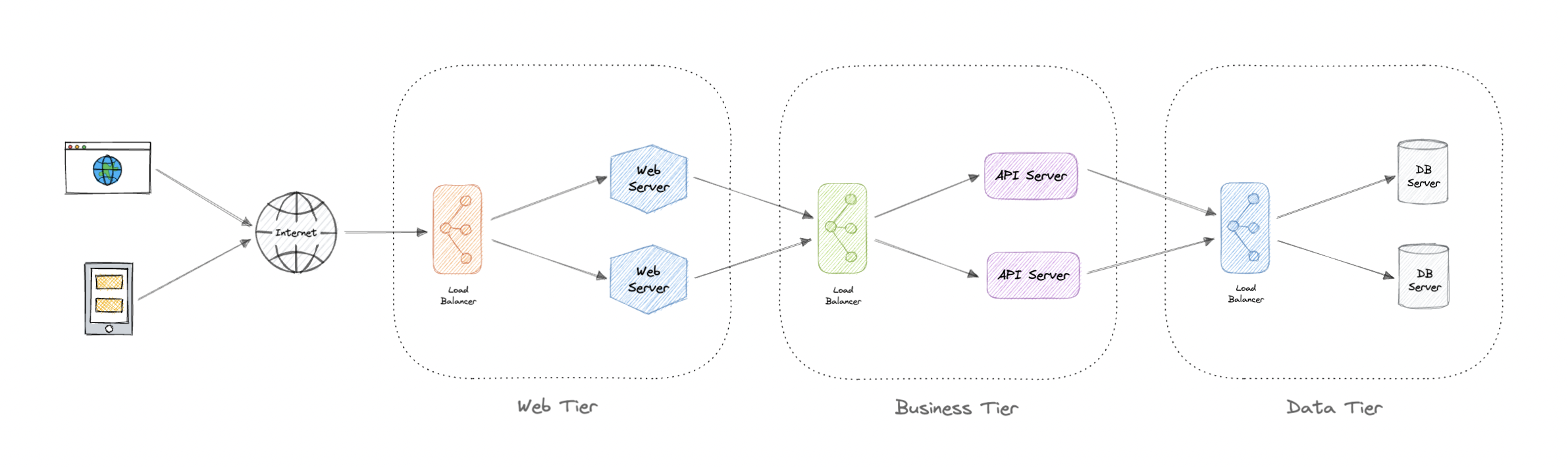
层在物理上是分开的,在单独的计算机上运行。一个层可以直接调用另一个层,也可以使用异步消息传递。尽管每个层都可能托管在自己的层中,但这不是必需的。多个图层可能托管在同一层上。以物理方式分隔各层可提高可伸缩性和复原能力,并增加其他网络通信的延迟。
N 层体系结构可以有两种类型:
- 在封闭层架构中,一层只能立即调用下一层。
- 在开放层体系结构中,层可以调用其下的任何层。
封闭层架构限制了层之间的依赖关系。但是,如果一层只是将请求传递到下一层,则可能会产生不必要的网络流量。
N 层体系结构的类型
让我们看一下 N 层体系结构的一些示例:
3 层架构
3 层应用广泛,由以下不同层组成:
- 表示层:处理用户与应用程序的交互。
- 业务逻辑层:接受来自应用程序层的数据,根据业务逻辑对其进行验证,并将其传递到数据层。
- 数据访问层:从业务层接收数据,对数据库进行必要的操作。
2 层架构
在此体系结构中,表示层在客户端上运行并与数据存储进行通信。客户端和服务器之间没有业务逻辑层或直接层。
单层或 1 层体系结构
这是最简单的一种,因为它相当于在个人计算机上运行应用程序。应用程序运行所需的所有组件都位于单个应用程序或服务器上。
优势
以下是使用 N 层体系结构的一些优点:
- 可以提高可用性。
- 更好的安全性,因为层可以像防火墙一样运行。
- 单独的层允许我们根据需要扩展它们。
- 改进维护,因为不同的人可以管理不同的层。
弊
以下是 N 层体系结构的一些缺点:
- 整个系统的复杂性增加。
- 随着层数的增加,网络延迟增加。
- 昂贵,因为每一层都有自己的硬件成本。
- 网络安全难以管理。
消息代理
消息代理是一种软件,它使应用程序、系统和服务能够相互通信并交换信息。消息代理通过在正式消息传递协议之间转换消息来实现此目的。这允许相互依赖的服务直接相互“对话”,即使它们是用不同的语言编写的或在不同的平台上实现的。
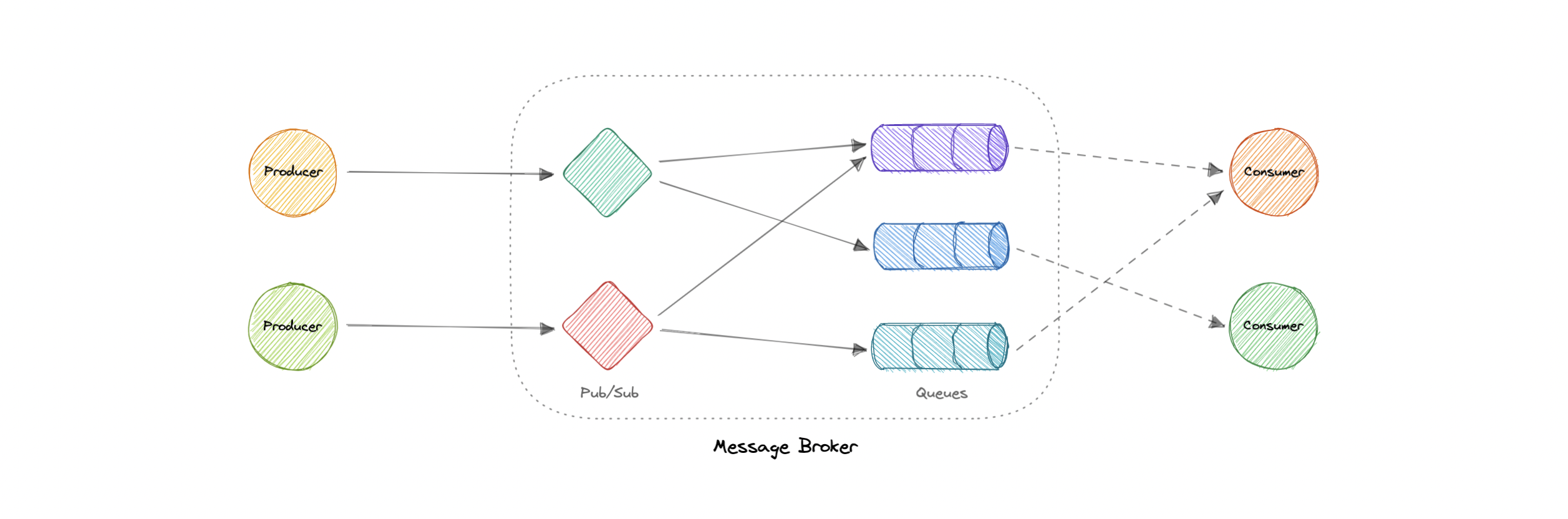
消息代理可以验证、存储、路由消息并将其传递到适当的目标。它们充当其他应用程序之间的中介,允许发送者发出消息,而无需知道接收者在哪里、它们是否处于活动状态或有多少个。这促进了系统内流程和服务的解耦。
模型
消息代理提供两种基本的消息分发模式或消息传递样式:
- 点对点消息传递:这是消息队列中使用的分发模式,消息的发送方和接收方之间具有一对一的关系。
- 发布-订阅消息传递:在这种消息分发模式(通常称为“发布/订阅”)中,每条消息的生成者将其发布到一个主题,多个消息使用者订阅他们想要从中接收消息的主题。
我们将在后面的教程中详细讨论这些消息传递模式。
消息代理与事件流式处理
消息代理可以支持两种或多种消息传递模式,包括消息队列和发布/订阅,而事件流平台仅提供发布/订阅样式的分发模式。事件流式处理平台专为处理大量消息而设计,易于扩展。它们能够将记录流排序到称为主题的类别中,并将它们存储预定的时间。然而,与消息代理不同的是,事件流平台无法保证消息传递或跟踪哪些消费者收到了消息。
与消息代理相比,事件流式处理平台提供了更高的可伸缩性,但确保容错的功能(如消息重新发送)较少,并且消息路由和队列功能更有限。
消息代理与企业服务总线 (ESB)
企业服务总线 (ESB) 基础结构非常复杂,集成起来可能具有挑战性,维护成本高昂。当生产环境中出现问题时,很难对它们进行故障排除,它们不容易扩展,而且更新很繁琐。
而消息代理是 ESB 的“轻量级”替代方案,它以较低的成本提供类似的功能,一种服务间通信的机制。它们非常适合在微服务架构中使用,随着 ESB 的失宠,微服务架构变得越来越普遍。
例子
以下是一些常用的消息代理:
消息队列
消息队列是一种服务到服务通信的形式,可促进异步通信。它异步接收来自生产者的消息,并将其发送给消费者。
队列用于对大规模分布式系统中的请求进行有效管理。在处理负载最小的小型系统和小型数据库中,写入速度可以预测为快。但是,在更复杂和大型的系统中,写入可能需要几乎不确定的时间。

加工
消息存储在队列中,直到它们被处理和删除。每条消息仅由单个使用者处理一次。其工作原理如下:
- 创建者将作业发布到队列,然后通知用户作业状态。
- 使用者从队列中选取作业,对其进行处理,然后发出作业已完成的信号。
优势
让我们讨论一下使用消息队列的一些优点:
- 可扩展性:消息队列可以精确地扩展到我们需要的地方。当工作负载达到峰值时,应用程序的多个实例可以将所有请求添加到队列中,而不会有冲突的风险。
- 解耦:消息队列消除了组件之间的依赖关系,并大大简化了解耦应用程序的实现。
- 性能:消息队列支持异步通信,这意味着生成和使用消息的端点与队列交互,而不是彼此交互。生产者可以将请求添加到队列中,而无需等待处理。
- 可靠性:队列使我们的数据持久化,并减少系统不同部分脱机时发生的错误。
特征
现在,让我们讨论消息队列的一些所需功能:
推式或拉式交付
大多数消息队列都提供用于检索消息的推送和拉取选项。拉取意味着不断在队列中查询新消息。推送意味着当消息可用时,使用者会收到通知。我们还可以使用长轮询来允许拉取等待指定的时间,以便新消息到达。
FIFO(先进先出)队列
在这些队列中,最旧的(或第一个)条目(有时称为队列的“头”)将首先进行处理。
安排或延迟交货
许多消息队列都支持为消息设置特定的传递时间。如果我们需要对所有消息都有一个共同的延迟,我们可以设置一个延迟队列。
至少一次交付
消息队列可以存储消息的多个副本以实现冗余和高可用性,并在发生通信失败或错误时重新发送消息,以确保它们至少传递一次。
Exactly-Once 交付
当不能容忍重复时,FIFO(先进先出)消息队列将通过自动过滤掉重复项来确保每条消息只传递一次(并且只有一次)。
死信队列
死信队列是其他队列可以向其发送无法成功处理的消息的队列。这样可以轻松地将它们放在一边进行进一步检查,而不会阻塞队列处理或将 CPU 周期花费在可能永远不会成功使用的消息上。
订购
大多数消息队列都提供尽力而为排序,这可确保消息通常以与发送相同的顺序传递,并且消息至少传递一次。
毒丸消息
毒丸是可以接收但不能处理的特殊消息。它们是一种机制,用于向消费者发出信号以结束其工作,以便它不再等待新的输入,并且类似于在客户端/服务器模型中关闭套接字。
安全
消息队列将对尝试访问队列的应用程序进行身份验证,这使我们能够通过网络以及队列本身对消息进行加密。
任务队列
任务队列接收任务及其相关数据,运行它们,然后交付其结果。它们可以支持调度,并可用于在后台运行计算密集型作业。
背压
如果队列开始显著增长,则队列大小可能会大于内存,从而导致缓存未命中、磁盘读取,甚至性能降低。背压可以通过限制队列大小来提供帮助,从而为队列中已有的作业保持高吞吐率和良好的响应时间。队列填满后,客户端会收到服务器繁忙或 HTTP 503 状态代码,以便稍后重试。客户端可以在以后重试请求,可能使用指数退避策略。
例子
以下是一些广泛使用的消息队列:
发布-订阅
与消息队列类似,发布-订阅也是一种服务到服务通信的形式,可促进异步通信。在发布/订阅模型中,发布到主题的任何消息都会立即推送给该主题的所有订阅者。
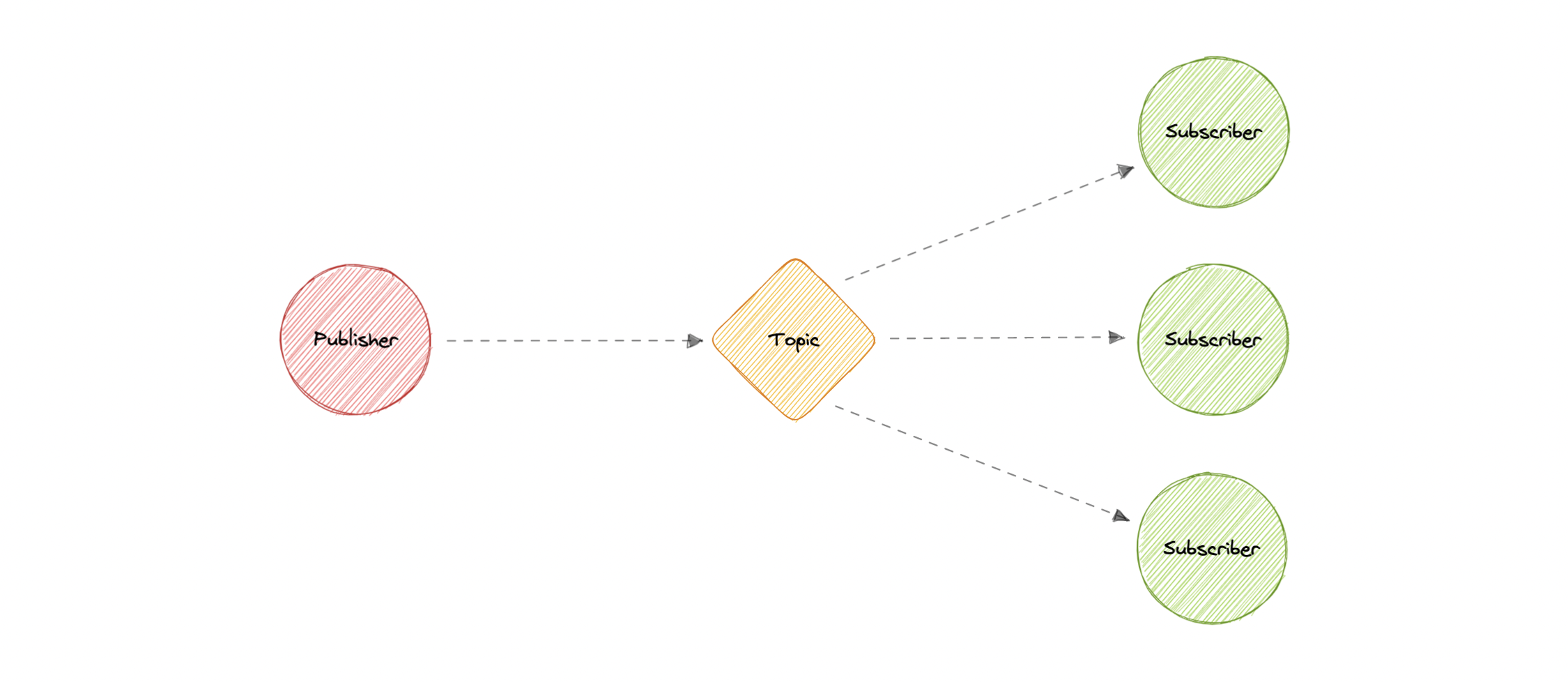
消息主题的订阅者通常执行不同的功能,并且每个订阅者可以并行对消息执行不同的操作。发布者不需要知道谁在使用它正在广播的信息,订阅者也不需要知道消息的来源。这种消息传递方式与消息队列略有不同,在消息队列中,发送消息的组件通常知道它要发送到的目标。
加工
与消息队列不同,消息队列在检索消息之前对消息进行批处理,消息主题在很少或没有排队的情况下传输消息,并立即将它们推送给所有订阅者。其工作原理如下:
- 消息主题提供了一种轻量级机制来广播异步事件通知和终结点,允许软件组件连接到主题以发送和接收这些消息。
- 为了广播消息,一个名为发布者的组件只需将消息推送到主题即可。
- 订阅该主题的所有组件(称为订阅者)将接收广播的每条消息。
优势
让我们讨论一下使用发布-订阅的一些优点:
- 消除轮询:消息主题允许基于推送的即时传递,无需消息使用者定期检查或“轮询”新信息和更新。这促进了更快的响应时间并减少了交付延迟,这在无法容忍延迟的系统中尤其成问题。
- 动态定位:Pub/Sub 使服务发现更轻松、更自然、更不容易出错。发布者只需将消息发布到主题,而不是维护应用程序可以发送消息的对等方名单。然后,任何感兴趣的一方都将为其端点订阅该主题,并开始接收这些消息。订阅者可以更改、升级、增加或消失,系统会动态调整。
- 解耦和独立扩展:发布者和订阅者是分离的,彼此独立工作,这使我们能够独立开发和扩展它们。
- 简化通信:发布-订阅模型通过删除与消息主题的单个连接的所有点对点连接来降低复杂性,该连接将管理订阅并决定应将哪些消息传递到哪些终结点。
特征
现在,让我们讨论一下发布-订阅的一些所需功能:
推送交付
发布/订阅消息传递会在消息发布到消息主题时立即推送异步事件通知。当消息可用时,订阅者会收到通知。
多种交付协议
在发布-订阅模型中,主题通常可以连接到多种类型的端点,例如消息队列、无服务器函数、HTTP 服务器等。
扇出
当消息发送到主题,然后复制并推送到多个终结点时,就会发生这种情况。扇出提供异步事件通知,进而允许并行处理。
滤波
此功能使订阅者能够创建消息过滤策略,以便它只接收它感兴趣的通知,而不是接收发布到主题的每条消息。
耐久性
发布/订阅消息传递服务通常通过在多个服务器上存储同一消息的副本来提供非常高的持久性,并且至少一次传递。
安全
消息主题对尝试发布内容的应用程序进行身份验证,这允许我们使用加密的端点并加密通过网络传输的消息。
例子
以下是一些常用的发布-订阅技术:
企业服务总线 (ESB)
企业服务总线 (ESB) 是一种体系结构模式,集中式软件组件通过该模式在应用程序之间执行集成。它执行数据模型的转换、处理连接、执行消息路由、转换通信协议,并可能管理多个请求的组成。ESB 可以将这些集成和转换作为服务接口提供,供新应用程序重用。
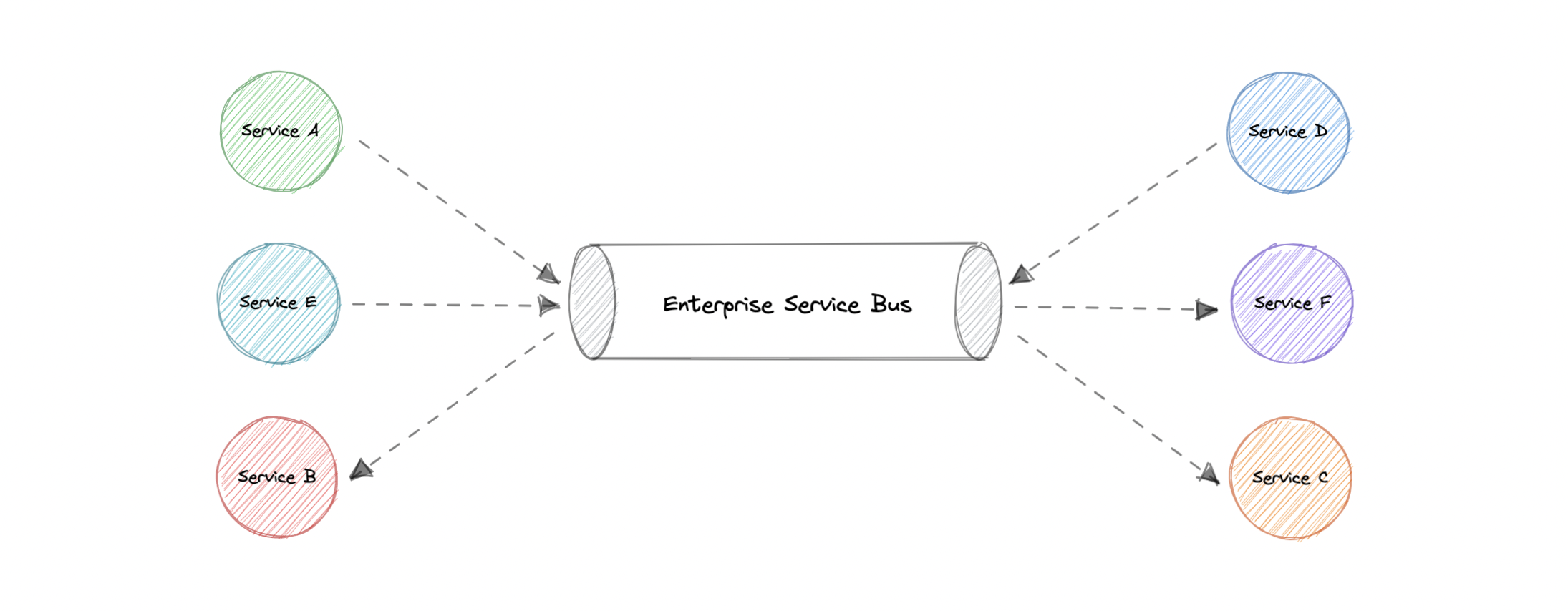
优势
从理论上讲,集中式 ESB 提供了标准化和显著简化整个企业服务之间的通信、消息传递和集成的潜力。以下是使用 ESB 的一些优点:
- 提高开发人员的工作效率:使开发人员能够将新技术合并到应用程序的一部分中,而无需触及应用程序的其余部分。
- 更简单、更具成本效益的可扩展性:组件可以独立于其他组件进行扩展。
- 更强的弹性:一个组件的故障不会影响其他组件,并且每个微服务都可以遵守自己的可用性要求,而不会危及系统中其他组件的可用性。
弊
虽然 ESB 在许多组织中都得到了成功的部署,但在许多其他组织中,ESB 被视为一个瓶颈。以下是使用 ESB 的一些缺点:
- 对一个集成进行更改或增强可能会破坏使用同一集成的其他集成的稳定性。
- 单点故障可能导致所有通信中断。
- 对 ESB 的更新通常会影响现有的集成,因此需要进行大量测试才能执行任何更新。
- ESB 是集中管理的,这使得跨团队协作具有挑战性。
- 配置和维护复杂度高。
例子
以下是一些广泛使用的企业服务总线 (ESB) 技术:
单体和微服务
单体
单体式是一个独立且独立的应用程序。它是作为一个单元构建的,不仅负责特定任务,而且可以执行满足业务需求所需的每个步骤。
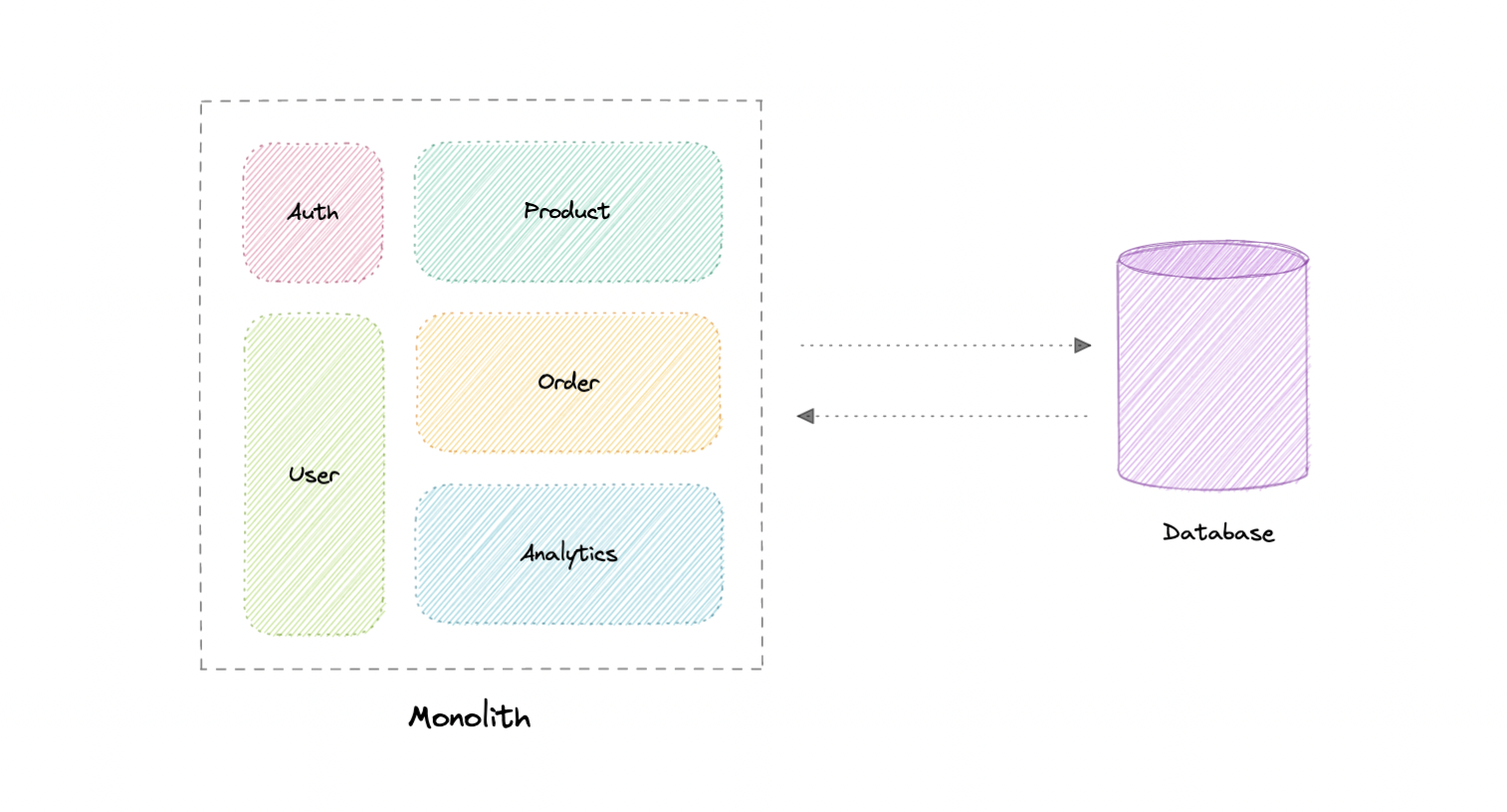
优势
以下是单体架构的一些优点:
- 易于开发或调试。
- 快速可靠的通信。
- 易于监控和测试。
- 支持 ACID 事务。
弊
单体架构的一些常见缺点是:
- 随着代码库的增长,维护变得困难。
- 紧密耦合的应用,难以扩展。
- 需要对特定技术堆栈的承诺。
- 每次更新时,都会重新部署整个应用程序。
- 可靠性降低,因为单个错误可能会使整个系统瘫痪。
- 难以扩展或采用新技术。
模块化单体
模块化单体是一种构建和部署单个应用程序(即单体部分)的方法,但我们以一种将代码分解为独立模块的方式构建它,以实现我们应用程序中所需的每个功能。
这种方法减少了模块的依赖性,例如我们可以在不影响其他模块的情况下增强或更改模块。如果做得好,从长远来看,这将是非常有益的,因为它降低了随着系统的发展而维护单体的复杂性。
微服务
微服务架构由一组小型自治服务组成,其中每个服务都是独立的,并且应该在边界上下文中实现单个业务功能。边界上下文是业务逻辑的自然划分,它提供了域模型存在的显式边界。
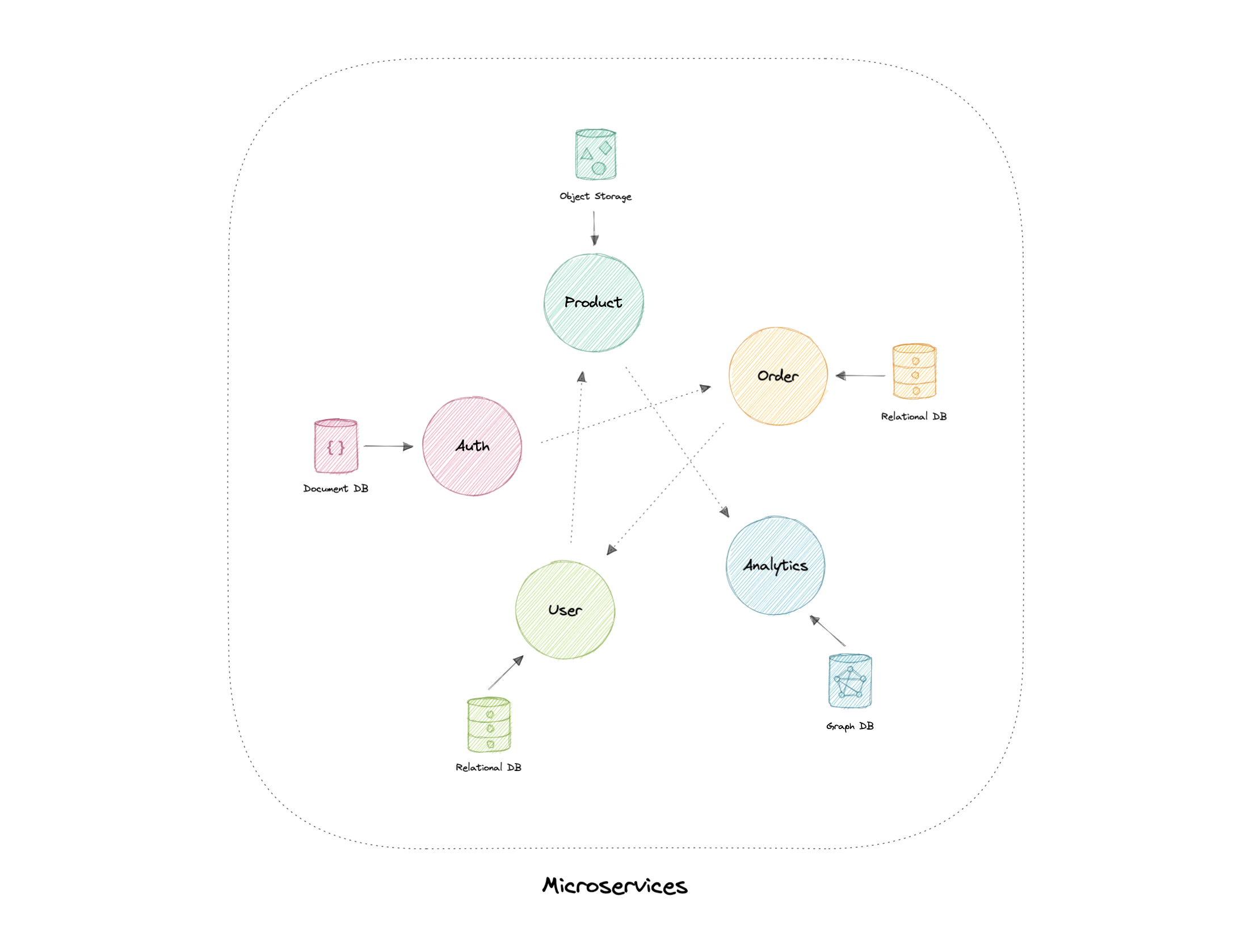
每个服务都有一个单独的代码库,可以由一个小型开发团队进行管理。服务可以独立部署,团队可以更新现有服务,而无需重新生成和重新部署整个应用程序。
服务负责保存自己的数据或外部状态(每个服务的数据库)。这与传统模型不同,在传统模型中,单独的数据层处理数据持久性。
特性
微服务架构风格具有以下特点:
- 松散耦合:服务应该是松散耦合的,以便它们可以独立部署和扩展。这将导致开发团队的权力下放,从而使他们能够以最小的限制和操作依赖性更快地进行开发和部署。
- 小而专注:这是关于范围和责任而不是规模,服务应该专注于特定问题。基本上,“它只做一件事,而且做得很好”。理想情况下,它们可以独立于底层架构。
- 专为企业打造:微服务架构通常围绕业务功能和优先级进行组织。
- 弹性和容错性:服务的设计方式应使其在发生故障或错误时仍能正常运行。在具有可独立部署服务的环境中,容错是最重要的。
- 高度可维护:服务应该易于维护和测试,因为无法维护的服务将被重写。
优势
以下是微服务架构的一些优势:
- 松散耦合的服务。
- 业务可以独立部署。
- 高度敏捷,适合多个开发团队。
- 提高容错和数据隔离。
- 更好的可扩展性,因为每个服务都可以独立扩展。
- 消除对特定技术堆栈的任何长期承诺。
弊
微服务架构带来了一系列挑战:
- 分布式系统的复杂性。
- 测试更加困难。
- 维护成本高昂(单个服务器、数据库等)。
- 服务间通信有其自身的挑战。
- 数据完整性和一致性。
- 网络拥塞和延迟。
最佳做法
让我们讨论一些微服务最佳实践:
- 围绕业务领域对服务进行建模。
- 服务应具有松散耦合和高功能内聚性。
- 隔离故障并使用复原策略来防止服务中的故障级联。
- 服务只能通过精心设计的 API 进行通信。避免泄露实施细节。
- 数据存储应是拥有数据的服务所专用的
- 避免服务之间的耦合。耦合的原因包括共享数据库架构和严格的通信协议。
- 分散一切。各个团队负责设计和构建服务。避免共享代码或数据架构。
- 通过使用断路器实现容错,实现快速故障。
- 确保 API 更改向后兼容。
陷阱
以下是微服务架构的一些常见陷阱:
- 服务边界不基于业务域。
- 低估了构建分布式系统的难度。
- 共享数据库或服务之间的常见依赖关系。
- 缺乏业务一致性。
- 缺乏明确的所有权。
- 缺乏幂等性。
- 尝试做所有事情 ACID 而不是 BASE。
- 缺乏容错设计可能会导致级联故障。
谨防分布式单体
分布式单体系统类似于微服务架构,但内部紧密耦合,就像一个整体式应用程序。采用微服务架构具有许多优势。但是在制作一个时,我们很有可能最终会得到一个分布式单体。
我们的微服务只是一个分布式单体,如果其中任何一个适用于它:
- 需要低延迟通信。
- 服务不容易扩展。
- 服务之间的依赖关系。
- 共享相同的资源,例如数据库。
- 紧密耦合的系统。
使用微服务架构构建应用程序的主要原因之一是具有可扩展性。因此,微服务应该具有松散耦合的服务,使每个服务都是独立的。分布式单体架构消除了这一点,并导致大多数组件相互依赖,从而增加了设计复杂性。
微服务与面向服务的架构 (SOA)
你可能已经看到互联网上提到的面向服务的架构(SOA),有时甚至可以与微服务互换,但它们彼此不同,这两种方法之间的主要区别归结为范围。
面向服务的体系结构 (SOA) 定义了一种使软件组件可通过服务接口重用的方法。这些接口利用通用的通信标准,专注于最大限度地提高应用程序服务的可重用性,而微服务则被构建为各种最小的独立服务单元的集合,专注于团队自治和解耦。
为什么不需要微服务
所以,你可能想知道,单体架构一开始似乎是个坏主意,为什么有人会使用它呢?
嗯,这要看情况。虽然每种方法都有其自身的优点和缺点,但建议在构建新系统时从单体开始。重要的是要明白,微服务不是灵丹妙药,相反,它们解决了组织问题。微服务架构既关乎技术,也关乎你的组织优先事项和团队。
在决定迁移到微服务架构之前,你需要问自己以下问题:
- “团队是否太大,无法在共享代码库上有效工作?”
- “其他团队是否被其他团队屏蔽了?”
- “微服务是否为我们带来了明确的业务价值?”
- “我的业务是否足够成熟,可以使用微服务?”
- “我们当前的架构是否限制了我们的通信开销?”
如果应用程序不需要分解为微服务,则不需要这样做。没有绝对必要将所有应用程序分解为微服务。
我们经常从 Netflix 等公司及其对微服务的使用中汲取灵感,但我们忽略了我们不是 Netflix 的事实。在获得市场就绪的解决方案之前,他们经历了大量的迭代和模型,当他们确定并解决他们想解决的问题时,这种架构对他们来说是可以接受的。
因此,如果你的企业确实需要微服务,则必须深入了解这一点。我想说的是,微服务是解决复杂问题的解决方案,如果你的企业没有复杂的问题,你就不需要它们。
事件驱动架构 (EDA)
事件驱动架构 (EDA) 是关于使用事件作为系统内通信的一种方式。通常,利用消息代理异步发布和使用事件。发布者不知道谁在使用事件,而使用者彼此之间也不知道。事件驱动架构只是一种在系统内实现服务之间松耦合的方法。
什么是事件?
事件是表示系统中状态变化的数据点。它没有指定应该发生什么以及更改应该如何修改系统,它只通知系统特定的状态更改。当用户执行操作时,他们会触发一个事件。
组件
事件驱动架构有三个关键组件:
- 事件生产者:将事件发布到路由器。
- 事件路由器:过滤事件并将其推送给使用者。
- 事件使用者:使用事件来反映系统中的更改。
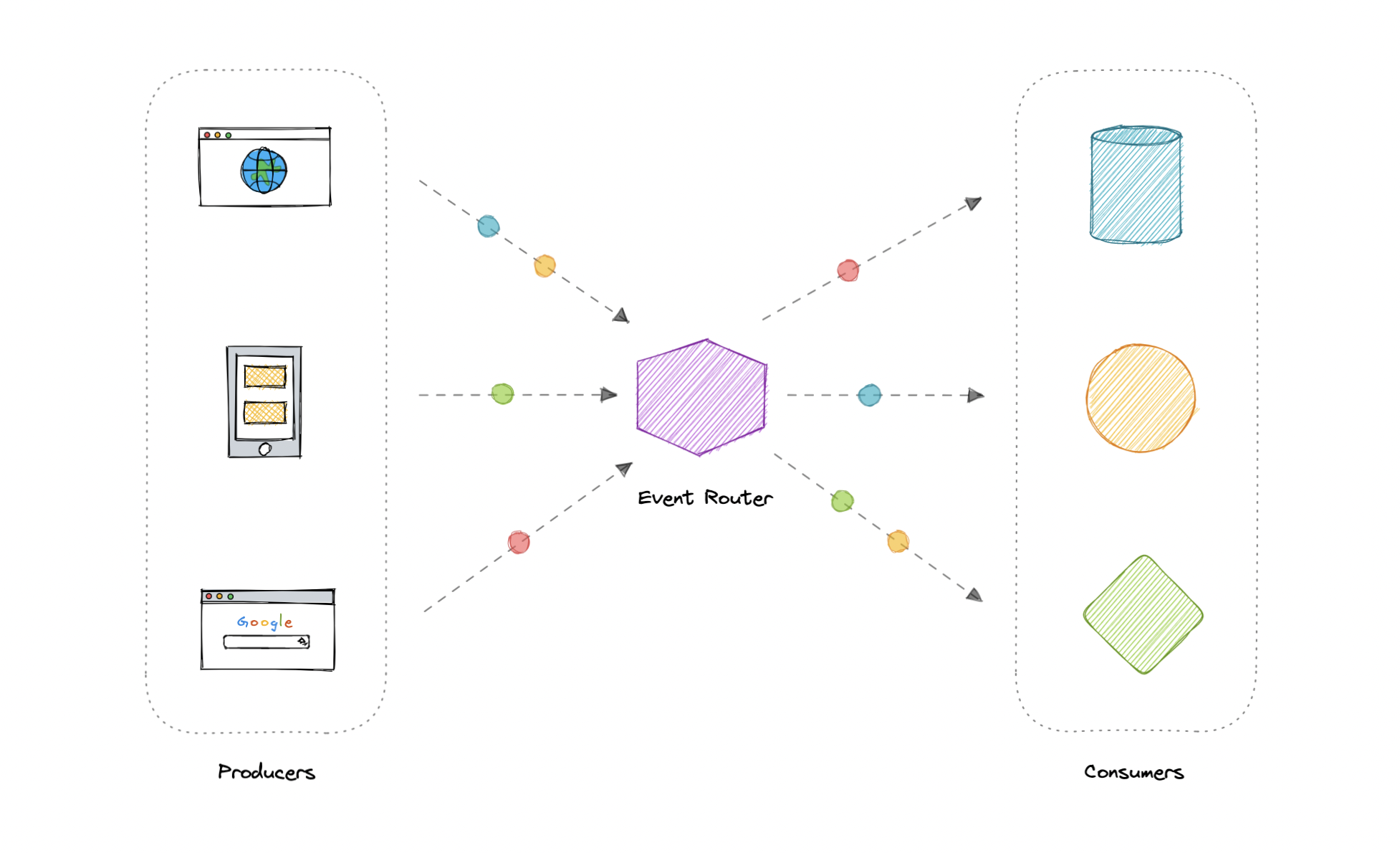
注意:图中的点表示系统中的不同事件。
模式
有几种方法可以实现事件驱动的架构,我们使用哪种方法取决于用例,但这里有一些常见的示例:
注意:这些方法中的每一种都将单独讨论。
优势
让我们讨论一些优点:
- 生产者和消费者解耦。
- 高度可扩展和分布式。
- 易于添加新的消费者。
- 提高敏捷性。
挑战
以下是事件驱动架构的一些挑战:
- 保证交货。
- 错误处理很困难。
- 事件驱动系统通常很复杂。
- 正好一次,按顺序处理事件。
使用案例
以下是事件驱动架构有益的一些常见用例:
- 元数据和指标。
- 服务器和安全日志。
- 集成异构系统。
- 扇出和并行处理。
例子
以下是一些用于实现事件驱动架构的广泛使用的技术:
事件溯源
不要只在域中存储数据的当前状态,而是使用仅追加存储来记录对该数据执行的一系列完整操作。存储充当记录系统,可用于具体化域对象。
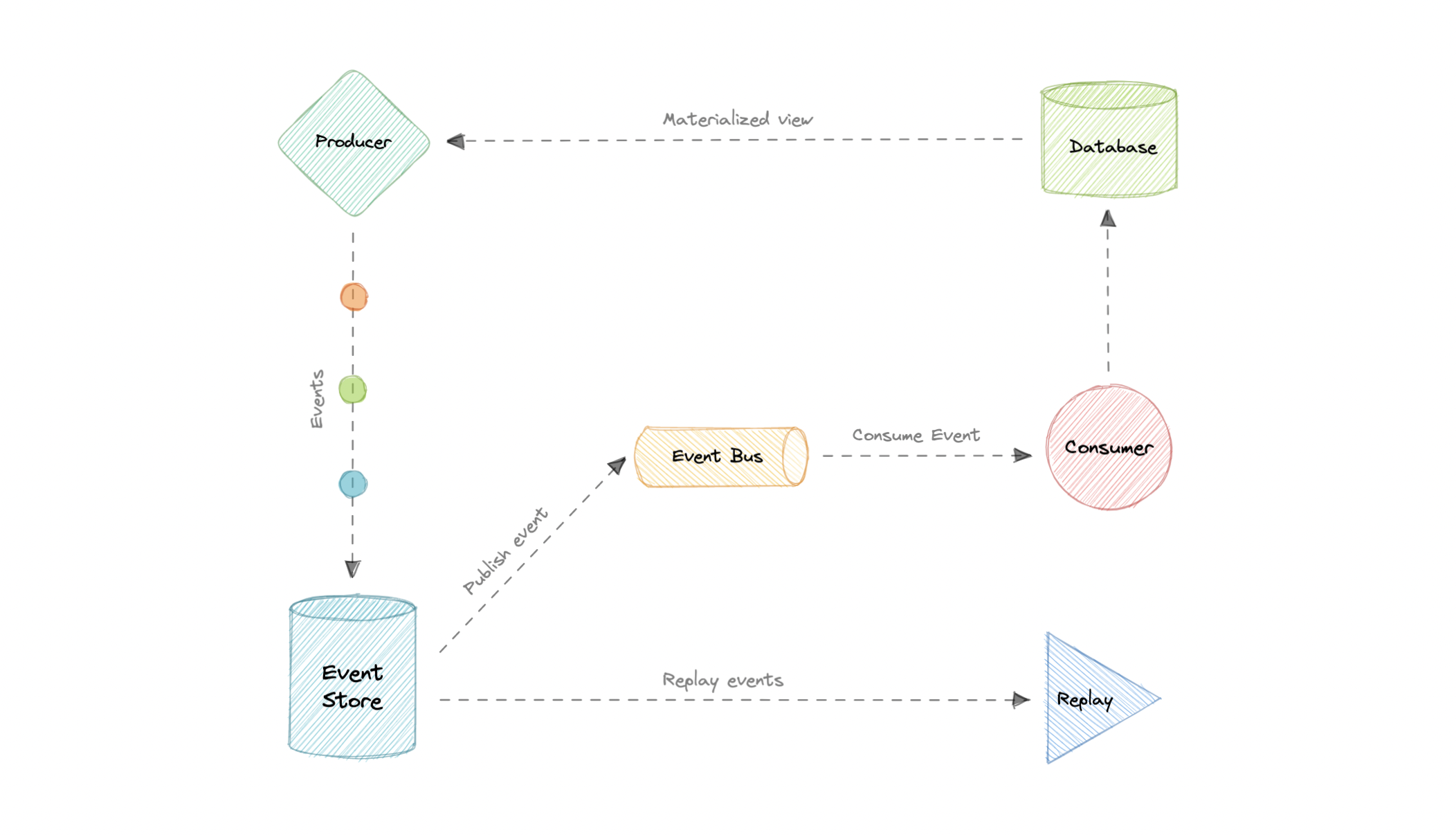
这可以简化复杂域中的任务,避免同步数据模型和业务域,同时提高性能、可伸缩性和响应能力。它还可以为事务数据提供一致性,并维护完整的审计跟踪和历史记录,从而启用补偿操作。
事件溯源与事件驱动架构 (EDA)
事件溯源似乎经常被与事件驱动架构(EDA)混淆。事件驱动架构是关于使用事件在服务边界之间进行通信。通常,利用消息代理在其他边界内异步发布和使用事件。
然而,事件溯源是关于使用事件作为状态,这是一种不同的数据存储方法。我们将不存储当前状态,而是存储事件。此外,事件溯源是实现事件驱动架构的几种模式之一。
优势
让我们讨论一下使用事件溯源的一些优点:
- 非常适合实时数据报告。
- 非常适合故障安全,可以从事件存储中重建数据。
- 非常灵活,可以存储任何类型的消息。
- 实现高合规性系统的审核日志功能的首选方法。
弊
以下是事件溯源的缺点:
- 需要极其高效的网络基础设施。
- 需要一种可靠的方法来控制消息格式,例如架构注册表。
- 不同的事件将包含不同的有效负载。
命令和查询责任分离 (CQRS)
命令查询责任分离 (CQRS) 是一种体系结构模式,它将系统的操作划分为命令和查询。它最初是由格雷格·杨(Greg Young)描述的。
在 CQRS 中,命令是一条指令,是执行特定任务的指令。它是一种改变某事的意图,不返回值,只返回成功或失败的指示。而且,查询是对信息的请求,不会更改系统状态或引起任何副作用。
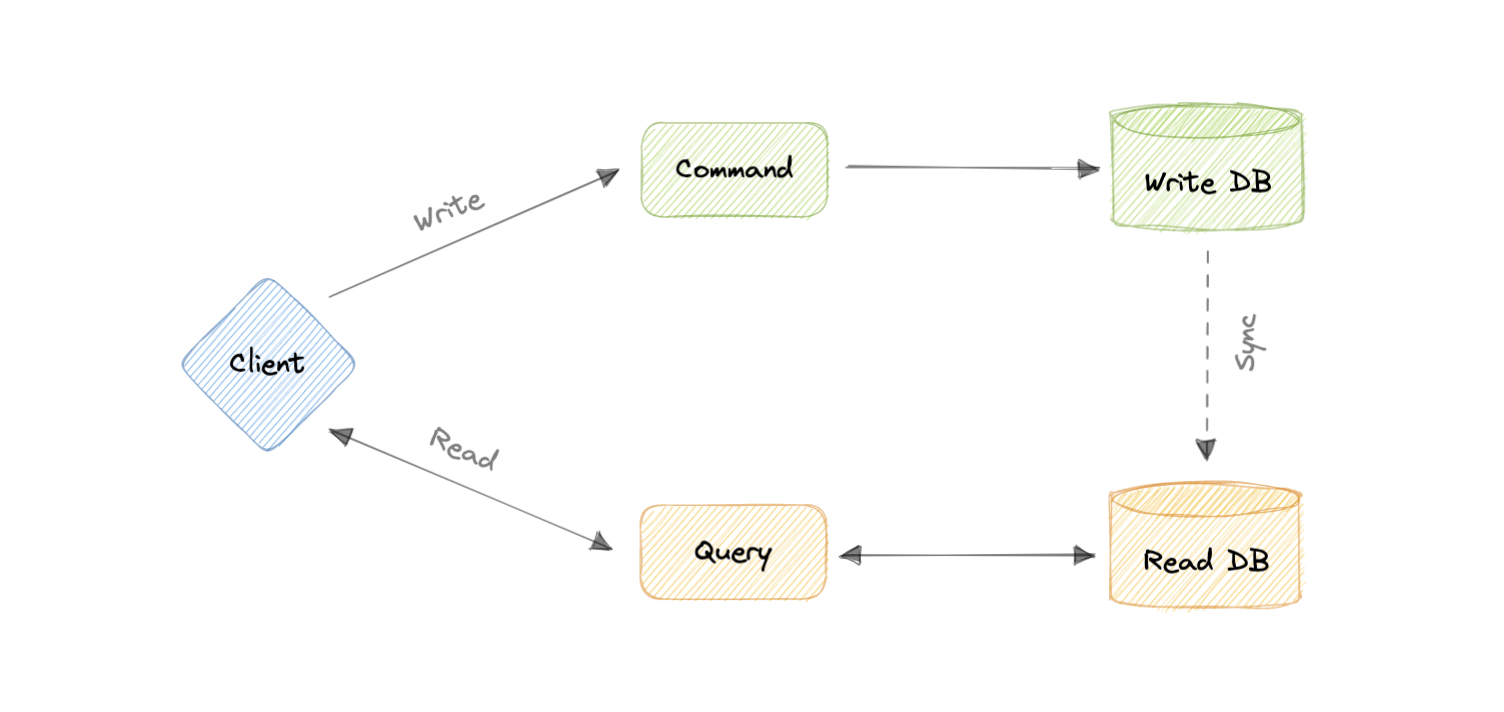
CQRS 的核心原则是命令和查询的分离。它们在系统中扮演着根本不同的角色,将它们分开意味着可以根据需要对每个角色进行优化,分布式系统可以从中受益。
CQRS 与事件溯源
CQRS 模式通常与事件溯源模式一起使用。基于 CQRS 的系统使用单独的读取和写入数据模型,每个模型都针对相关任务进行定制,并且通常位于物理上独立的存储中。
当与事件溯源模式一起使用时,事件存储是写入模型,是官方信息源。基于 CQRS 的系统的读取模型提供数据的具体化视图,通常为高度非规范化视图。
优势
让我们讨论一下 CQRS 的一些优点:
- 允许独立扩展读取和写入工作负载。
- 更轻松地进行扩展、优化和架构更改。
- 通过松散耦合更接近业务逻辑。
- 应用程序可以避免在查询时进行复杂的联接。
- 明确系统行为之间的界限。
弊
以下是 CQRS 的一些缺点:
- 更复杂的应用程序设计。
- 可能会出现消息失败或重复消息。
- 处理最终的一致性是一项挑战。
- 增加了系统维护工作。
使用案例
下面是 CQRS 会有所帮助的一些方案:
- 数据读取的性能必须与数据写入的性能分开进行微调。
- 预计系统会随着时间的推移而发展,并且可能包含模型的多个版本,或者业务规则会定期更改。
- 与其他系统集成,尤其是与事件溯源的结合使用,其中一个子系统的时间故障不应影响其他子系统的可用性。
- 提高安全性,确保只有正确的域实体才能对数据执行写入。
API 网关
API Gateway 是一种 API 管理工具,位于客户端和后端服务集合之间。它是系统的单个入口点,封装了内部系统架构,并提供了为每个客户端量身定制的 API。它还具有其他职责,例如身份验证、监视、负载平衡、缓存、限制、日志记录等。
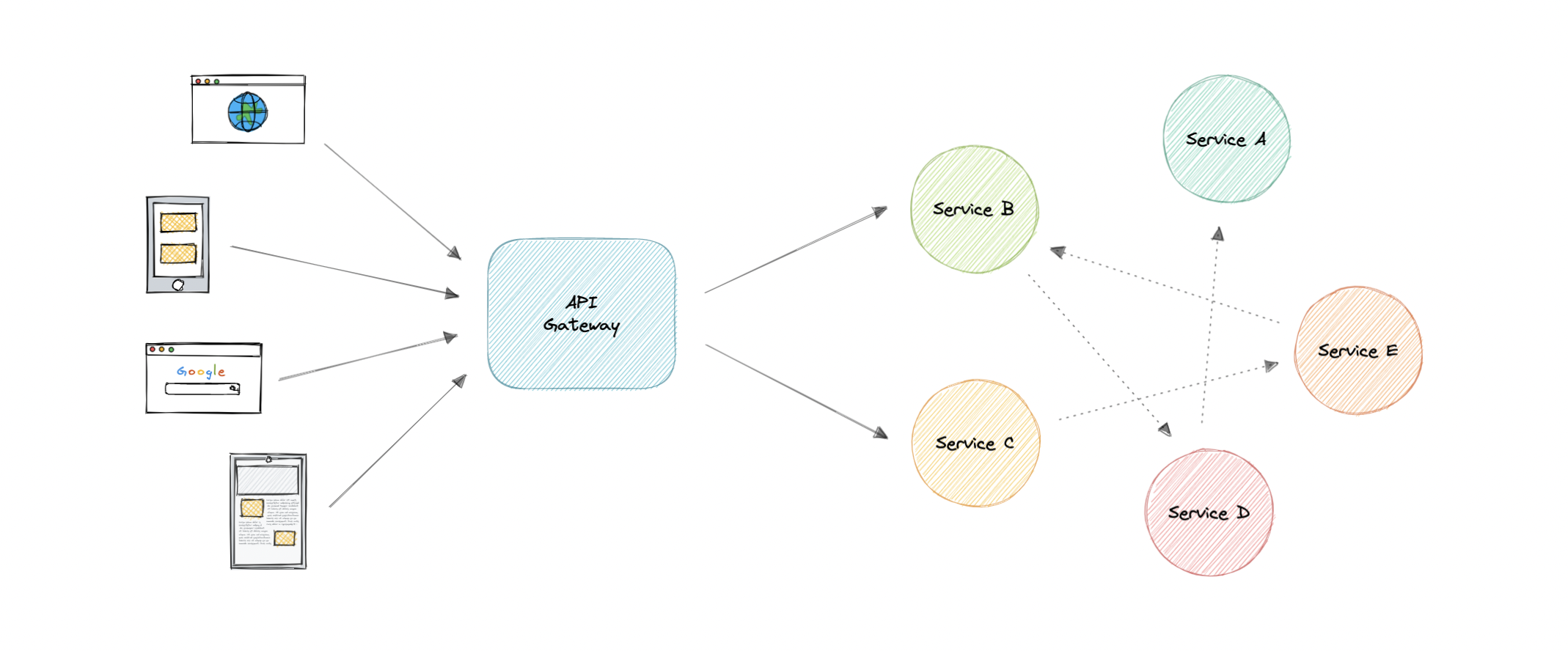
为什么我们需要 API 网关?
微服务提供的 API 粒度通常与客户端需要的粒度不同。微服务通常提供细粒度的 API,这意味着客户端需要与多个服务进行交互。因此,API 网关可以为所有客户端提供单一入口点,并提供一些附加功能和更好的管理。
特征
以下是 API 网关的一些所需功能:
优势
让我们看一下使用 API 网关的一些优势:
- 封装 API 的内部结构。
- 提供 API 的集中视图。
- 简化客户端代码。
- 监视、分析、跟踪和其他此类功能。
弊
以下是 API 网关的一些可能的缺点:
- 可能的单点故障。
- 可能会影响性能。
- 如果缩放不当,可能会成为瓶颈。
- 配置可能具有挑战性。
后端 For Frontend (BFF) 模式
在前端后端 (BFF) 模式中,我们创建单独的后端服务,供特定的前端应用程序或接口使用。当我们想要避免为多个接口自定义单个后端时,此模式非常有用。这种模式最早是由 Sam Newman 描述的。
此外,有时微服务返回到前端的数据输出格式不完全正确,或者前端根据需要进行筛选。为了解决这个问题,前端应该有一些逻辑来重新格式化数据,因此,我们可以使用 BFF 将一些逻辑转移到中间层。
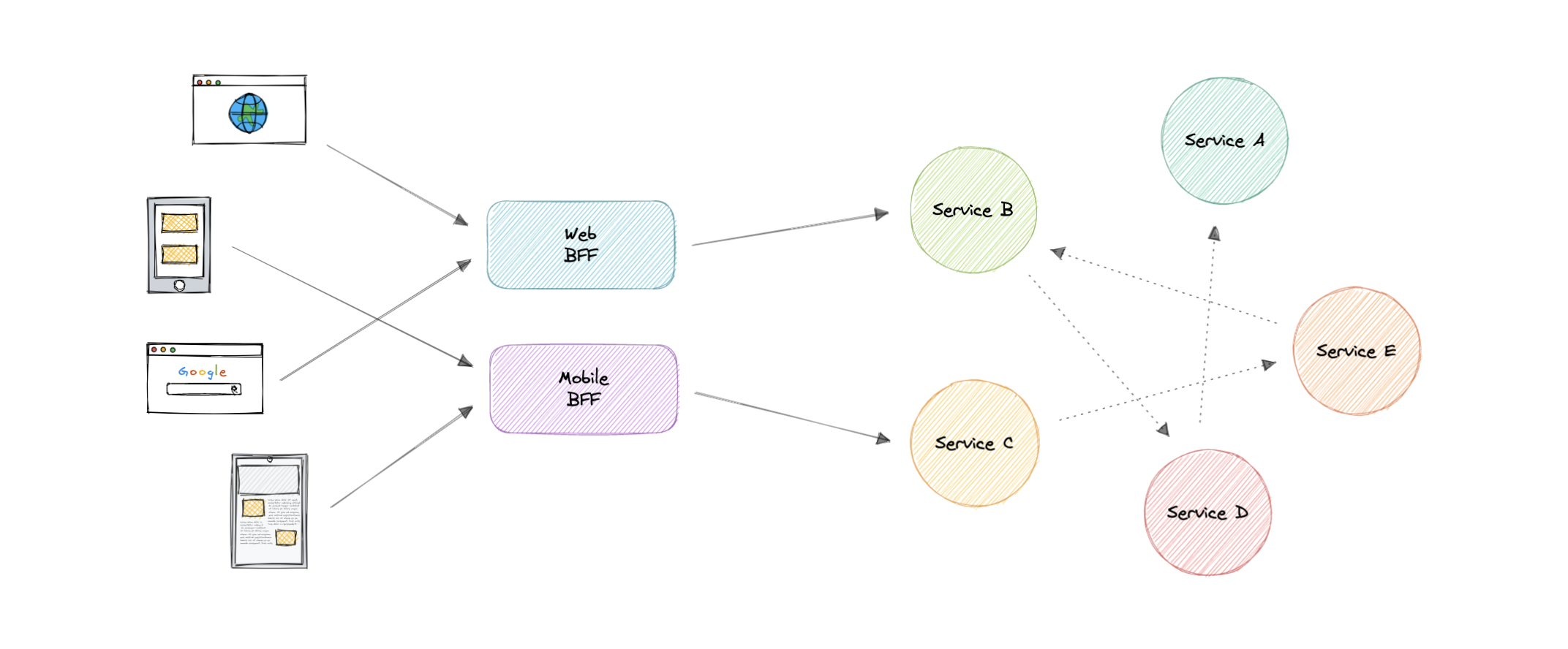
前端模式的后端的主要功能是从相应的服务获取所需的数据,格式化数据,并将其发送到前端。
GraphQL 作为前端的后端 (BFF) 表现得非常好。
何时使用此模式?
在以下情况下,我们应该考虑使用前端后端 (BFF) 模式:
- 必须维护共享或通用后端服务,并产生大量开发开销。
- 我们希望根据特定客户的要求优化后端。
- 对通用后端进行自定义,以适应多个接口。
例子
以下是一些广泛使用的网关技术:
REST、GraphQL、gRPC
一个好的 API 设计始终是任何系统的关键部分。但选择正确的 API 技术也很重要。因此,在本教程中,我们将简要讨论不同的 API 技术,例如 REST、GraphQL 和 gRPC。
什么是 API?
在我们进入 API 技术之前,让我们先了解一下什么是 API。
API 代表应用程序编程接口。它是一组用于构建和集成应用软件的定义和协议。它有时被称为信息提供者和信息用户之间的合同,用于确定生产者所需的内容和消费者所需的内容。
换句话说,如果你想与计算机或系统进行交互以检索信息或执行功能,API 可帮助你将所需的内容传达给该系统,以便它能够理解并完成请求。
休息
REST API(也称为 RESTful API)是一种应用程序编程接口,它符合 REST 架构风格的约束,并允许与 RESTful Web 服务进行交互。REST 代表具象状态转移,它由 Roy Fielding 于 2000 年首次引入。
在 REST API 中,基本单元是资源。
概念
让我们讨论一下 RESTful API 的一些概念。
约束
为了使 API 被视为 RESTful,它必须符合以下架构约束:
- 统一接口:应该有一种与给定服务器交互的统一方式。
- 客户端-服务器:通过 HTTP 管理的客户端-服务器体系结构。
- 无状态:在两次请求之间,服务器上不应存储任何客户端上下文。
- 可缓存:每个响应都应包括响应是否可缓存,以及响应可以在客户端缓存多长时间。
- 分层系统:应用程序架构需要由多个层组成。
- 按需代码:返回可执行代码以支持应用程序的一部分。(可选)
HTTP 谓词
HTTP 定义了一组请求方法,用于指示要对给定资源执行的所需操作。虽然它们也可以是名词,但这些请求方法有时被称为 HTTP 动词。它们中的每一个都实现了不同的语义,但一些共同的特征是由一组共享的。
以下是一些常用的 HTTP 谓词:
- GET:请求指定资源的表示形式。
-
HEAD:响应与请求相同,但没有响应正文。
GET
- POST:将实体提交到指定的资源,这通常会导致状态更改或对服务器产生副作用。
- PUT:将目标资源的所有当前表示形式替换为请求有效负载。
- DELETE:删除指定的资源。
- PATCH:对资源应用部分修改。
HTTP 响应代码
HTTP 响应状态代码指示特定 HTTP 请求是否已成功完成。
该标准定义了五个类:
- 1xx - 信息响应。
- 2xx - 成功响应。
- 3xx - 重定向响应。
- 4xx - 客户端错误响应。
- 5xx - 服务器错误响应。
例如,HTTP 200 表示请求成功。
优势
让我们讨论一下 REST API 的一些优点:
- 简单易懂。
- 灵活便携。
- 良好的缓存支持。
- 客户端和服务器是分离的。
弊
让我们讨论一下 REST API 的一些缺点:
- 过度提取数据。
- 有时需要多次往返服务器。
使用案例
REST API 几乎是通用的,并且是设计 API 的默认标准。总体而言,REST API 非常灵活,几乎可以适应所有场景。
例
下面是对用户资源进行操作的 REST API 的示例用法。
| URI | HTTP 谓词 | 描述 |
|---|---|---|
| /用户 | 获取 | 获取所有用户 |
| /用户/{id} | 获取 | 按 ID 获取用户 |
| /用户 | 发布 | 添加新用户 |
| /用户/{id} | 补丁 | 按 ID 更新用户 |
| /用户/{id} | 删除 | 按 ID 删除用户 |
在 REST API 方面,还有很多东西需要学习,我强烈建议你研究超媒体作为应用程序状态引擎 (HATEOAS)。
图形QL
GraphQL 是一种用于 API 的查询语言和服务器端运行时,它优先向客户端提供他们请求的数据,而不是更多。它由 Facebook 开发,后来于 2015 年开源。
GraphQL 旨在使 API 快速、灵活且对开发人员友好。此外,GraphQL 使 API 维护人员能够灵活地添加或弃用字段,而不会影响现有查询。开发人员可以使用他们喜欢的任何方法构建 API,而 GraphQL 规范将确保它们以可预测的方式运行给客户端。
在 GraphQL 中,基本单位是查询。
概念
让我们简要讨论一下 GraphQL 中的一些关键概念:
图式
GraphQL 模式描述了客户端在连接到 GraphQL 服务器后可以使用的功能。
查询
查询是客户端发出的请求。它可以由查询的字段和参数组成。查询的操作类型也可以是突变,它提供了一种修改服务器端数据的方法。
解析 器
Resolver 是为 GraphQL 查询生成响应的函数集合。简单来说,解析器充当 GraphQL 查询处理程序。
优势
让我们讨论一下 GraphQL 的一些优点:
- 消除数据的过度提取。
- 强定义的架构。
- 代码生成支持。
- 有效负载优化。
弊
让我们讨论一下 GraphQL 的一些缺点:
- 将复杂性转移到服务器端。
- 缓存变得困难。
- 版本控制不明确。
- N+1 问题。
使用案例
GraphQL 在以下场景中被证明是必不可少的:
- 减少应用程序带宽使用,因为我们可以在单个查询中查询多个资源。
- 复杂系统的快速原型设计。
- 当我们使用类似图形的数据模型时。
例
下面是一个定义类型和类型的 GraphQL 模式。
User
Query
type Query {
getUser: User
}
type User {
id: ID
name: String
city: String
state: String
}使用上述架构,客户端可以轻松请求必填字段,而无需获取整个资源或猜测 API 可能返回的内容。
{
getUser {
id
name
city
}
}这将向客户端提供以下响应。
{
"getUser": {
"id": 123,
"name": "Karan",
"city": "San Francisco"
}
}在 graphql.org 上了解有关 GraphQL 的更多信息。
gRPC的
gRPC 是一个现代开源高性能远程过程调用 (RPC) 框架,可以在任何环境中运行。它可以有效地连接数据中心内部和数据中心之间的服务,并可插拔支持负载均衡、跟踪、运行状况检查、身份验证等。
概念
让我们讨论一下 gRPC 的一些关键概念。
协议缓冲区
协议缓冲区提供了一种与语言和平台无关的可扩展机制,用于以向前和向后兼容的方式序列化结构化数据。它类似于 JSON,只是它更小、更快,并且它生成本机语言绑定。
服务定义
与许多 RPC 系统一样,gRPC 基于定义服务并指定可以使用其参数和返回类型远程调用的方法的思想。gRPC 使用协议缓冲区作为接口定义语言 (IDL) 来描述服务接口和有效负载消息的结构。
优势
让我们讨论一下 gRPC 的一些优点:
- 轻巧高效。
- 高性能。
- 内置代码生成支持。
- 双向流式处理。
弊
让我们讨论一下 gRPC 的一些缺点:
- 与 REST 和 GraphQL 相比相对较新。
- 有限的浏览器支持。
- 更陡峭的学习曲线。
- 人类不可读。
使用案例
以下是 gRPC 的一些很好的用例:
- 通过双向流进行实时通信。
- 微服务中的高效服务间通信。
- 低延迟和高吞吐量通信。
- 多语言环境。
例
下面是在文件中定义的 gRPC 服务的基本示例。使用此定义,我们可以轻松地使用所选的编程语言编写代码生成服务。
*.proto
HelloService
service HelloService {
rpc SayHello (HelloRequest) returns (HelloResponse);
}
message HelloRequest {
string greeting = 1;
}
message HelloResponse {
string reply = 1;
}REST 与 GraphQL 与 gRPC
现在我们知道了这些 API 设计技术是如何工作的,让我们根据以下参数来比较它们:
- 会不会造成紧密耦合?
- API 的聊天程度(用于获取所需信息的不同 API 调用)如何?
- 性能如何?
- 集成有多复杂?
- 缓存的效果如何?
- 内置工具和代码生成?
- API 的可发现性是什么样的?
- 对 API 进行版本控制有多容易?
| 类型 | 耦合 | 健谈 | 性能 | 复杂性 | 缓存 | 代码生成 | 可发现性 | 版本控制 |
|---|---|---|---|---|---|---|---|---|
| 休息 | 低 | 高 | 好 | 中等 | 伟大 | 坏 | 好 | 容易 |
| 图形QL | 中等 | 低 | 好 | 高 | 习惯 | 好 | 好 | 习惯 |
| gRPC的 | 高 | 中等 | 伟大 | 低 | 习惯 | 伟大 | 坏 | 硬 |
哪种 API 技术更好?
好吧,答案是没有一个。没有灵丹妙药,因为这些技术中的每一种都有自己的优点和缺点。用户只关心以一致的方式使用我们的 API,因此在设计 API 时,请务必关注你的领域和要求。
长轮询、WebSockets、服务器发送事件 (SSE)
Web 应用程序最初是围绕客户端-服务器模型开发的,其中 Web 客户端始终是事务的发起者,例如从服务器请求数据。因此,服务器没有机制可以独立地向客户端发送或推送数据,而无需客户端首先发出请求。让我们讨论一些克服这个问题的方法。
长轮询
HTTP 长轮询是一种用于尽快将信息从服务器推送到客户端的技术。因此,服务器不必等待客户端发送请求。
在长轮询中,服务器在收到来自客户端的请求后不会关闭连接。相反,仅当有任何新消息可用或达到超时阈值时,服务器才会响应。
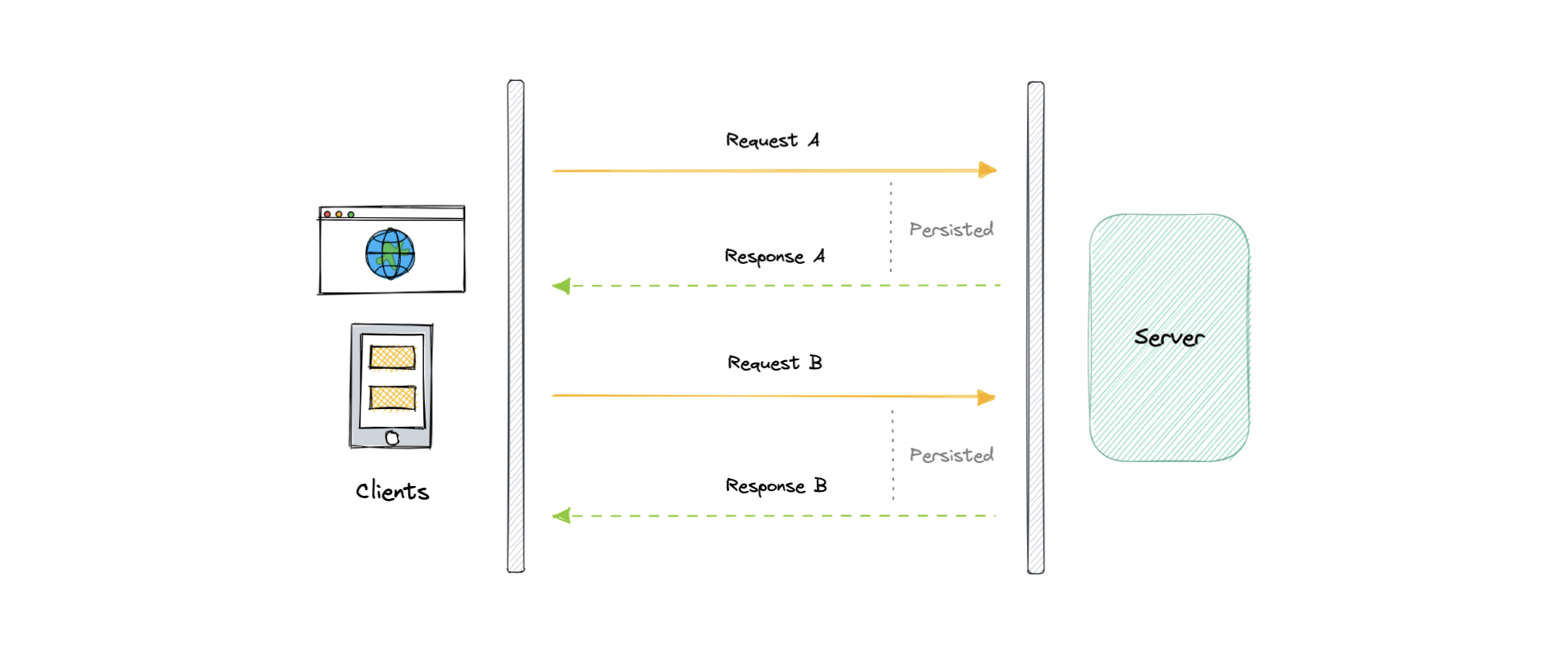
一旦客户端收到响应,它就会立即向服务器发送一个新的请求,以建立新的挂起连接以向客户端发送数据,并重复该操作。使用这种方法,服务器可以模拟实时服务器推送功能。
加工
让我们了解轮询的工作时间:
- 客户端发出初始请求并等待响应。
- 服务器接收请求并延迟发送任何内容,直到更新可用。
- 更新可用后,响应将发送到客户端。
- 客户端收到响应并立即发出新请求,或在某个定义的时间间隔后发出新请求以再次建立连接。
优势
以下是长轮询的一些优点:
- 易于实施,适合小型项目。
- 几乎得到普遍支持。
弊
长轮询的一个主要缺点是它通常不可扩展。以下是其他一些原因:
- 每次创建一个新连接,这在服务器上可能会很密集。
- 对于多个请求,可靠的消息排序可能是一个问题。
- 由于服务器需要等待新请求,延迟增加。
WebSockets(网络套接字)
WebSocket 通过单个 TCP 连接提供全双工通信通道。它是客户端和服务器之间的持久连接,双方都可以使用它随时开始发送数据。
客户端通过称为 WebSocket 握手的过程建立 WebSocket 连接。如果该过程成功,则服务器和客户端可以随时在两个方向上交换数据。WebSocket 协议能够以较低的开销实现客户端和服务器之间的通信,从而促进与服务器之间的实时数据传输。
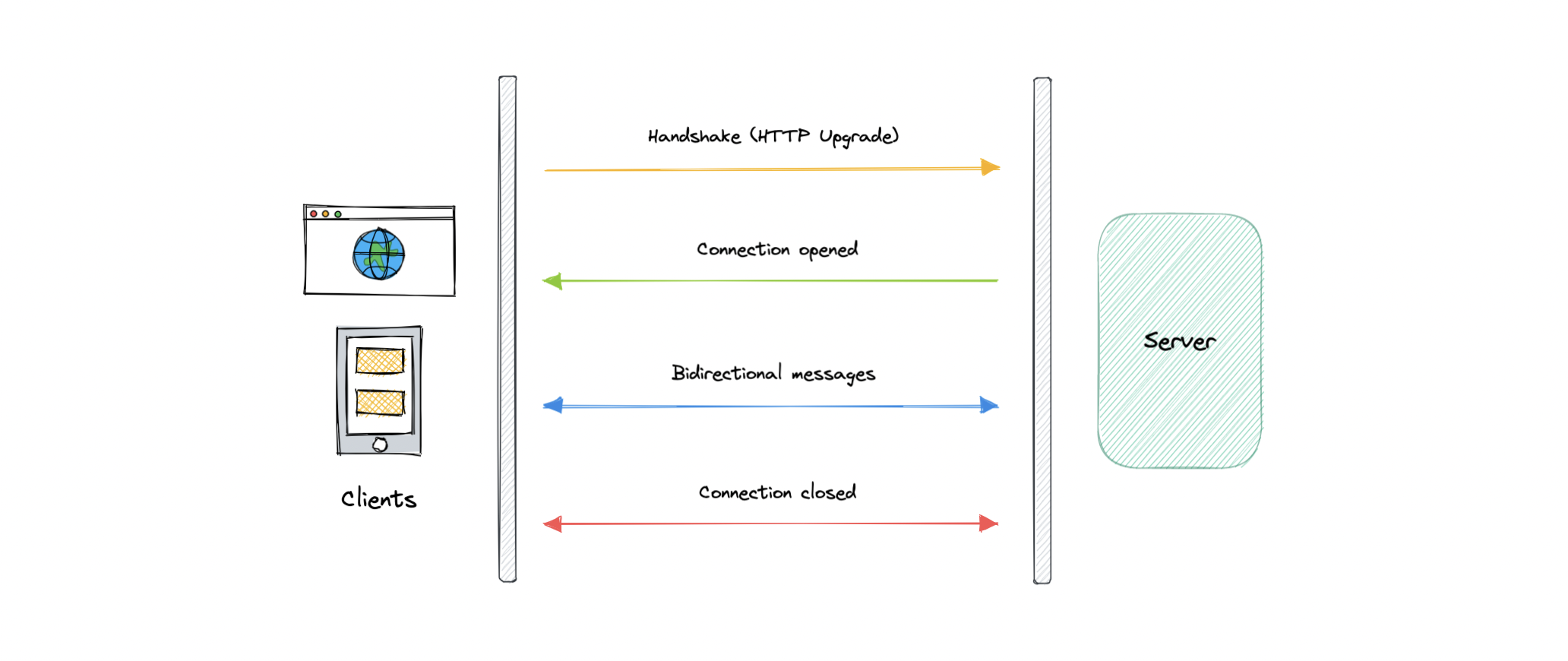
这是通过为服务器提供一种标准化的方式来实现的,该方式可以在不被询问的情况下将内容发送到客户端,并允许在保持连接打开的同时来回传递消息。
加工
让我们了解 WebSockets 是如何工作的:
- 客户端通过发送请求来启动 WebSocket 握手过程。
- 该请求还包含一个 HTTP Upgrade 标头,该标头允许请求切换到 WebSocket 协议 ()。
ws://
- 服务器向客户端发送响应,确认 WebSocket 握手请求。
- 一旦客户端收到成功的握手响应,将打开 WebSocket 连接。
- 现在,客户端和服务器可以开始双向发送数据,从而实现实时通信。
- 一旦服务器或客户端决定关闭连接,连接就会关闭。
优势
以下是 WebSockets 的一些优点:
- 全双工异步消息传递。
- 更好的基于源的安全模型。
- 客户端和服务器都是轻量级的。
弊
让我们讨论一下 WebSockets 的一些缺点:
- 终止的连接不会自动恢复。
- 较旧的浏览器不支持 WebSockets(变得不那么相关)。
服务器发送事件 (SSE)
服务器发送事件 (SSE) 是一种在客户端和服务器之间建立长期通信的方法,它使服务器能够主动将数据推送到客户端。
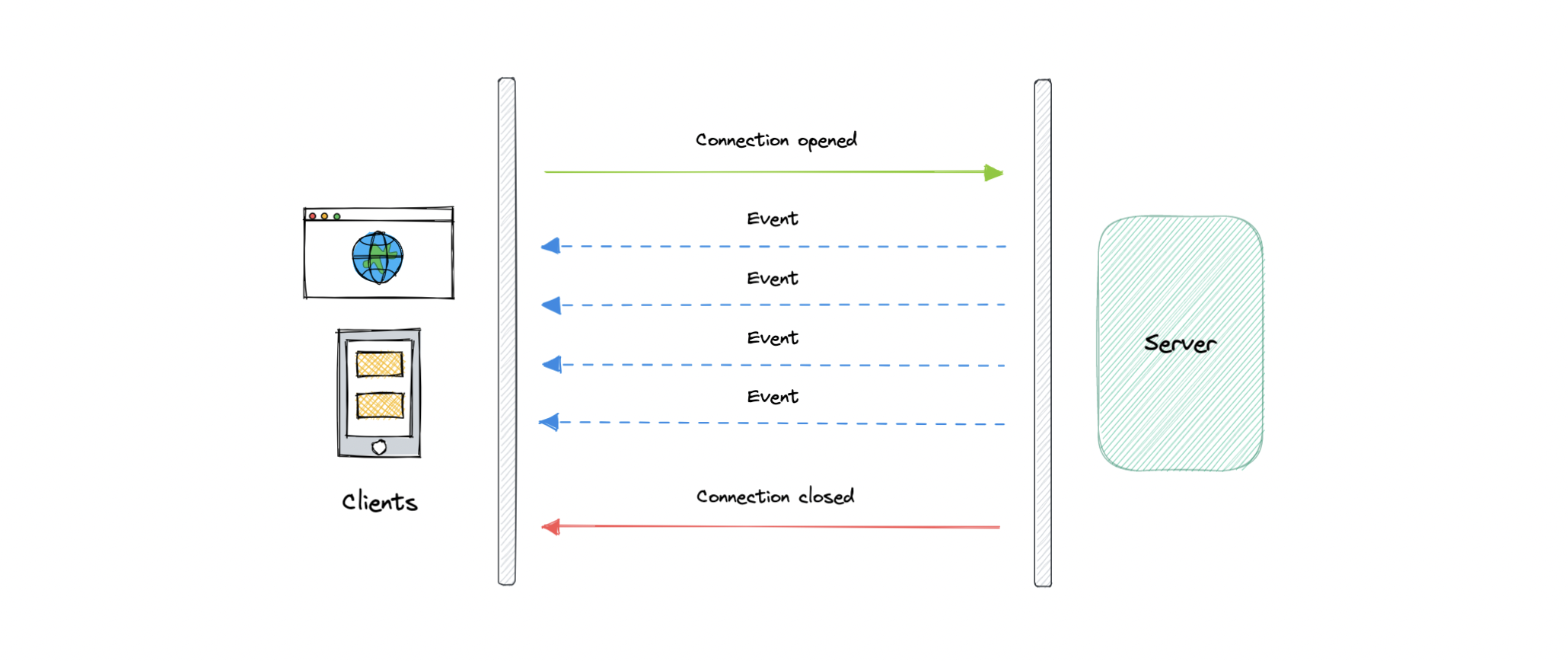
它是单向的,这意味着一旦客户端发送请求,它只能接收响应,而无法通过同一连接发送新请求。
加工
让我们了解服务器发送的事件是如何工作的:
- 客户端向服务器发出请求。
- 客户端和服务器之间的连接已建立,并且保持打开状态。
- 当有新数据可用时,服务器会向客户端发送响应或事件。
优势
- 易于实现和用于客户端和服务器。
- 大多数浏览器都支持。
- 防火墙没有问题。
弊
- 单向性可能是有限制的。
- 最大打开连接数的限制。
- 不支持二进制数据。
地理哈希和四叉树
地理散列
地理哈希是一种地理编码方法,用于将地理坐标(如纬度和经度)编码为短字母数字字符串。它由 Gustavo Niemeyer 于 2008 年创建。
例如,具有坐标的旧金山可以在 geohash 中表示为 。
37.7564, -122.4016
9q8yy9mf
地理哈希是如何工作的?
Geohash 是使用 Base-32 字母编码的分层空间索引,geohash 中的第一个字符将初始位置标识为 32 个单元格之一。该单元格还将包含 32 个单元格。这意味着,为了表示一个点,世界被递归地划分为越来越小的单元,每增加一个位,直到达到所需的精度。精度因子还决定了单元格的大小。
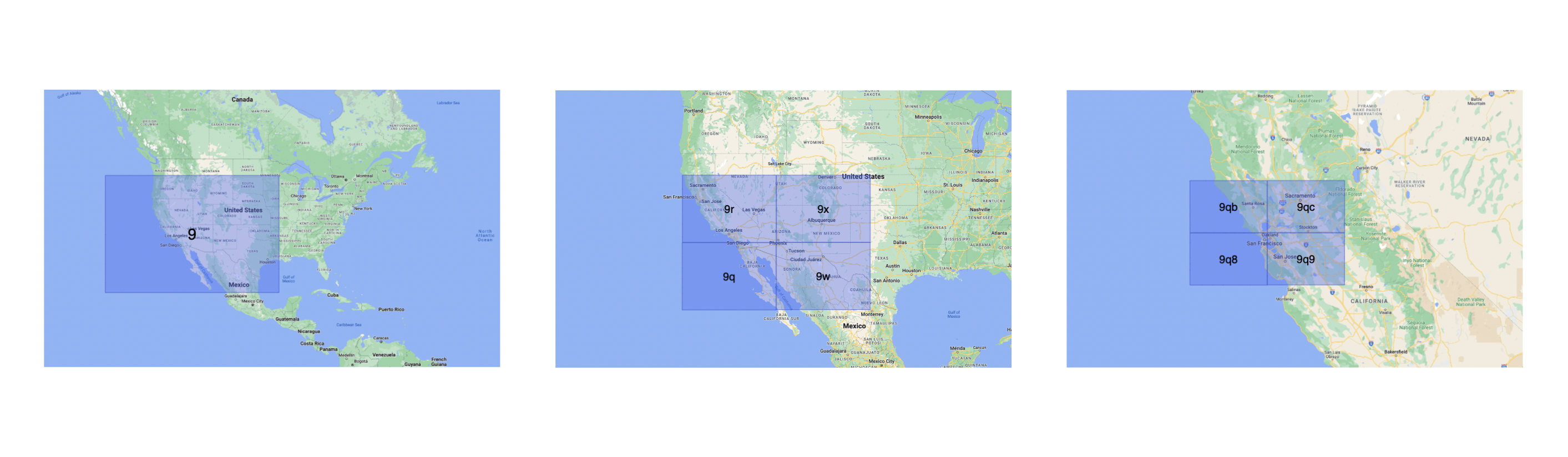
如果点的 Geohashes 共享更长的前缀,则地理哈希可以保证点在空间上更接近,这意味着字符串中的字符越多,位置就越精确。例如,geohashes 和 在空间上更接近,因为它们共享前缀 。
9q8yy9mf
9q8yy9vx
9q8yy9
Geohashing 也可用于提供一定程度的匿名性,因为我们不需要公开用户的确切位置,因为根据 geohash 的长度,我们只知道它们在一个区域内的某个地方。
不同长度的 geohash 的像元大小如下:
| Geohash 长度 | 单元格宽度 | 单元格高度 |
|---|---|---|
| 1 | 5000 千米 | 5000 千米 |
| 2 | 1250 千米 | 1250 千米 |
| 3 | 156 千米 | 156 千米 |
| 4 | 39.1公里 | 19.5公里 |
| 5 | 4.89千米 | 4.89千米 |
| 6 | 1.22千米 | 0.61千米 |
| 7 | 153米 | 153米 |
| 8 | 38.2 米 | 19.1 米 |
| 9 | 4.77 米 | 4.77 米 |
| 10 | 1.19 米 | 0.596 米 |
| 11 | 149 毫米 | 149 毫米 |
| 12 | 37.2 毫米 | 18.6 毫米 |
使用案例
以下是 Geohashing 的一些常见用例:
- 这是在数据库中表示和存储位置的简单方法。
- 它也可以作为 URL 在社交媒体上共享,因为它比纬度和经度更容易分享和记住。
- 我们可以通过非常简单的字符串比较和高效的索引搜索来有效地找到点的最近邻。
例子
地理哈希被广泛使用,并得到流行数据库的支持。
四叉树
四叉树是一种树数据结构,其中每个内部节点正好有四个子节点。它们通常用于通过将二维空间递归细分为四个象限或区域来划分二维空间。每个子节点或叶节点都存储空间信息。四叉树是八叉树的二维模拟,用于划分三维空间。
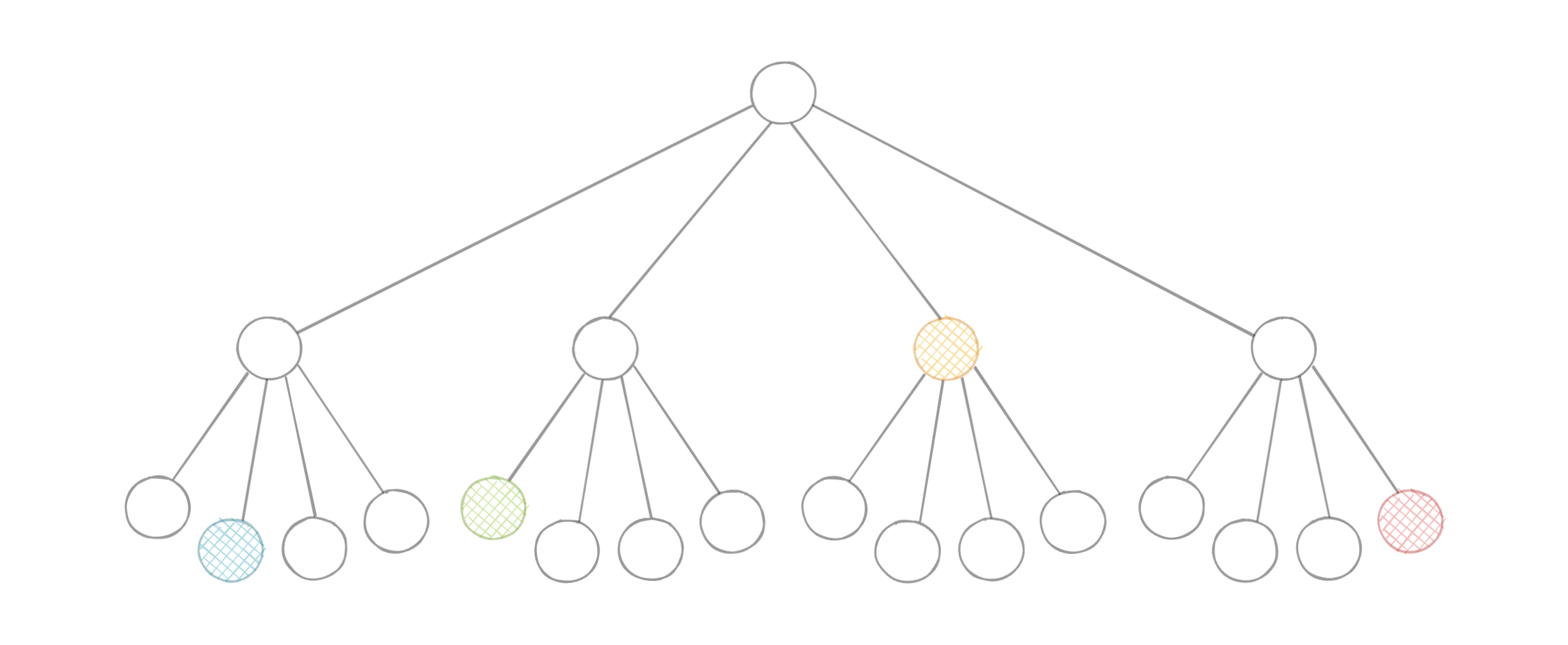
四叉树的类型
四叉树可以根据它们所代表的数据类型进行分类,包括面积、点、线和曲线。以下是常见的四叉树类型:
- 点四叉树
- 点区域 (PR) 四叉树
- 多边形 map (PM) 四叉树
- 压缩四叉树
- 边缘四叉树
为什么我们需要四叉树?
纬度和经度还不够吗?为什么我们需要四叉树?虽然从理论上讲,使用纬度和经度,我们可以使用欧几里得距离来确定点之间的距离,但对于实际用例来说,由于其对大型数据集的 CPU 密集型性质,它根本无法扩展。
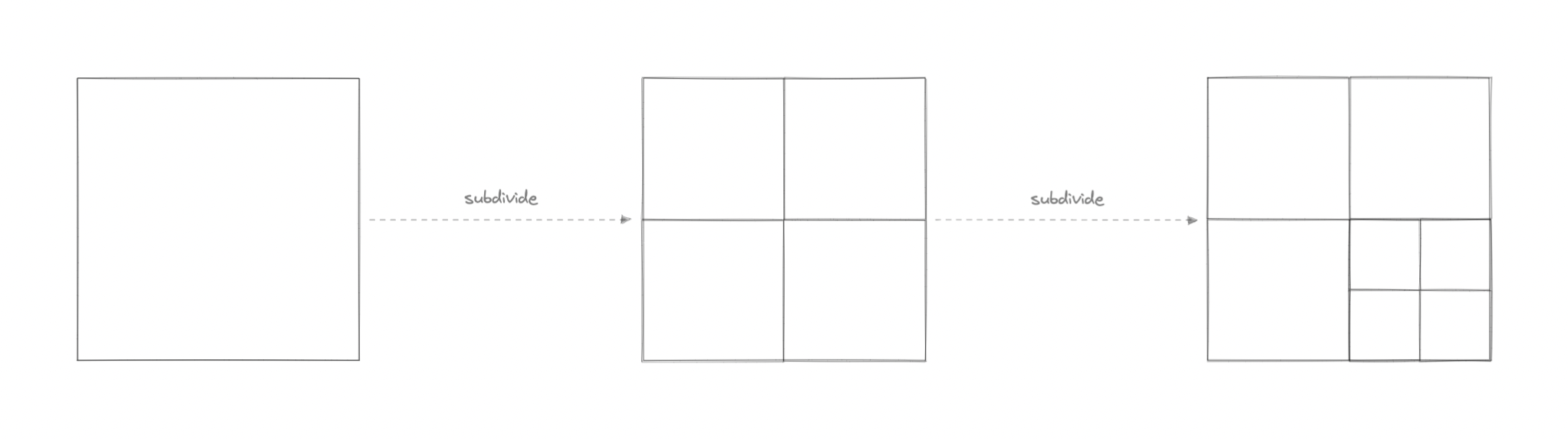
四叉树使我们能够有效地搜索二维范围内的点,其中这些点被定义为纬度/经度坐标或笛卡尔 (x, y) 坐标。此外,我们可以通过仅在某个阈值后细分节点来节省进一步的计算。并且通过应用希尔伯特曲线等映射算法,我们可以轻松提高范围查询性能。
使用案例
以下是四叉树的一些常见用法:
- 图像表示、处理和压缩。
- 空间索引和范围查询。
- 基于位置的服务,如谷歌 map、优步等。
- 网格生成和计算机图形学。
- 稀疏数据存储。
断路器
断路器是一种用于检测故障的设计模式,它封装了防止故障在维护、临时外部系统故障或意外系统故障期间不断重复出现的逻辑。
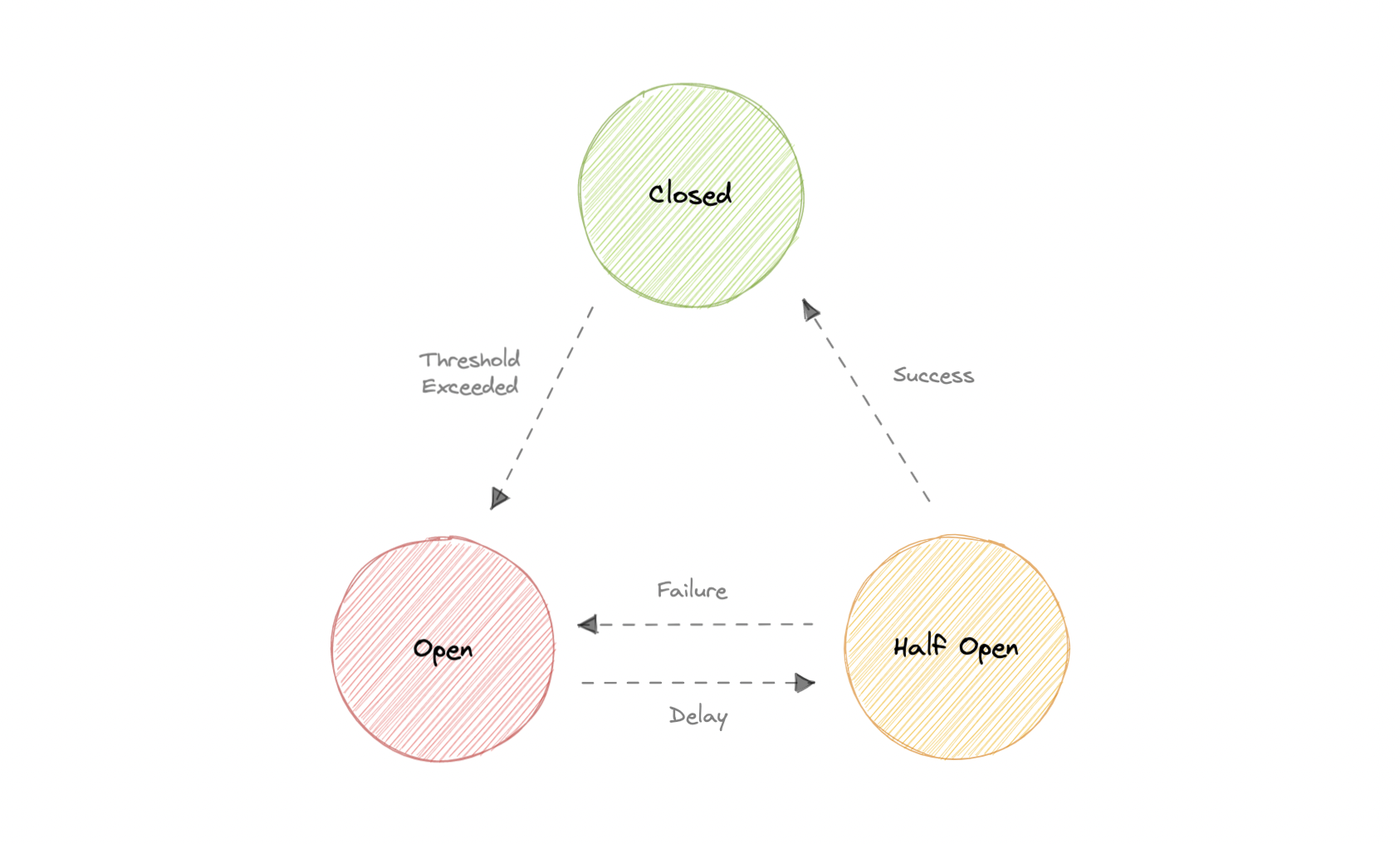
断路器背后的基本思想非常简单。我们将受保护的函数调用包装在断路器对象中,该对象监视故障。一旦故障达到某个阈值,断路器就会跳闸,并且对断路器的所有进一步调用都会返回错误,而不会进行受保护的调用。通常,如果断路器跳闸,我们还需要某种监视器警报。
为什么我们需要熔断?
软件系统通常会对在不同进程中运行的软件进行远程调用,这些软件可能在网络上的不同计算机上运行。内存中调用和远程调用之间的最大区别之一是,远程调用可能会失败,或者挂起而没有响应,直到达到某个超时限制。更糟糕的是,如果我们在响应不灵敏的供应商上有许多呼叫者,那么我们可能会耗尽关键资源,从而导致跨多个系统的级联故障。
国家
我们来讨论一下断路器状态:
闭
当一切正常时,断路器保持闭合状态,所有请求都照常传递到服务。如果故障数量超过阈值,断路器将跳闸并进入开路状态。
打开
在这种状态下,断路器会立即返回错误,甚至无需调用服务。断路器在经过一定的超时时间后进入半开状态。通常,它将有一个监视系统,其中将指定超时。
半开
在此状态下,断路器允许来自服务的有限数量的请求通过并调用操作。如果请求成功,则断路器将进入闭合状态。但是,如果请求继续失败,则它将返回到打开状态。
速率限制
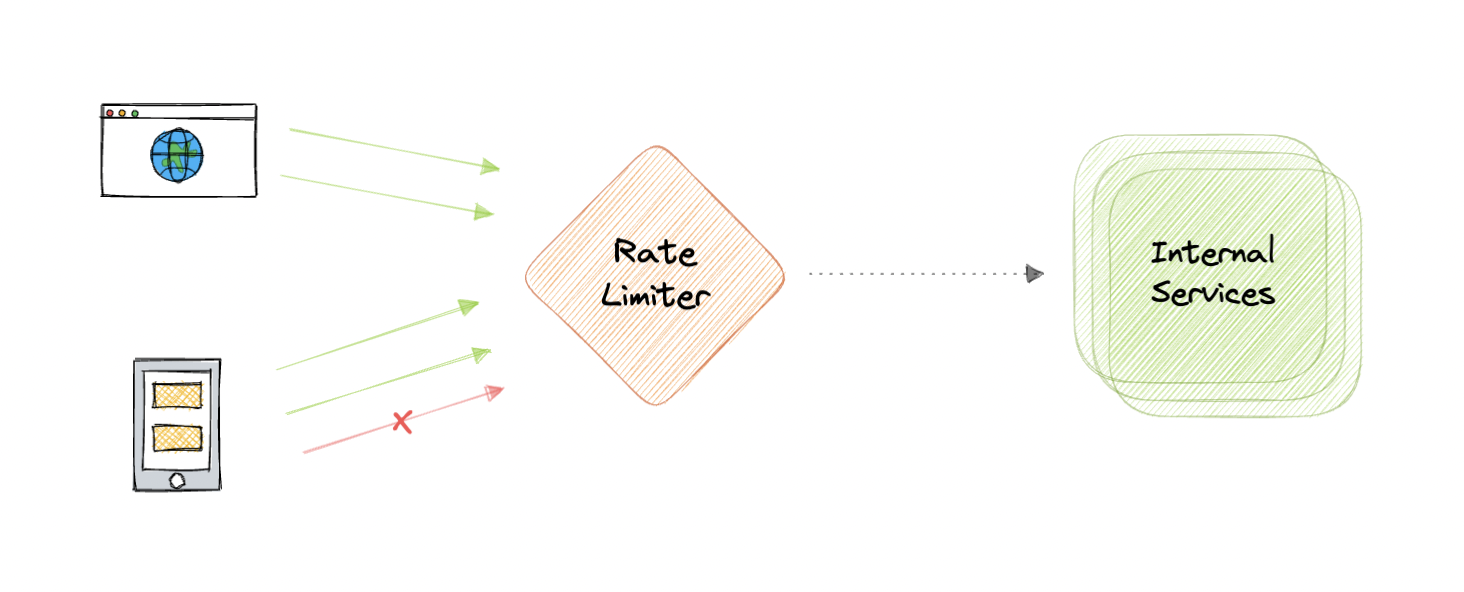
速率限制是指防止操作频率超过定义的限制。在大型系统中,速率限制通常用于保护底层服务和资源。速率限制通常用作分布式系统中的防御机制,以便共享资源可以保持可用性。它还通过限制在给定时间段内可以到达我们的 API 的请求数量来保护我们的 API 免受意外或恶意过度使用。
为什么我们需要速率限制?
速率限制是任何大型系统中非常重要的一部分,它可用于完成以下任务:
- 避免因拒绝服务 (DoS) 攻击而导致的资源匮乏。
- 速率限制通过对资源的自动缩放设置虚拟上限来帮助控制运营成本,如果不进行监控,可能会导致指数级账单。
- 速率限制可用于防御或缓解某些常见攻击。
- 对于处理大量数据的 API,可以使用速率限制来控制该数据的流动。
算法
API 速率限制有多种算法,每种算法都有其优点和缺点。让我们简要讨论其中的一些算法:
漏水桶
Leaky Bucket 是一种算法,它提供了一种简单、直观的方法来通过队列进行速率限制。注册请求时,系统会将其追加到队列的末尾。队列中第一项的处理以固定时间间隔或先进先出 (FIFO) 进行。如果队列已满,则会丢弃(或泄漏)其他请求。
令牌存储桶
这里我们使用桶的概念。当请求传入时,必须从存储桶中获取和处理令牌。如果存储桶中没有可用的令牌,则请求将被拒绝,请求者必须稍后重试。因此,令牌存储桶会在特定时间段后刷新。
固定窗口
系统使用秒的窗口大小来跟踪固定窗口算法速率。每个传入请求都会递增窗口的计数器。如果计数器超过阈值,它将丢弃请求。
n
滑动日志
滑动日志速率限制涉及跟踪每个请求的时间戳日志。系统将这些日志存储在按时间排序的哈希集或表中。它还会丢弃时间戳超过阈值的日志。当有新请求传入时,我们会计算日志的总和以确定请求速率。如果请求超过阈值速率,则将其保留。
推拉窗
滑动窗口是一种混合方法,它结合了固定窗口算法的低处理成本和滑动日志改进的边界条件。与固定窗口算法一样,我们跟踪每个固定窗口的计数器。接下来,我们根据当前时间戳计算前一个窗口请求速率的加权值,以平滑流量突发。
分布式系统中的速率限制
当涉及分布式系统时,速率限制变得复杂。分布式系统中速率限制带来的两个主要问题是:
不一致
使用包含多个节点的集群时,我们可能需要强制实施全局速率限制策略。因为如果每个节点都跟踪其速率限制,则使用者在向不同节点发送请求时可能会超过全局速率限制。节点数越多,用户超出全局限制的可能性就越大。
解决此问题的最简单方法是在负载均衡器中使用粘性会话,以便将每个使用者发送到一个节点,但这会导致缺乏容错和扩展问题。另一种方法是使用像 Redis 这样的集中式数据存储,但这会增加延迟并导致争用条件。
竞争条件
当我们使用朴素的“get-then-set”方法时,会出现此问题,在这种方法中,我们检索当前速率限制计数器,递增它,然后将其推送回数据存储。此模型的问题在于,在执行读取-增量-存储的完整周期所需的时间内,可能会出现其他请求,每个请求都想使用无效(较低)计数器值存储增量计数器。这允许使用者发送大量请求以绕过速率限制控制。
避免此问题的一种方法是在密钥周围使用某种分布式锁定机制,防止任何其他进程访问或写入计数器。尽管锁将成为一个重大瓶颈,并且无法很好地扩展。更好的方法可能是使用“先设置后获取”的方法,允许我们快速递增和检查计数器值,而不会让原子操作妨碍。
服务发现
服务发现是对计算机网络内服务的检测。服务发现协议 (Service Discovery Protocol,简称 SDP) 是一种网络标准,通过识别资源来完成网络检测。
为什么我们需要服务发现?
在整体式应用程序中,服务通过语言级方法或过程调用相互调用。但是,基于微服务的现代应用程序通常在虚拟化或容器化环境中运行,在这些环境中,服务实例的数量及其位置会动态变化。因此,我们需要一种机制,使服务客户端能够向一组动态变化的临时服务实例发出请求。
实现
有两种主要的服务发现模式:
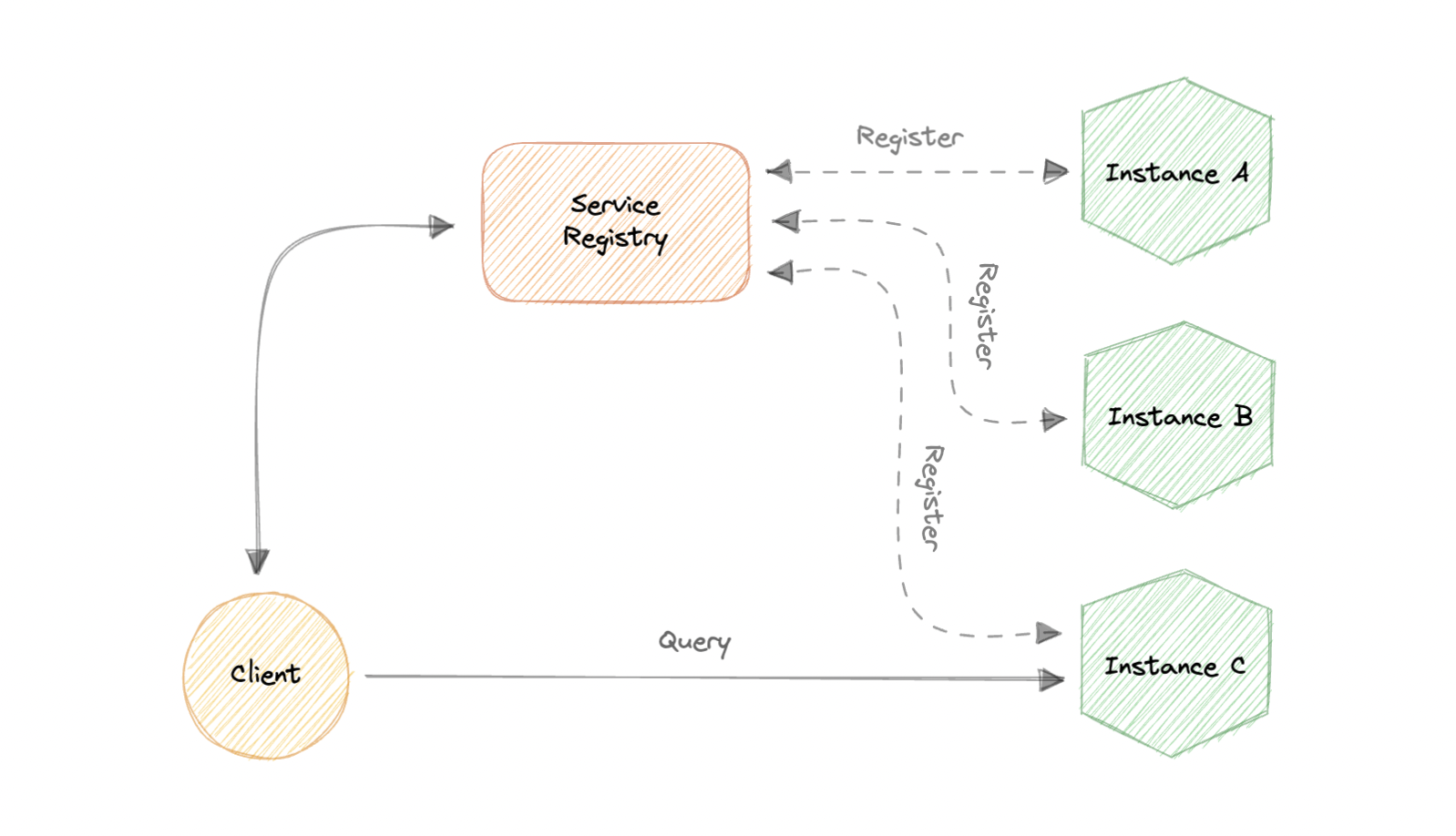
客户端发现
在这种方法中,客户端通过查询服务注册表来获取另一个服务的位置,该服务注册表负责管理和存储所有服务的网络位置。
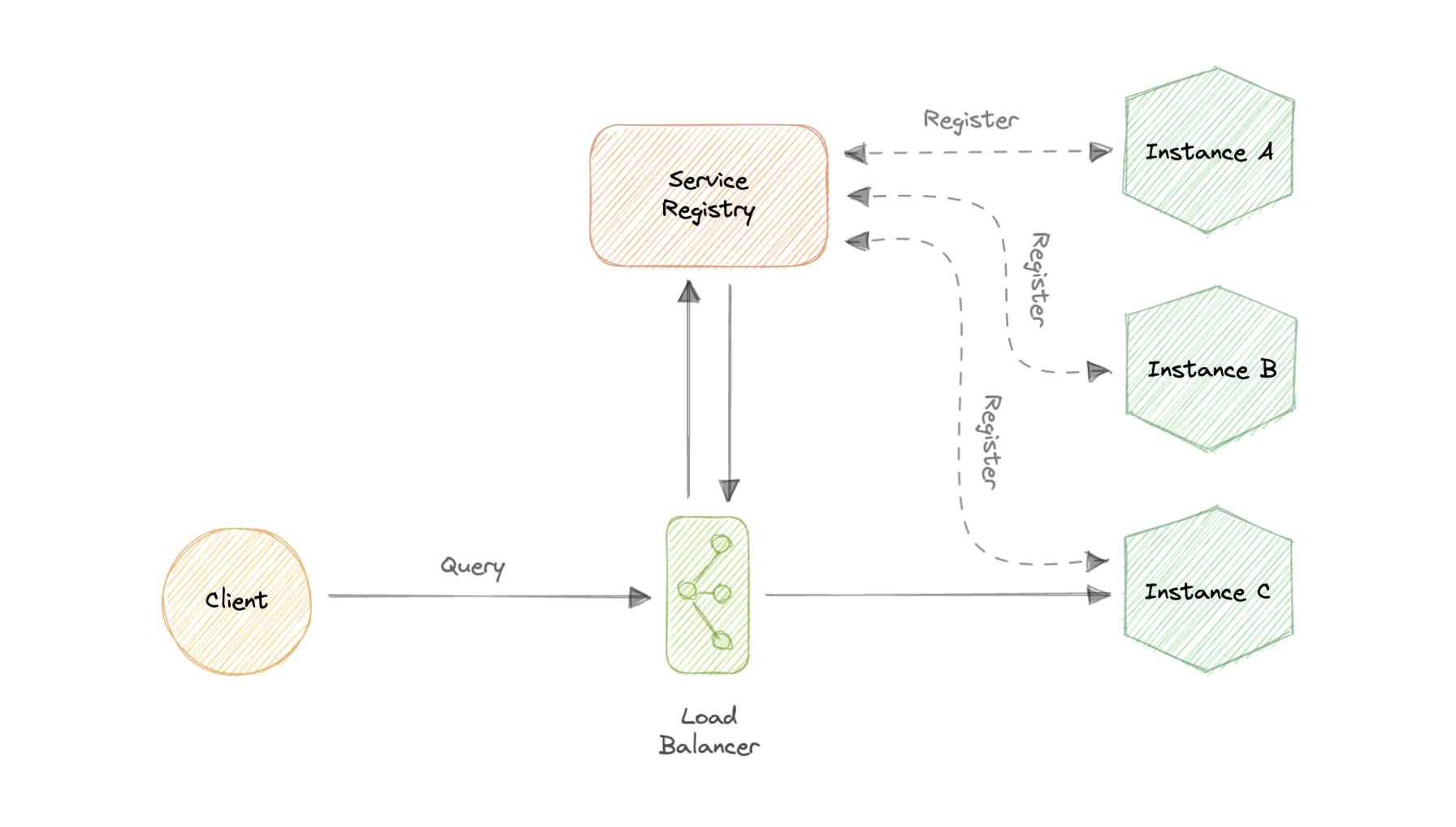
服务器端发现
在这种方法中,我们使用一个中间组件,例如负载均衡器。客户端通过负载均衡器向服务发出请求,然后负载均衡器将请求转发到可用的服务实例。
服务注册表
服务注册中心基本上是一个数据库,其中包含客户端可以访问的服务实例的网络位置。Service Registry 必须具有高可用性和最新性。
服务注册
我们还需要一种获取服务信息的方法,通常称为服务注册。让我们看一下两种可能的服务注册方法:
自助注册
使用自注册模型时,服务实例负责在 Service Registry 中注册和取消注册自身。此外,如有必要,服务实例会发送检测信号请求以保持其注册处于活动状态。
第三方注册
注册表通过轮询部署环境或订阅事件来跟踪对正在运行的实例的更改。当它检测到新可用的服务实例时,它会将其记录在其数据库中。Service Registry 还会取消注册已终止的服务实例。
服务网格
服务到服务通信在分布式应用程序中是必不可少的,但随着服务数量的增加,在应用程序集群内部和跨应用程序集群路由这种通信变得越来越复杂。服务网格支持各个服务之间托管、 Observable 和安全的通信。它与服务发现协议一起检测服务。Istio 和 envoy 是一些最常用的服务网格技术。
例子
以下是一些常用的服务发现基础架构工具:
SLA、SLO、SLI
让我们简要讨论一下 SLA、SLO 和 SLI。这些主要与业务和站点可靠性方面有关,但很高兴知道。
为什么它们很重要?
SLA、SLO 和 SLI 允许公司定义、跟踪和监控对用户服务的承诺。SLA、SLO 和 SLI 应共同帮助团队提高用户对其服务的信任度,并更加强调事件管理和响应流程的持续改进。
SLA协议
SLA 或服务水平协议是公司与其给定服务的用户之间达成的协议。SLA 定义了公司就特定指标(例如服务可用性)向用户做出的不同承诺。
SLA 通常由公司的业务或法律团队编写。
SLO(英语:SLO)
SLO,即服务水平目标,是公司就特定指标(如事件响应或正常运行时间)向用户做出的承诺。SLO 作为完整用户协议中包含的单个承诺存在于 SLA 中。SLO 是服务必须满足的特定目标,以符合 SLA。SLO 应始终简单、明确定义且易于衡量,以确定目标是否正在实现。
SLI系列
SLI(服务级别指示器)是用于确定是否满足 SLO 的关键指标。它是 SLO 中描述的指标的测量值。为了保持符合 SLA,SLI 的值必须始终达到或超过 SLO 确定的值。
灾难恢复
灾难恢复 (DR) 是在自然灾害、网络攻击甚至业务中断等事件后重新获得基础设施访问权限和功能的过程。
灾难恢复依赖于在不受灾难影响的异地位置复制数据和计算机处理。当服务器因灾难而宕机时,企业需要从备份数据的第二个位置恢复丢失的数据。理想情况下,组织也可以将其计算机处理转移到该远程位置,以便继续运营。
在系统设计面试中,灾难恢复通常不会被积极讨论,但对这个主题有一些基本的了解是很重要的。你可以从 AWS Well-Architected Framework 了解有关灾难恢复的更多信息。
为什么灾难恢复很重要?
灾难恢复具有以下优势:
- 最大限度地减少中断和停机时间
- 限制损害赔偿
- 快速恢复
- 更好的客户保留率
条款
让我们讨论一些与灾难恢复相关的重要术语:

RTO (反转交易)
恢复时间目标 (RTO) 是服务中断与服务恢复之间的最大可接受延迟。这决定了当服务不可用时,什么被认为是可接受的时间窗口。
区域配置效率
恢复点目标 (RPO) 是自上一个数据恢复点以来可接受的最长时间。这决定了在上一个恢复点和服务中断之间可接受的数据丢失。
策略
各种灾难恢复 (DR) 策略都可以成为灾难恢复计划的一部分。
备份
这是最简单的灾难恢复类型,涉及将数据存储在异地或可移动驱动器上。
冷站点
在这种类型的灾难恢复中,组织在第二个站点中设置基本基础结构。
热门网站
热站点始终维护最新的数据副本。热站点的设置非常耗时,并且比冷站点更昂贵,但它们大大减少了停机时间。
虚拟机 (VM) 和容器
在讨论虚拟化与容器化之前,让我们先了解一下什么是虚拟机 (VM) 和容器。
虚拟机 (VM)
虚拟机 (VM) 是一种虚拟环境,它充当虚拟计算机系统,具有自己的 CPU、内存、网络接口和存储,在物理硬件系统上创建。称为虚拟机监控程序的软件将计算机的资源与硬件分开,并适当地配置它们,以便 VM 可以使用它们。
VM 与系统的其余部分隔离,多个 VM 可以存在于单个硬件(如服务器)上。它们可以根据需要在主机服务器之间移动,或者更有效地使用资源。
什么是虚拟机管理程序?
虚拟机监控程序有时称为虚拟机监视器 (VMM),它将操作系统和资源与虚拟机隔离开来,并允许创建和管理这些虚拟机。虚拟机监控程序将 CPU、内存和存储等资源视为一个资源池,可以在现有客户机或新虚拟机之间轻松重新分配。
为什么要使用虚拟机?
服务器整合是使用 VM 的首要原因。大多数操作系统和应用程序部署仅使用少量可用的物理资源。通过虚拟化我们的服务器,我们可以在每台物理服务器上放置许多虚拟服务器,以提高硬件利用率。这使我们不需要购买额外的物理资源。
VM 提供了一个与系统其余部分隔离的环境,因此 VM 内部运行的任何内容都不会干扰主机硬件上运行的任何其他内容。由于 VM 是隔离的,因此它们是测试新应用程序或设置生产环境的不错选择。我们还可以运行单一用途的 VM 来支持特定用例。
器皿
容器是一种标准的软件单元,用于打包代码及其所有依赖项,例如特定版本的运行时和库,以便应用程序从一个计算环境快速可靠地运行到另一个计算环境。容器提供了一种逻辑打包机制,在这种机制中,应用程序可以从它们实际运行的环境中抽象出来。这种解耦允许轻松、一致地部署基于容器的应用程序,而不管目标环境如何。
我们为什么需要容器?
让我们讨论一下使用容器的一些优点:
责任分离
容器化提供了明确的责任分离,因为开发人员专注于应用程序逻辑和依赖关系,而运营团队可以专注于部署和管理。
工作负载可移植性
容器几乎可以在任何地方运行,从而大大简化了开发和部署。
应用程序隔离
容器在操作系统级别虚拟化 CPU、内存、存储和网络资源,为开发人员提供与其他应用程序逻辑隔离的操作系统视图。
敏捷开发
容器允许开发人员通过避免对依赖关系和环境的担忧来更快地移动。
高效运营
容器是轻量级的,允许我们只使用我们需要的计算资源。
虚拟化与容器化
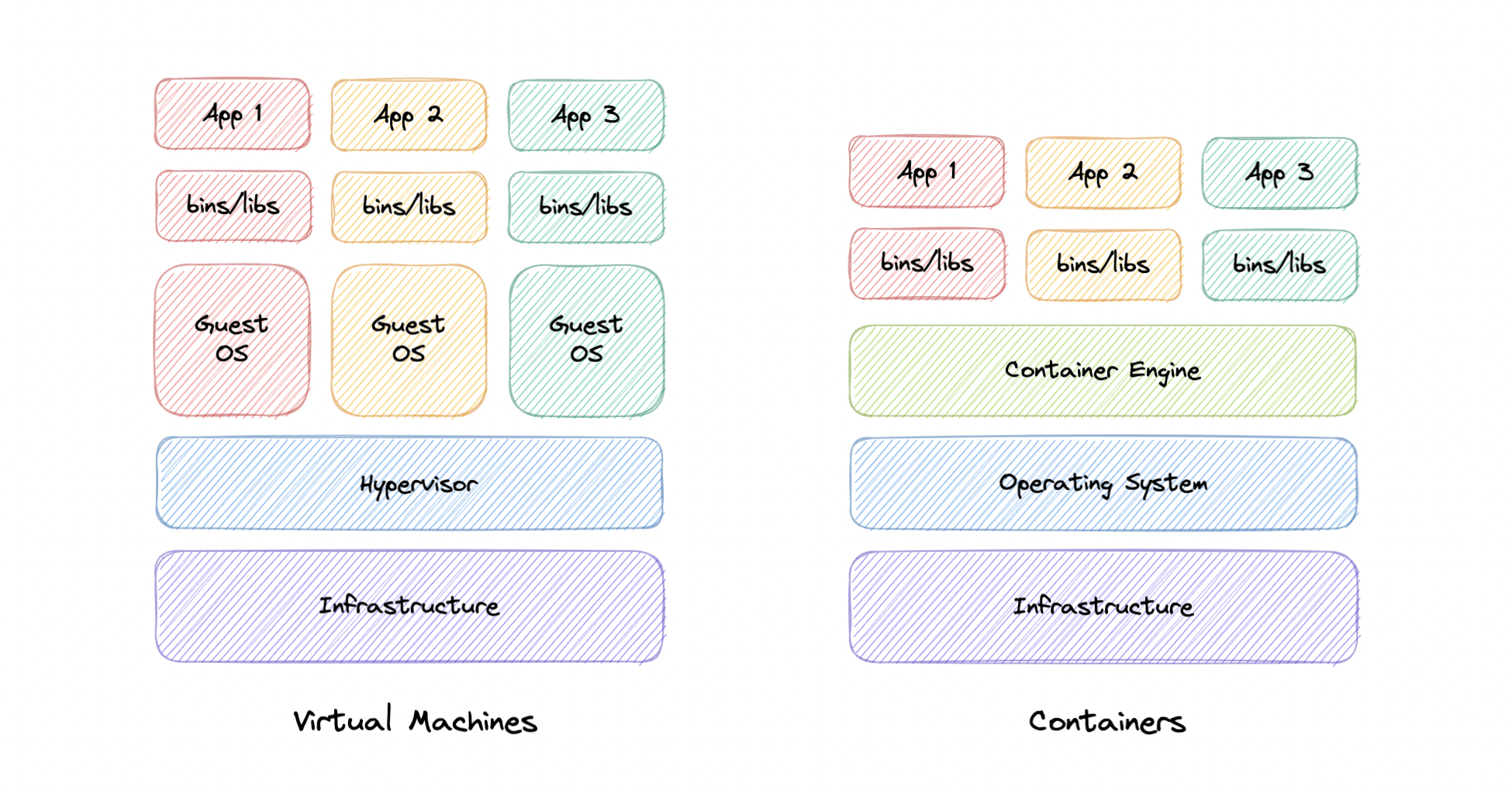
在传统虚拟化中,虚拟机管理程序虚拟化物理硬件。结果是,每个虚拟机都包含一个来宾操作系统、操作系统运行所需的硬件的虚拟副本,以及一个应用程序及其关联的库和依赖项。
容器不是虚拟化底层硬件,而是虚拟化操作系统,因此每个容器仅包含应用程序及其依赖项,使它们比 VM 更轻量级。 容器还共享 OS 内核,并使用 VM 所需内存的一小部分。
OAuth 2.0 和 OpenID Connect (OIDC)
OAuth 2.0 操作系统
OAuth 2.0 代表开放授权,是一种标准,旨在代表用户提供对资源的同意访问,而无需共享用户的凭据。OAuth 2.0 是一种授权协议,而不是身份验证协议,它主要设计为授予对一组资源(例如远程 API 或用户数据)的访问权限。
概念
OAuth 2.0 协议定义了以下实体:
- 资源所有者:拥有受保护资源并可授予对这些资源的访问权限的用户或系统。
- 客户端:客户端是需要访问受保护资源的系统。
- 授权服务器:此服务器接收来自客户端的访问令牌请求,并在成功进行身份验证并征得资源所有者同意后发出这些请求。
- 资源服务器:保护用户资源并接收客户端访问请求的服务器。它接受并验证来自客户端的访问令牌,并返回相应的资源。
- 范围:它们用于准确指定可以授予对资源的访问权限的原因。可接受的范围值以及它们与哪些资源相关,取决于资源服务器。
- 访问令牌:表示代表最终用户访问资源的授权的一段数据。
OAuth 2.0 是如何工作的?
让我们了解一下 OAuth 2.0 的工作原理:
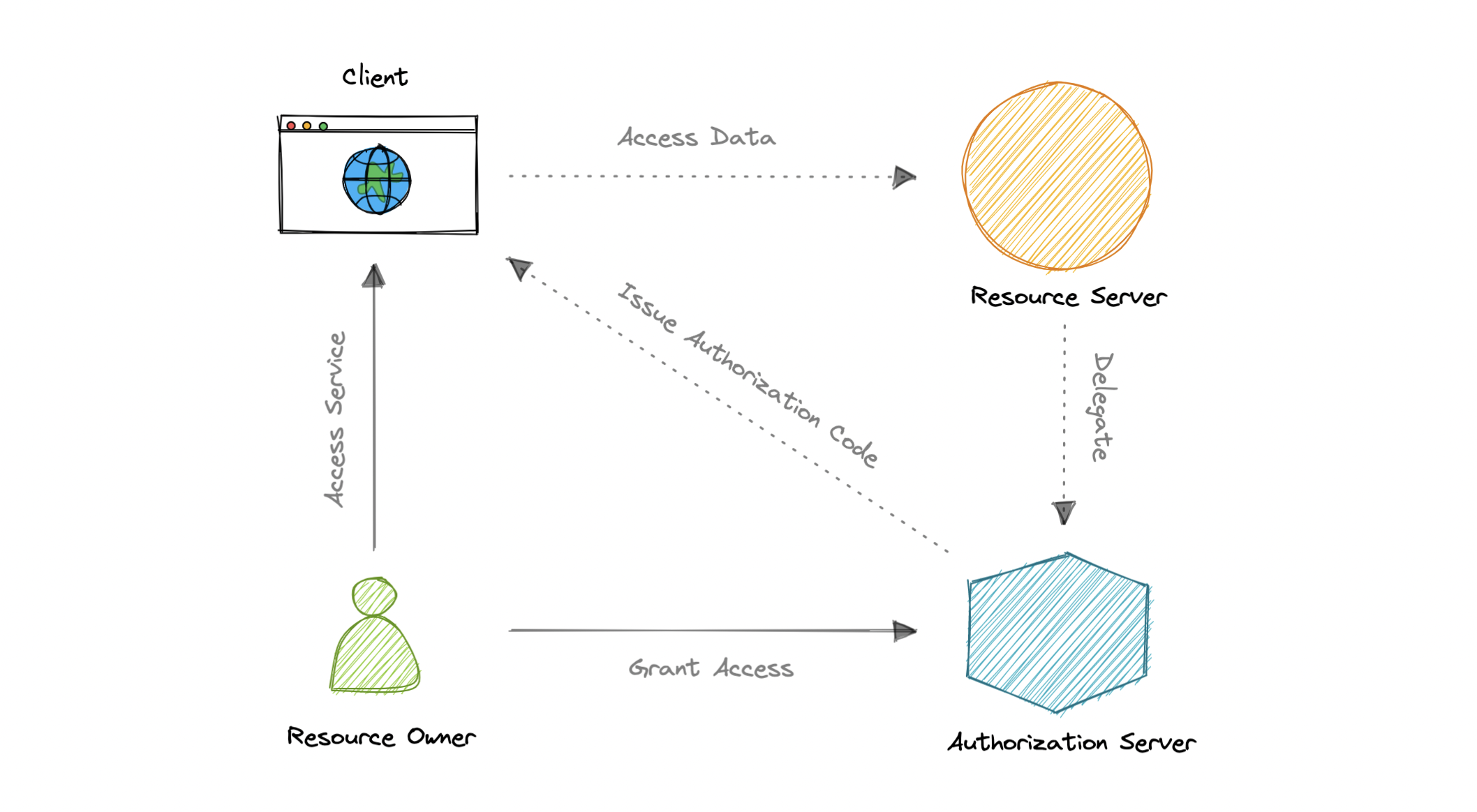
- 客户端从授权服务器请求授权,并提供客户端 ID 和密钥作为标识。它还提供范围和终结点 URI,用于发送访问令牌或授权代码。
- 授权服务器对客户端进行身份验证,并验证请求的作用域是否被允许。
- 资源所有者与授权服务器交互以授予访问权限。
- 授权服务器使用授权代码或访问令牌重定向回客户端,具体取决于授权类型。还可以返回刷新令牌。
- 使用访问令牌,客户端可以从资源服务器请求访问资源。
弊
以下是 OAuth 2.0 最常见的缺点:
- 缺乏内置的安全功能。
- 没有标准实现。
- 没有通用的范围集。
OpenID 连接
OAuth 2.0 仅用于授权,用于授予从一个应用程序到另一个应用程序的数据和功能的访问权限。OpenID Connect (OIDC) 是位于 OAuth 2.0 之上的薄层,它添加了有关登录人员的登录和配置文件信息。
当授权服务器支持 OIDC 时,它有时称为身份提供程序 (IdP),因为它向客户端提供有关资源所有者的信息。OpenID Connect 相对较新,与 OAuth 相比,导致最佳实践的采用率和行业实施率较低。
概念
OpenID Connect (OIDC) 协议定义了以下实体:
- 信赖方:当前应用程序。
- OpenID 提供程序:这实质上是一种中间服务,它向信赖方提供一次性代码。
- 令牌终结点:接受一次性代码 (OTC) 并提供有效期为一小时的访问代码的 Web 服务器。OIDC 和 OAuth 2.0 之间的主要区别在于令牌是使用 JSON Web 令牌 (JWT) 提供的。
- UserInfo 终结点:信赖方与此终结点通信,提供安全令牌并接收有关最终用户的信息
OAuth 2.0 和 OIDC 都易于实现,并且基于 JSON,大多数 Web 和移动应用程序都支持。但是,OpenID Connect (OIDC) 规范比基本 OAuth 规范更严格。
单点登录 (SSO)
单点登录 (SSO) 是一种身份验证过程,在该过程中,用户只需使用一组登录凭据即可访问多个应用程序或网站。这样可以防止用户单独登录到不同的应用程序。
用户凭据和其他标识信息由称为身份提供商 (IdP) 的集中式系统存储和管理。身份提供程序是一个受信任的系统,提供对其他网站和应用程序的访问。
基于单点登录 (SSO) 的身份验证系统通常用于员工需要访问其组织的多个应用程序的企业环境。
组件
让我们讨论一下单点登录 (SSO) 的一些关键组件。
身份提供商 (IdP)
用户身份信息由称为身份提供商 (IdP) 的集中式系统存储和管理。身份提供程序对用户进行身份验证,并提供对服务提供商的访问。
标识提供者可以通过验证用户名和密码或验证由单独的标识提供者提供的有关用户身份的断言来直接对用户进行身份验证。身份提供程序处理用户身份的管理,以便将服务提供商从此责任中解放出来。
服务提供商
服务提供商向最终用户提供服务。它们依赖于标识提供者来断言用户的身份,并且通常有关用户的某些属性由标识提供者管理。服务提供商还可以为用户维护本地帐户以及其服务独有的属性。
身份代理
身份代理充当中介,将多个服务提供商与各种不同的身份提供商连接起来。使用 Identity Broker,我们可以对任何应用程序执行单点登录,而无需遵循协议的麻烦。
SAML
安全断言标记语言是一种开放标准,允许客户端在不同系统之间共享有关标识、身份验证和权限的安全信息。SAML 是使用可扩展标记语言 (XML) 标准实现的,用于共享数据。
SAML 专门启用联合身份验证,使身份提供商 (IdP) 能够无缝、安全地将经过身份验证的身份及其属性传递给服务提供商。
SSO 的工作原理是什么?
现在,让我们讨论一下单点登录的工作原理:
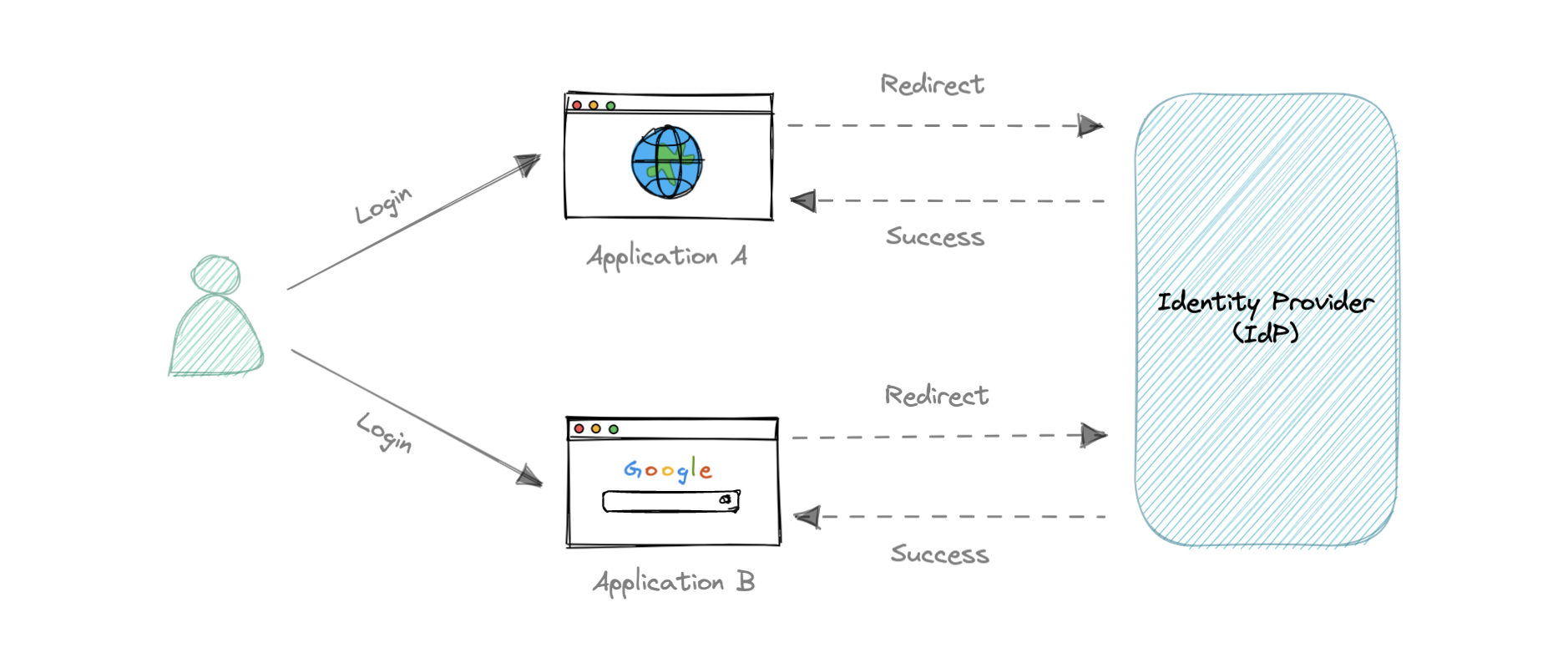
- 用户从其所需的应用程序请求资源。
- 应用程序将用户重定向到身份提供程序 (IdP) 进行身份验证。
- 用户使用其凭据(通常为用户名和密码)登录。
- 身份提供商 (IdP) 将单点登录响应发送回客户端应用程序。
- 应用程序向用户授予访问权限。
SAML 与 OAuth 2.0 和 OpenID Connect (OIDC)
SAML、OAuth 和 OIDC 之间存在许多差异。SAML 使用 XML 传递消息,而 OAuth 和 OIDC 使用 JSON。OAuth 提供更简单的体验,而 SAML 则面向企业安全。
OAuth 和 OIDC 广泛使用 RESTful 通信,这就是为什么移动和现代 Web 应用程序发现 OAuth 和 OIDC 为用户提供了更好的体验。另一方面,SAML 会在浏览器中删除一个会话 cookie,允许用户访问某些网页。这非常适合短期工作负载。
OIDC 对开发人员友好且更易于实施,这拓宽了可以实施它的用例。它可以通过所有常见编程语言的免费库快速从头开始实现。SAML 的安装和维护可能很复杂,只有企业规模的公司才能很好地处理。
OpenID Connect 本质上是 OAuth 框架之上的一层。因此,它可以提供一个内置的权限层,要求用户同意服务提供商可能访问的内容。尽管 SAML 也能够允许同意流,但它是通过开发人员执行的硬编码来实现的,而不是作为其协议的一部分。
这两种身份验证协议都擅长它们的功能。与往常一样,很大程度上取决于我们的特定用例和目标受众。
优势
以下是使用单点登录的好处:
- 易于使用,因为用户只需要记住一组凭据。
- 易于访问,无需经过冗长的授权过程。
- 强制实施安全性和合规性以保护敏感数据。
- 通过降低 IT 支持成本和管理时间来简化管理。
弊
以下是单点登录的一些缺点:
- 单一密码漏洞,如果主 SSO 密码被泄露,所有受支持的应用程序都会被泄露。
- 使用单点登录的身份验证过程比传统身份验证慢,因为每个应用程序都必须请求 SSO 提供程序进行验证。
例子
以下是一些常用的身份提供商 (IdP):
SSL、TLS、mTLS
让我们简要讨论一些重要的通信安全协议,例如 SSL、TLS 和 mTLS。我想说的是,从“大局”系统设计的角度来看,这个话题不是很重要,但仍然值得了解。
有限责任证书
SSL 代表安全套接字层,它指的是用于加密和保护互联网上发生的通信的协议。它最初于 1995 年开发,但后来被弃用,取而代之的是 TLS(传输层安全性)。
如果它被弃用,为什么它被称为SSL证书?
大多数主要证书提供商仍将证书称为 SSL 证书,这就是命名约定仍然存在的原因。
为什么SSL如此重要?
最初,网络上的数据是以明文形式传输的,任何人都可以在截获消息时阅读。创建 SSL 是为了纠正此问题并保护用户隐私。通过加密用户和 Web 服务器之间的任何数据,SSL 还可以通过防止攻击者篡改传输中的数据来阻止某些类型的网络攻击。
红绿灯系统
传输层安全性 (TLS) 是一种广泛采用的安全协议,旨在促进互联网通信的隐私和数据安全。TLS 是从以前的加密协议演变而来的,称为安全套接字层 (SSL)。TLS 的一个主要用例是加密 Web 应用程序和服务器之间的通信。
TLS 协议的实现有三个主要组成部分:
- 加密:隐藏从第三方传输的数据。
- 身份验证:确保交换信息的各方是他们声称的身份。
- 完整性:验证数据是否被伪造或篡改。
mTLS协议
双向 TLS 或 mTLS 是一种相互身份验证的方法。mTLS 通过验证网络连接两端的各方是否拥有正确的私钥来确保他们声称的身份。其各自 TLS 证书中的信息提供了额外的验证。
为什么使用 mTLS?
mTLS 有助于确保客户端和服务器之间的流量在两个方向上都是安全和可信的。这为登录到组织网络或应用程序的用户提供了额外的安全层。它还验证与不遵循登录过程的客户端设备(如物联网 (IoT) 设备)的连接。
如今,微服务或分布式系统在零信任安全模型中通常使用 mTLS 来相互验证。
系统设计面试
系统设计是一个非常广泛的话题,系统设计面试旨在评估你为抽象问题提供技术解决方案的能力,因此,它们不是为特定答案而设计的。系统设计面试的独特之处在于候选人和面试官之间的双向性质。
在不同的工程水平上,期望也大不相同。这是因为具有丰富实践经验的人会与业内新人截然不同。因此,很难想出一个单一的策略来帮助我们在面试中保持井井有条。
让我们看一下系统设计面试的一些常见策略:
需求说明
从本质上讲,系统设计面试问题是模糊或抽象的。询问有关问题的确切范围的问题,并在面试初期澄清功能要求至关重要。通常,需求分为三个部分:
功能要求
这些是最终用户特别要求作为系统应提供的基本功能的要求。所有这些功能都需要作为合同的一部分合并到系统中。
例如:
- “我们需要为这个系统设计哪些功能?”
- “我们在设计中需要考虑哪些边缘情况(如果有的话)?”
非功能性需求
这些是系统根据项目合同必须满足的质量约束。这些因素的实施优先级或程度因项目而异。它们也称为非行为要求。例如,可移植性、可维护性、可靠性、可扩展性、安全性等。
例如:
- “每个请求都应以最小的延迟进行处理”
- “系统应具有高可用性”
扩展要求
这些基本上是“很高兴拥有”的要求,可能超出了系统的范围。
例如:
- “我们的系统应该记录指标和分析”
- “服务运行状况和性能监控?”
估计和约束
估计我们将要设计的系统的规模。提出以下问题很重要:
- “这个系统需要处理的规模有多大?”
- “我们系统的读/写比率是多少?”
- “每秒有多少个请求?”
- “需要多少存储空间?”
这些问题将帮助我们以后扩展我们的设计。
数据模型设计
一旦我们有了估计值,我们就可以开始定义数据库模式了。在面试的早期阶段这样做将有助于我们了解数据流,这是每个系统的核心。在此步骤中,我们基本上定义了所有实体以及它们之间的关系。
- “系统中有哪些不同的实体?”
- “这些实体之间有什么关系?”
- “我们需要多少张桌子?”
- “NoSQL是更好的选择吗?”
API 设计
接下来,我们可以开始为系统设计 API。这些 API 将帮助我们明确定义系统的期望。我们不必编写任何代码,只需一个简单的接口来定义 API 要求,例如参数、函数、类、类型、实体等。
例如:
createUser(name: string, email: string): User建议使界面尽可能简单,稍后在满足扩展需求时再返回。
高级组件设计
现在我们已经建立了我们的数据模型和 API 设计,是时候确定解决我们的问题所需的系统组件(如负载均衡器、API 网关等)并起草我们系统的第一个设计了。
- “设计单体架构还是微服务架构最好?”
- “我们应该使用什么类型的数据库?”
一旦我们有了基本的图表,我们就可以开始与面试官从客户的角度讨论系统将如何工作。
详细设计
现在是时候详细介绍我们设计的系统的主要组件了。与往常一样,与面试官讨论哪个部分可能需要进一步改进。
这是一个很好的机会来展示你在专业领域的经验。介绍不同的方法、优点和缺点。解释你的设计决策,并用示例来支持它们。这也是讨论系统可能能够支持的任何其他功能的好时机,尽管这是可选的。
- “我们应该如何对数据进行分区?”
- “负载分配呢?”
- “我们应该使用缓存吗?”
- “我们将如何处理突然激增的流量?”
此外,尽量不要对某些技术过于固执己见,诸如“我相信NoSQL数据库更好,SQL数据库不可扩展”之类的陈述反映得很差。作为一个多年来采访过很多人的人,我在这里的两分钱是谦虚地对待你知道的和你不知道的。使用你现有的知识与示例来导航面试的这一部分。
识别并解决瓶颈
最后,是时候讨论瓶颈和缓解瓶颈的方法了。以下是一些要问的重要问题:
- “我们有足够的数据库副本吗?”
- “有没有单点故障?”
- “需要数据库分片吗?”
- “我们如何才能使我们的系统更加强大?”
- “如何提高缓存的可用性?”
请务必阅读你正在面试的公司的工程博客。这将帮助你了解他们正在使用的技术堆栈以及哪些问题对他们很重要。
URL 缩短器
让我们设计一个 URL 缩短器,类似于 Bitly、TinyURL 等服务。
什么是 URL 缩短器?
URL 缩短器服务为长 URL 创建别名或短 URL。当用户访问这些短链接时,系统会将他们重定向到原始 URL。
例如,可以将以下长 URL 更改为较短的 URL。
长网址:https://karanpratapsingh.com/courses/system-design/url-shortener
为什么我们需要一个 URL 缩短器?
当我们共享 URL 时,URL 缩短器通常会节省空间。用户也不太可能输入错误较短的 URL。此外,我们还可以优化跨设备的链接,这使我们能够跟踪单个链接。
要求
我们的URL缩短系统应满足以下要求:
功能要求
- 给定一个 URL,我们的服务应该为其生成一个更短且唯一的别名。
- 用户在访问短链接时,应重定向到原始 URL。
- 链接应在默认时间跨度后过期。
非功能性需求
- 高可用性和最小延迟。
- 该系统应具有可扩展性和效率。
扩展要求
- 防止滥用服务。
- 记录重定向的分析和指标。
估计和约束
让我们从估计和约束开始。
注意:请务必与面试官核实任何与规模或交通相关的假设。
交通
这将是一个读取密集型系统,因此让我们假设每月生成 1 亿个链接的读/写比率。
100:1
每月读取/写入次数
对于每月的读取次数:
$$ 100 \times 100 \space million = 10 \space billion/月 $$
同样,对于写入:
$$ 1 \times 100 \space million = 100 \space million/月 $$
我们系统的每秒请求数 (RPS) 是多少?
每月 1 亿个请求相当于每秒 40 个请求。
$$ \frac{100 \space million}{(30 \space days \times 24 \space hrs \times 3600 \space seconds)} = \sim 40 \space URLs/秒 $$
使用读/写比率时,重定向次数将为:
100:1
$$ 100 \times 40 \space URLs/秒 = 4000 \space requests/秒 $$
带宽
由于我们预计每秒大约有 40 个 URL,如果我们假设每个请求的大小为 500 字节,那么写入请求的总传入数据将为:
$$ 40 \times 500 \space 字节 = 20 \space KB/秒 $$
同样,对于读取请求,由于我们预计大约有 4K 重定向,因此总传出数据将为:
$$ 4000 \space URLs/秒 \times 500 \space bytes = \sim 2 \space MB/秒 $$
存储
对于存储,我们假设我们将每个链接或记录存储在数据库中 10 年。由于我们预计每月大约有 1 亿个新请求,因此我们需要存储的记录总数为:
$$ 100 \space million \times 10\space years \times 12 \space months = 12 \space billion $$
与前面一样,如果我们假设每条存储的记录大约为 500 字节。我们将需要大约 6TB 的存储空间:
$$ 12 \space billion \times 500 \space 字节 = 6 \space TB $$
缓存
对于缓存,我们将遵循经典的帕累托原则,也称为 80/20 规则。这意味着 80% 的请求是针对 20% 的数据,因此我们可以缓存大约 20% 的请求。
由于我们每秒收到大约 4K 的读取或重定向请求,这意味着每天有 350M 个请求。
$$ 4000 \space URLs/秒 \times 24 \space 小时 \times 3600 \space 秒 = \sim 350 \space 百万 \space 请求/天 $$
因此,我们每天需要大约 35GB 的内存。
$$ 20 \space 百分比 \times 350 \space 百万 \times 500 \space 字节 = 35 \space GB/天 $$
高级估计
以下是我们的高层次估计:
| 类型 | 估计 |
|---|---|
| 写入(新 URL) | 40/秒 |
| 读取(重定向) | 4K/秒 |
| 带宽(传入) | 20 KB/秒 |
| 带宽(传出) | 2 MB/秒 |
| 存储(10 年) | 6结核病 |
| 内存(缓存) | ~35 GB/天 |
数据模型设计
接下来,我们将重点介绍数据模型设计。以下是我们的数据库架构:
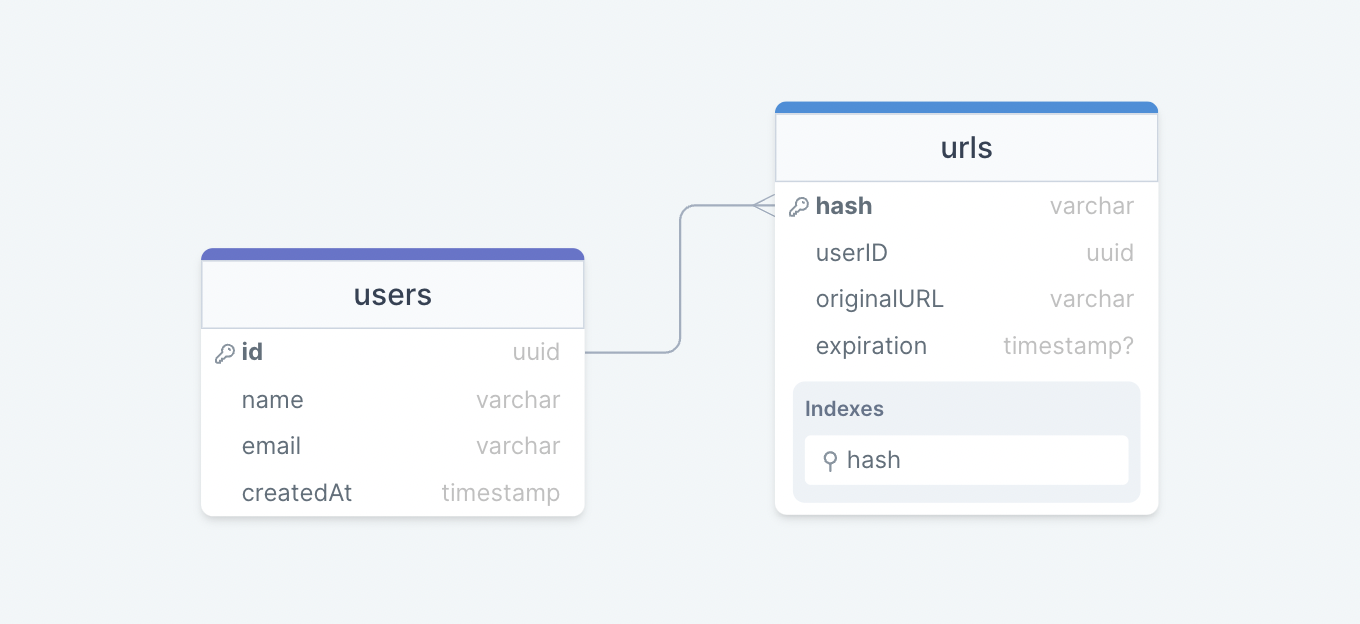
最初,我们可以从两个表开始:
用户
存储用户的详细信息,如、、等。
name
createdAt
网址
包含新的短 URL 的属性,如 、 、 和创建短 URL 的用户的属性。我们还可以将该列用作索引来提高查询性能。
expiration
hash
originalURL
userID
hash
我们应该使用什么样的数据库?
由于数据不是强关系的,因此 Amazon DynamoDB、Apache Cassandra 或 MongoDB 等 NoSQL 数据库将是更好的选择,如果我们决定使用 SQL 数据库,那么我们可以使用 Azure SQL 数据库或 Amazon RDS 之类的数据库。
有关详细信息,请参阅 SQL 与 NoSQL。
API 设计
让我们为我们的服务做一个基本的 API 设计:
创建 URL
此 API 应在给定原始 URL 的情况下在我们的系统中创建一个新的短 URL。
createURL(apiKey: string, originalURL: string, expiration?: Date): string参数
API Key():用户提供的API密钥。
string
原始 URL():要缩短的原始 URL。
string
Expiration ():新 URL 的到期日期(可选)。
Date
返回
短 URL ():新缩短的 URL。
string
获取网址
此 API 应从给定的短 URL 中检索原始 URL。
getURL(apiKey: string, shortURL: string): string参数
API Key():用户提供的API密钥。
string
短 URL ():映射到原始 URL 的短 URL。
string
返回
原始 URL():要检索的原始 URL。
string
删除 URL
此 API 应从我们的系统中删除给定的 shortURL。
deleteURL(apiKey: string, shortURL: string): boolean参数
API Key():用户提供的API密钥。
string
短 URL():要删除的短 URL。
string
返回
结果 ():表示操作是否成功。
boolean
为什么我们需要 API 密钥?
你一定已经注意到,我们正在使用 API 密钥来防止滥用我们的服务。使用此 API 密钥,我们可以将用户限制为每秒或每分钟一定数量的请求。对于开发人员 API 来说,这是一个非常标准的做法,应该涵盖我们的扩展需求。
高级设计
现在让我们对系统进行高级设计。
URL 编码
我们系统的主要目标是缩短给定的 URL,让我们看看不同的方法:
Base62 方法
在这种方法中,我们可以使用 Base62 对原始 URL 进行编码,该 URL 由大写字母 A-Z、小写字母 a-z 和数字 0-9 组成。
$$ \space URL 的数量 \space = 62^N $$
哪里
N:生成的 URL 中的字符数。
因此,如果我们想生成一个长度为 7 个字符的 URL,我们将生成 ~3.5 万亿个不同的 URL。
$$ \begin{gather*} 62^5 = \sim 916 \space million \space URLs \ 62^6 = \sim 56.8 \space billion \space URLs \ 62^7 = \sim 3.5 \space trillion \space URLs \end{gather*} $$
这是这里最简单的解决方案,但它不能保证不重复或防冲突的密钥。
MD5 方法
MD5 消息摘要算法是一种广泛使用的哈希函数,可生成 128 位哈希值(或 32 个十六进制数字)。我们可以使用这 32 个十六进制数字来生成 7 个字符长的 URL。
$$ MD5(original_url) \rightarrow base62encode \rightarrow 哈希 $$
然而,这给我们带来了一个新问题,那就是重复和冲突。我们可以尝试重新计算哈希值,直到找到一个唯一的哈希值,但这会增加我们系统的开销。最好寻找更具可扩展性的方法。
反击方法
在这种方法中,我们将从单个服务器开始,该服务器将维护生成的密钥计数。一旦我们的服务收到请求,它就可以联系到计数器,该计数器返回一个唯一的编号并递增计数器。当下一个请求到来时,计数器再次返回唯一编号,如此循环。
$$ 计数器(0-3.5 \space trillion) \rightarrow base62encode \rightarrow hash $$
这种方法的问题在于,它可能很快成为单点故障。如果我们运行计数器的多个实例,我们可能会发生冲突,因为它本质上是一个分布式系统。
为了解决这个问题,我们可以使用分布式系统管理器,例如 Zookeeper,它可以提供分布式同步。Zookeeper 可以为我们的服务器维护多个范围。
$$ \begin{align*} & 范围 \space 1: \space 1 \rightarrow 1,000,000 \ & Range \space 2: \space 1,000,001 \rightarrow 2,000,000 \ & Range \space 3: \space 2,000,001 \rightarrow 3,000,000 \ & ... \end{align*} $$
一旦服务器达到其最大范围,Zookeeper 就会将未使用的计数器范围分配给新服务器。这种方法可以保证 URL 不重复且防冲突。此外,我们可以运行多个 Zookeeper 实例来消除单点故障。
密钥生成服务 (KGS)
正如我们所讨论的,在没有重复和冲突的情况下大规模生成唯一密钥可能是一个挑战。为了解决这个问题,我们可以创建一个独立的密钥生成服务(KGS),它提前生成一个唯一的密钥,并将其存储在一个单独的数据库中供以后使用。这种方法可以使我们的事情变得简单。
如何处理并发访问?
使用密钥后,我们可以在数据库中标记它以确保我们不会重复使用它,但是,如果有多个服务器实例同时读取数据,则两个或多个服务器可能会尝试使用相同的密钥。
解决此问题的最简单方法是将密钥存储在两个表中。一旦使用钥匙,我们就会将其移动到一个单独的桌子上,并适当锁定到位。此外,为了提高读取能力,我们可以将一些密钥保留在内存中。
KGS 数据库估计值
根据我们的讨论,我们可以生成多达 ~568 亿个独特的 6 个字符长的密钥,这将导致我们必须存储 300 GB 的密钥。
$$ 6 个 \space 字符 \times 56.8 \space billion = \sim 390 \space GB $$
虽然对于这个简单的用例来说,390 GB 似乎很多,但重要的是要记住,这是在我们的整个服务生命周期内,密钥数据库的大小不会像我们的主数据库那样增加。
缓存
现在,让我们谈谈缓存。根据我们的估计,我们每天需要大约 ~35 GB 的内存来缓存 20% 的传入请求。对于此用例,我们可以将 Redis 或 Memcached 服务器与 API 服务器一起使用。
有关详细信息,请参阅缓存。
设计
现在我们已经确定了一些核心组件,让我们来做系统设计的初稿。
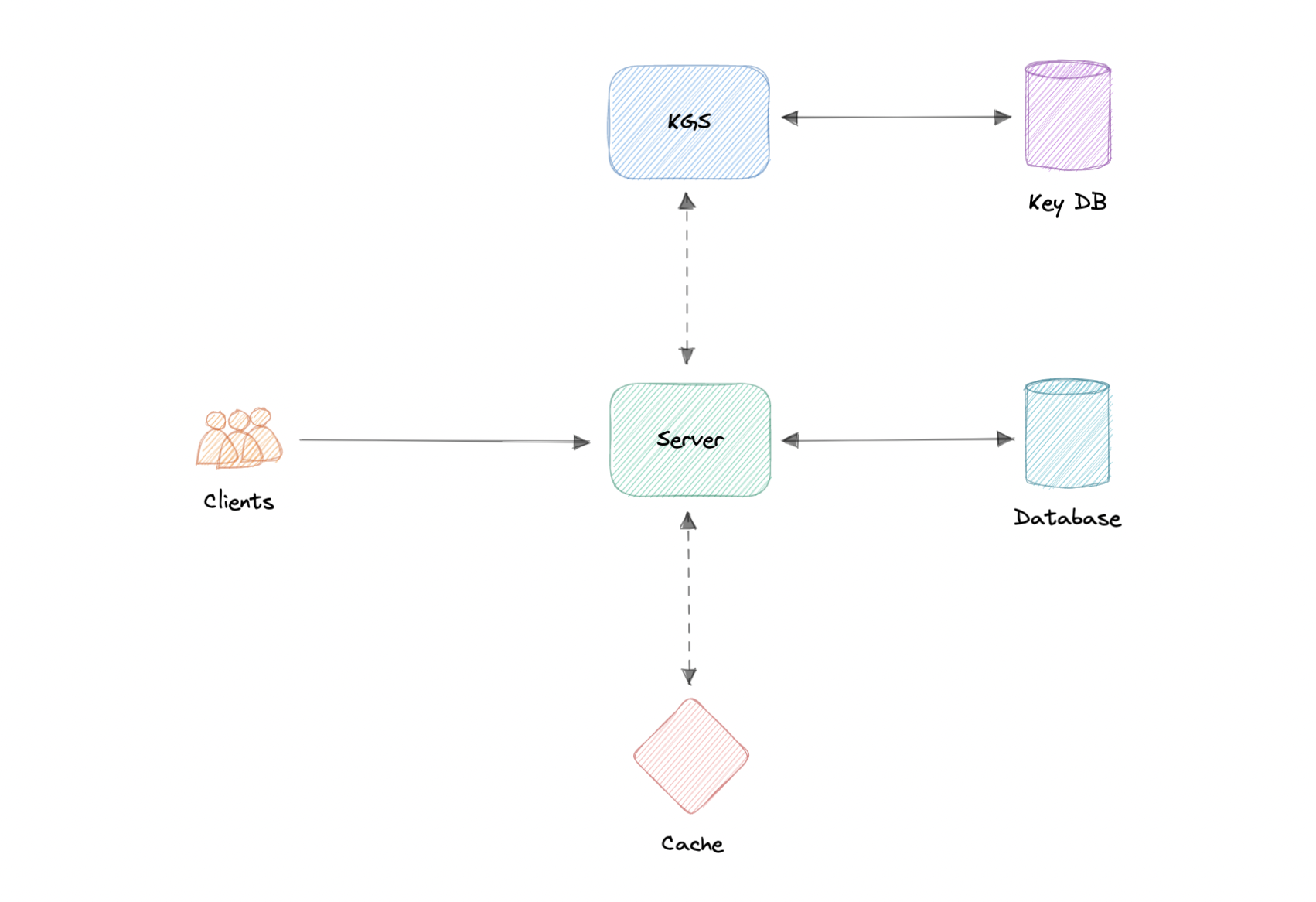
其工作原理如下:
创建新 URL
- 当用户创建新的 URL 时,我们的 API 服务器会从密钥生成服务 (KGS) 请求一个新的唯一密钥。
- 密钥生成服务向 API 服务器提供唯一的密钥,并将密钥标记为已使用。
- API 服务器将新的 URL 条目写入数据库和缓存。
- 我们的服务向用户返回 HTTP 201(已创建)响应。
访问 URL
- 当客户端导航到某个短 URL 时,请求将发送到 API 服务器。
- 请求首先命中缓存,如果在那里找不到该条目,则从数据库中检索该条目,并向原始 URL 发出 HTTP 301(重定向)。
- 如果在数据库中仍找不到密钥,则会向用户发送 HTTP 404(未找到)错误。
详细设计
是时候讨论我们设计的更精细的细节了。
数据分区
为了扩展我们的数据库,我们需要对数据进行分区。水平分区(又名分片)可能是一个很好的第一步。我们可以使用分区方案,例如:
- 基于哈希的分区
- 基于列表的分区
- 基于范围的分区
- 复合分区
上述方法仍然会导致数据和负载分布不均匀,我们可以使用一致哈希来解决此问题。
数据库清理
这更像是我们服务的维护步骤,取决于我们是保留过期条目还是删除它们。如果我们决定删除过期的条目,我们可以通过两种不同的方式解决这个问题:
主动清理
在主动清理中,我们将运行单独的清理服务,该服务将定期从我们的存储和缓存中删除过期的链接。这将是一个非常轻量级的服务,就像 cron 作业一样。
被动清理
对于被动清理,我们可以在用户尝试访问过期链接时删除该条目。这可以确保对我们的数据库和缓存进行延迟清理。
缓存
现在让我们谈谈缓存。
要使用哪种缓存逐出策略?
正如我们之前所讨论的,我们可以使用 Redis 或 Memcached 等解决方案并缓存 20% 的每日流量,但哪种缓存逐出策略最适合我们的需求?
最近最少使用 (LRU) 对于我们的系统来说可能是一个很好的策略。在此策略中,我们首先丢弃最近使用最少的密钥。
如何处理缓存未命中?
每当缓存未命中时,我们的服务器都可以直接访问数据库并使用新条目更新缓存。
指标和分析
记录分析和指标是我们的扩展要求之一。我们可以在数据库中的 URL 条目旁边存储和更新元数据,例如访问者的国家/地区、平台、浏览量等。
安全
为了安全起见,我们可以引入私有 URL 和授权。可以使用单独的表来存储有权访问特定 URL 的用户 ID。如果用户没有适当的权限,我们可能会返回 HTTP 401(未经授权)错误。
我们还可以使用 API 网关,因为它们可以支持开箱即用的授权、速率限制和负载均衡等功能。
识别并解决瓶颈
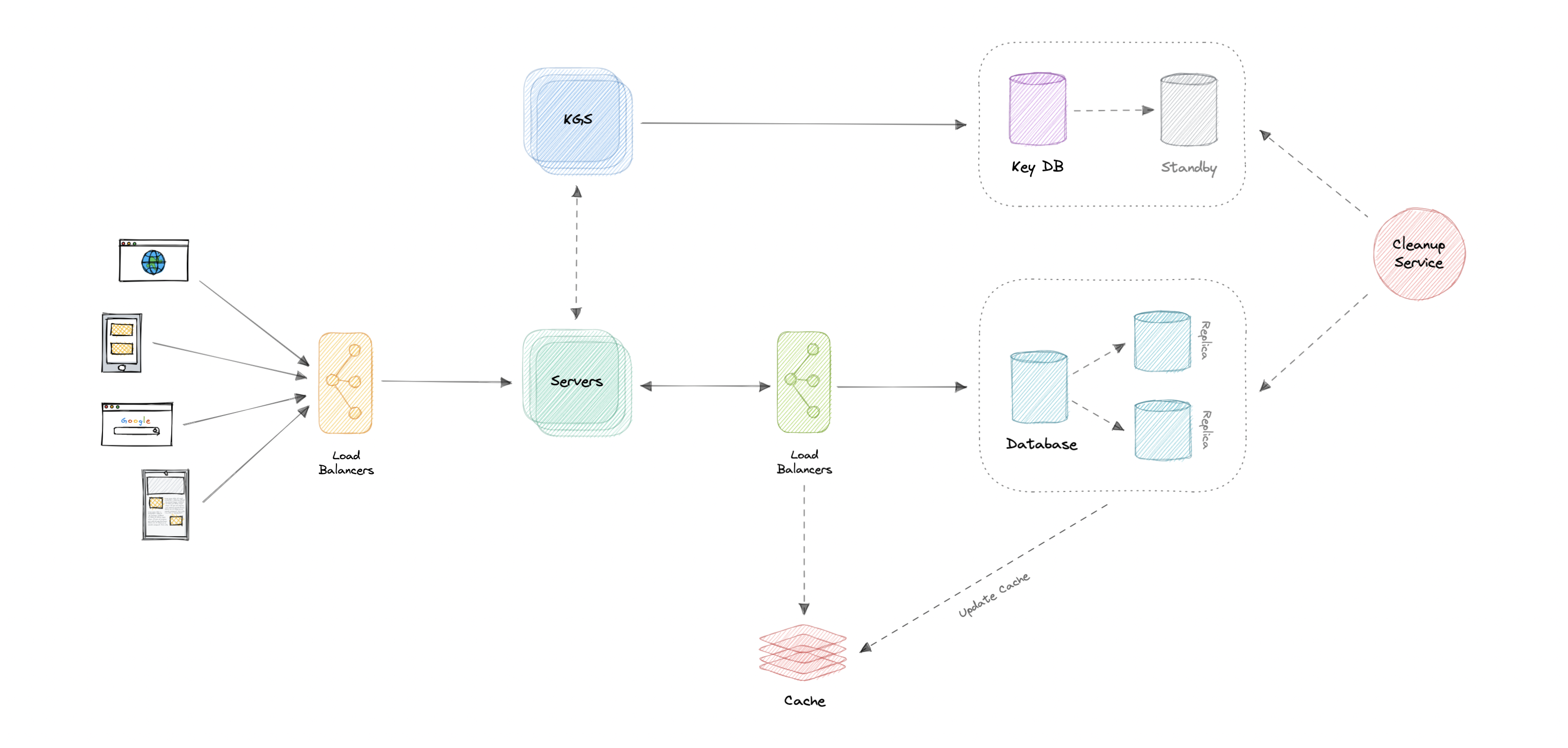
让我们识别并解决设计中的瓶颈,例如单点故障:
- “如果 API 服务或密钥生成服务崩溃怎么办?”
- “我们将如何在组件之间分配流量?”
- “我们如何减少数据库的负载?”
- “如果KGS使用的密钥数据库出现故障怎么办?”
- “如何提高缓存的可用性?”
为了使我们的系统更具弹性,我们可以执行以下操作:
- 运行我们的服务器和密钥生成服务的多个实例。
- 在客户端、服务器、数据库和缓存服务器之间引入负载平衡器。
- 为我们的数据库使用多个只读副本,因为它是一个读取密集型系统。
- 密钥数据库的备用副本,以防它发生故障。
- 分布式缓存的多个实例和副本。
WhatsApp的
让我们设计一个类似WhatsApp的即时通讯服务,类似于Facebook Messenger和微信等服务。
什么是WhatsApp?
WhatsApp 是一个聊天应用程序,为其用户提供即时消息服务。它是地球上使用最多的移动应用程序之一,连接了 180+ 个国家/地区的超过 20 亿用户。WhatsApp 也可以在网络上找到。
要求
我们的系统应满足以下要求:
功能要求
- 应该支持一对一聊天。
- 群聊(最多100人)。
- 应支持文件共享(图像、视频等)。
非功能性需求
- 高可用性和最小延迟。
- 该系统应具有可扩展性和效率。
扩展要求
- 邮件的已发送、已送达和已读回执。
- 显示用户的上次查看时间。
- 推送通知。
估计和约束
让我们从估计和约束开始。
注意:请务必与面试官核实任何与规模或交通相关的假设。
交通
假设我们有 5000 万日活跃用户 (DAU),平均每个用户每天至少向 4 个不同的人发送 10 条消息。这每天为我们提供 20 亿条消息。
$$ 50 \space million \times 40 \space 消息 = 2 \space billion/天 $$
邮件还可以包含图像、视频或其他文件等媒体。我们可以假设 5% 的消息是用户共享的媒体文件,这为我们提供了额外的 1 亿个文件,我们需要存储。
$$ 5 \space percent \times 2 \space billion = 100 \space million/天 $$
我们系统的每秒请求数 (RPS) 是多少?
每天 20 亿个请求转化为每秒 24K 个请求。
$$ \frac{2 \space billion}{(24 \space hrs \times 3600 \space seconds)} = \sim 24K \space requests/second $$
存储
如果我们假设每条消息平均为 100 字节,则每天将需要大约 200 GB 的数据库存储。
$$ 2 \space billion \times 100 \space 字节 = \sim 200 \space GB/天 $$
根据我们的要求,我们还知道,我们每天大约5%的消息(1亿条)是媒体文件。如果我们假设每个文件平均为 100 KB,则每天需要 10 TB 的存储空间。
$$ 100 \space million \times 100 \space KB = 10 \space TB/天 $$
在 10 年内,我们将需要大约 38 PB 的存储空间。
$$ (10 \space TB + 0.2 \space TB) \times 10 \space years \times 365 \space days = \sim 38 \space PB $$
带宽
由于我们的系统每天处理 10.2 TB 的入口,因此我们需要至少每秒约 120 MB 的带宽。
$$ \frac{10.2 \space TB}{(24 \space hrs \times 3600 \space seconds)} = \sim 120 \space MB/秒 $$
高级估计
以下是我们的高层次估计:
| 类型 | 估计 |
|---|---|
| 每日活跃用户 (DAU) | 5000万 |
| 每秒请求数 (RPS) | 24K/秒 |
| 存储(每天) | ~10.2 结核病 |
| 存储(10 年) | ~38 PB |
| 带宽 | ~120 MB/秒 |
数据模型设计
这是反映我们要求的通用数据模型。
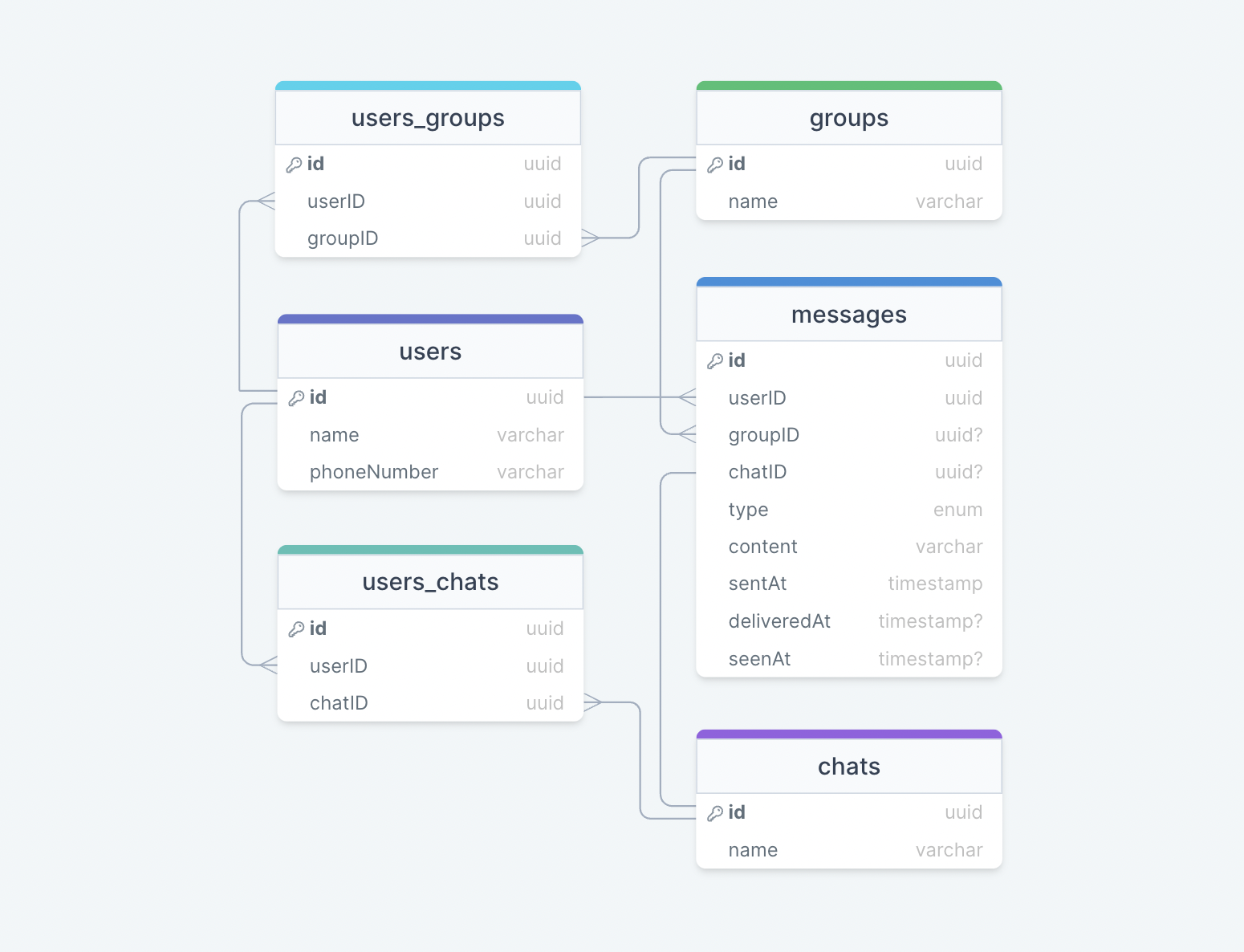
我们有以下表格:
用户
此表将包含用户的信息,例如 、 和其他详细信息。
name
phoneNumber
消息
顾名思义,此表将存储具有(文本、图像、视频等)等属性的消息,以及消息传递的时间戳。该消息还将具有相应的 或 .
type
content
chatID
groupID
聊天
此表基本上表示两个用户之间的私有聊天,可以包含多条消息。
users_chats
此表映射用户和聊天,因为多个用户可以有多个聊天(N:M 关系),反之亦然。
组
此表表示由多个用户组成的组。
users_groups
此表映射用户和组,因为多个用户可以是多个组的一部分(N:M 关系),反之亦然。
我们应该使用什么样的数据库?
虽然我们的数据模型看起来很有关系,但我们不一定需要将所有内容存储在单个数据库中,因为这会限制我们的可扩展性并迅速成为瓶颈。
我们将在不同的服务之间拆分数据,每个服务都对特定表拥有所有权。然后,我们可以在用例中使用关系数据库(如 PostgreSQL)或分布式 NoSQL 数据库(如 Apache Cassandra)。
API 设计
让我们为我们的服务做一个基本的 API 设计:
获取所有聊天或群组
此 API 将获取给定的所有聊天或群组。
userID
getAll(userID: UUID): Chat[] | Group[]参数
用户ID():当前用户的ID。
UUID
返回
结果 ():用户所属的所有聊天和群组。
Chat[] | Group[]
获取消息
获取给定(聊天或群组 ID)的用户的所有消息。
channelID
getMessages(userID: UUID, channelID: UUID): Message[]参数
用户ID():当前用户的ID。
UUID
频道 ID ():需要从中检索消息的频道(聊天或群组)的 ID。
UUID
返回
消息 ():给定聊天或群组中的所有消息。
Message[]
发送消息
将消息从用户发送到频道(聊天或群组)。
sendMessage(userID: UUID, channelID: UUID, message: Message): boolean参数
用户ID():当前用户的ID。
UUID
频道 ID ():用户要向其发送消息的频道(聊天或群组)的 ID。
UUID
消息 ():用户要发送的消息(文本、图像、视频等)。
Message
返回
结果 ():表示操作是否成功。
boolean
加入或退出频道
允许用户加入或离开频道(聊天或群组)。
joinGroup(userID: UUID, channelID: UUID): boolean
leaveGroup(userID: UUID, channelID: UUID): boolean参数
用户ID():当前用户的ID。
UUID
频道 ID ():用户要加入或退出的频道(聊天或群组)的 ID。
UUID
返回
结果 ():表示操作是否成功。
boolean
高级设计
现在让我们对系统进行高级设计。
建筑
我们将使用微服务架构,因为它可以更轻松地横向扩展和解耦我们的服务。每个服务都拥有自己的数据模型的所有权。让我们试着将我们的系统划分为一些核心服务。
用户服务
这是一项基于 HTTP 的服务,用于处理与用户相关的问题,例如身份验证和用户信息。
聊天服务
聊天服务将使用 WebSockets 并与客户端建立连接,以处理聊天和群组消息相关功能。我们还可以使用缓存来跟踪所有活动连接,类似于会话,这将有助于我们确定用户是否在线。
通知服务
此服务将简单地向用户发送推送通知。具体讨论将单独讨论。
在线状态服务
状态服务将跟踪所有用户的上次查看状态。具体讨论将单独讨论。
媒体服务
此服务将处理媒体(图像、视频、文件等)上传。具体讨论将单独讨论。
服务间通信和服务发现呢?
由于我们的架构是基于微服务的,因此服务也将相互通信。一般来说,REST或HTTP表现良好,但我们可以使用gRPC进一步提高性能,因为gRPC更轻量级、更高效。
服务发现是我们必须考虑的另一件事。我们还可以使用服务网格,在各个服务之间实现可管理、 Observable 和安全的通信。
注意:详细了解 REST、GraphQL、gRPC 以及它们之间的比较。
实时消息传递
我们如何有效地发送和接收消息?我们有两种不同的选择:
拉取模型
客户端可以定期向服务器发送 HTTP 请求,以检查是否有任何新消息。这可以通过长轮询之类的方式来实现。
推送模型
客户端打开与服务器的长期连接,一旦有新数据可用,它就会被推送到客户端。为此,我们可以使用 WebSockets 或服务器发送事件 (SSE)。
拉模型方法不可扩展,因为它会在我们的服务器上产生不必要的请求开销,并且大多数时候响应将是空的,从而浪费了我们的资源。为了最大程度地减少延迟,将推送模型与 WebSockets 一起使用是更好的选择,因为这样我们就可以在数据可用时将数据推送到客户端,而不会有任何延迟,前提是与客户端的连接是开放的。此外,WebSockets 提供全双工通信,这与服务器发送事件 (SSE) 不同,后者只是单向的。
注意:详细了解长轮询、WebSockets、服务器发送事件 (SSE)。
最后一次出现
为了实现上次看到的功能,我们可以使用心跳机制,客户端可以定期 ping 服务器,指示其活动状态。由于这需要尽可能低的开销,我们可以将最后一个活动时间戳存储在缓存中,如下所示:
| 钥匙 | 价值 |
|---|---|
| 用户 A | 2022-07-01T14:32:50 |
| 用户 B | 2022-07-05T05:10:35 |
| 用户 C | 2022-07-10T04:33:25 |
这将为我们提供用户上次处于活动状态的时间。此功能将由 Presence Service 与 Redis 或 Memcached 结合使用作为我们的缓存来处理。
实现这一点的另一种方法是跟踪用户的最新操作,一旦最后一个活动超过某个阈值,例如“用户在过去 30 秒内没有执行任何操作”,我们可以将用户显示为离线,并且最后一次看到最后记录的时间戳。这将更像是一种惰性更新方法,在某些情况下可能会比心跳更有利于我们。
通知
在聊天或群组中发送消息后,我们将首先检查收件人是否处于活动状态,我们可以通过考虑用户的活动连接和上次看到来获取此信息。
如果收件人未处于活动状态,聊天服务会将事件添加到消息队列中,其中包含其他元数据,例如客户端的设备平台,稍后将用于将通知路由到正确的平台。
然后,通知服务将使用消息队列中的事件,并根据客户端的设备平台(Android、iOS、Web 等)将请求转发到 Firebase Cloud Messaging (FCM) 或 Apple Push Notification Service (APNS)。我们还可以添加对电子邮件和短信的支持。
我们为什么要使用消息队列?
由于大多数消息队列都提供尽力而为的排序,这确保了消息通常以与发送相同的顺序传递,并且消息至少传递一次,这是我们服务功能的重要组成部分。
虽然这似乎是一个经典的发布-订阅用例,但实际上并非如此,因为移动设备和浏览器都有自己的推送通知处理方式。通常,通知是通过 Firebase Cloud Messaging (FCM) 或 Apple Push Notification Service (APNS) 在外部处理的,这与我们在后端服务中常见的消息扇出不同。我们可以使用 Amazon SQS 或 RabbitMQ 之类的东西来支持此功能。
已读回执
处理已读回执可能很棘手,对于此用例,我们可以等待来自客户端的某种确认 (ACK) 来确定消息是否已传递并更新相应的字段。同样,一旦用户打开聊天并更新相应的时间戳字段,我们就会将消息标记为已看到。
deliveredAt
seenAt
设计
现在我们已经确定了一些核心组件,让我们来做系统设计的初稿。
详细设计
是时候详细讨论我们的设计决策了。
数据分区
为了扩展我们的数据库,我们需要对数据进行分区。水平分区(又名分片)可能是一个很好的第一步。我们可以使用分区方案,例如:
- 基于哈希的分区
- 基于列表的分区
- 基于范围的分区
- 复合分区
上述方法仍然会导致数据和负载分布不均匀,我们可以使用一致哈希来解决此问题。
缓存
在消息传递应用程序中,我们必须小心使用缓存,因为我们的用户期望获得最新数据,但许多用户会请求相同的消息,尤其是在群聊中。因此,为了防止资源的使用高峰,我们可以缓存较旧的消息。
一些群聊可能有数千条消息,通过网络发送这些消息的效率非常低,为了提高效率,我们可以在系统 API 中添加分页。此决定将对网络带宽有限的用户有所帮助,因为除非请求,否则他们不必检索旧邮件。
要使用哪种缓存逐出策略?
我们可以使用 Redis 或 Memcached 等解决方案并缓存 20% 的每日流量,但哪种缓存逐出策略最适合我们的需求?
最近最少使用 (LRU) 对于我们的系统来说可能是一个很好的策略。在此策略中,我们首先丢弃最近使用最少的密钥。
如何处理缓存未命中?
每当缓存未命中时,我们的服务器都可以直接访问数据库并使用新条目更新缓存。
有关更多详细信息,请参阅缓存。
媒体访问和存储
众所周知,我们的大部分存储空间将用于存储媒体文件,例如图像、视频或其他文件。我们的媒体服务将处理用户媒体文件的访问和存储。
但是,我们可以在哪里大规模存储文件呢?好吧,对象存储就是我们正在寻找的。对象存储将数据文件分解为称为对象的部分。然后,它将这些对象存储在单个存储库中,该存储库可以分布在多个网络系统中。我们还可以使用分布式文件存储,例如 HDFS 或 GlusterFS。
有趣的事实:WhatsApp 会在用户下载媒体后删除其服务器上的媒体。
对于此用例,我们可以使用 Amazon S3、Azure Blob Storage 或 Google Cloud Storage 等对象存储。
内容分发网络 (CDN)
内容分发网络 (CDN) 提高了内容可用性和冗余度,同时降低了带宽成本。通常,静态文件(如图像和视频)由 CDN 提供。对于此用例,我们可以使用 Amazon CloudFront 或 Cloudflare CDN 等服务。
API 网关
由于我们将使用 HTTP、WebSocket、TCP/IP 等多种协议,因此为每个协议单独部署多个 L4(传输层)或 L7(应用层)类型的负载均衡器将非常昂贵。相反,我们可以使用支持多种协议的 API 网关,而不会出现任何问题。
API Gateway 还可以提供其他功能,例如身份验证、授权、速率限制、限制和 API 版本控制,这将提高我们的服务质量。
对于此用例,我们可以使用 Amazon API Gateway 或 Azure API Gateway 等服务。
识别并解决瓶颈
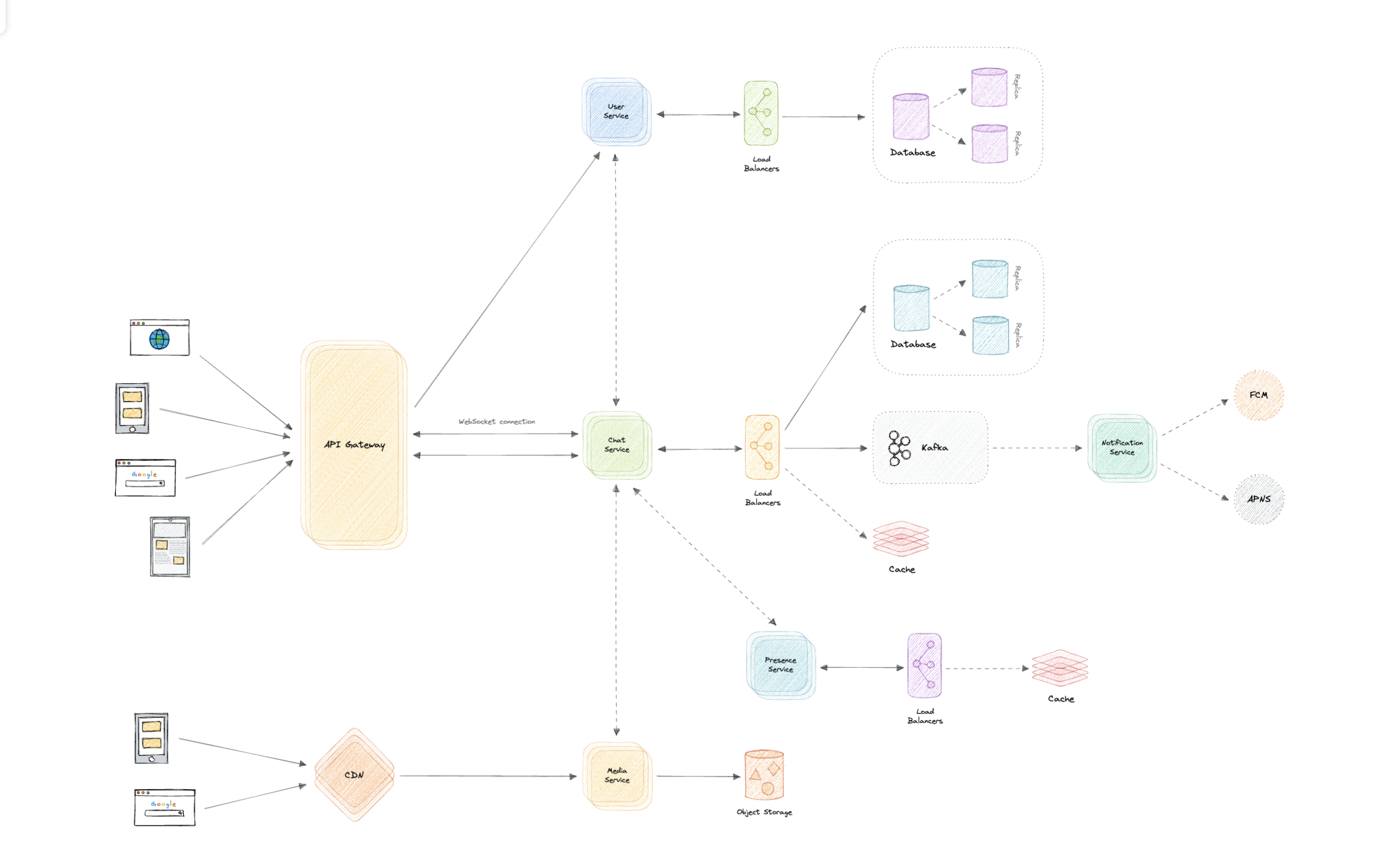
让我们识别并解决设计中的瓶颈,例如单点故障:
- “如果我们的某项服务崩溃了怎么办?”
- “我们将如何在组件之间分配流量?”
- “我们如何减少数据库的负载?”
- “如何提高缓存的可用性?”
- “API 网关不会是单点故障吗?”
- “我们怎样才能使我们的通知系统更加强大?”
- “我们如何降低媒体存储成本”?
- “聊天服务的责任太大了吗?”
为了使我们的系统更具弹性,我们可以执行以下操作:
- 运行我们每个服务的多个实例。
- 在客户端、服务器、数据库和缓存服务器之间引入负载平衡器。
- 对数据库使用多个只读副本。
- 分布式缓存的多个实例和副本。
- 我们可以拥有 API 网关的备用副本。
- 一旦在分布式系统中传递和消息排序具有挑战性,我们可以使用专用的消息代理(如 Apache Kafka 或 NATS)来使我们的通知系统更加健壮。
- 我们可以在媒体服务中添加媒体处理和压缩功能,以压缩类似于WhatsApp的大文件,这将节省大量存储空间并降低成本。
- 我们可以创建一个独立于聊天服务的群组服务,以进一步解耦我们的服务。
唽
让我们设计一个类似 Twitter 的社交媒体服务,类似于 Facebook、Instagram 等服务。
什么是推特?
Twitter 是一种社交媒体服务,用户可以在其中阅读或发布称为推文的短消息(最多 280 个字符)。它可以在 Android 和 iOS 等网络和移动平台上使用。
要求
我们的系统应满足以下要求:
功能要求
- 应该能够发布新的推文(可以是文本、图像、视频等)。
- 应该能够关注其他用户。
- 应该有一个新闻源功能,由用户关注的人的推文组成。
- 应该能够搜索推文。
非功能性需求
- 高可用性和最小延迟。
- 该系统应具有可扩展性和效率。
扩展要求
- 指标和分析。
- 转发功能。
- 最喜欢的推文。
估计和约束
让我们从估计和约束开始。
注意:请务必与面试官核实任何与规模或交通相关的假设。
交通
这将是一个阅读量很大的系统,假设我们有 10 亿用户和 2 亿日活跃用户 (DAU),平均每个用户每天发 5 次推文。这为我们提供了每天 10 亿条推文。
$$ 200 \space million \times 5 \space tweets = 1 \space billion/天 $$
推文还可以包含图像或视频等媒体。我们可以假设 10% 的推文是用户共享的媒体文件,这为我们提供了额外的 1 亿个文件,我们需要存储。
$$ 10 \space % \times 1 \space billion = 100 \space million/天 $$
我们系统的每秒请求数 (RPS) 是多少?
每天 10 亿个请求转化为每秒 12K 个请求。
$$ \frac{1 \space billion}{(24 \space hrs \times 3600 \space seconds)} = \sim 12K \space requests/second $$
存储
如果我们假设每条消息平均为 100 字节,则每天将需要大约 100 GB 的数据库存储。
$$ 1 \space billion \times 100 \space bytes = \sim 100 \space GB/天 $$
我们还知道,根据我们的要求,我们每天大约 10% 的消息(1 亿条)是媒体文件。如果我们假设每个文件平均为 50 KB,则每天需要 5 TB 的存储空间。
$$ 100 \space 百万 \times 50 \space KB = 5 \space TB/天 $$
在 10 年内,我们将需要大约 19 PB 的存储空间。
$$ (5 \space TB + 0.1 \space TB) \times 365 \space days \times 10 \space years = \sim 19 \space PB $$
带宽
由于我们的系统每天处理 5.1 TB 的入口,因此我们需要至少每秒 60 MB 左右的带宽。
$$ \frac{5.1 \space TB}{(24 \space hrs \times 3600 \space seconds)} = \sim 60 \space MB/秒 $$
高级估计
以下是我们的高层次估计:
| 类型 | 估计 |
|---|---|
| 每日活跃用户 (DAU) | 100万 |
| 每秒请求数 (RPS) | 12K/秒 |
| 存储(每天) | ~5.1 结核病 |
| 存储(10 年) | ~19 PB |
| 带宽 | ~60 MB/秒 |
数据模型设计
这是反映我们要求的通用数据模型。
我们有以下表格:
用户
此表将包含用户的信息,例如 、 、 和其他详细信息。
name
dob
鸣叫
顾名思义,此表将存储推文及其属性,例如(文本、图像、视频等)、等。我们还将存储相应的 .
type
content
userID
收藏 夹
此表将推文与用户映射在一起,以获取我们应用程序中的收藏夹推文功能。
追随 者
此表映射关注者和被关注者,因为用户可以相互关注(N:M 关系)。
饲料
此表使用相应的 .
userID
feeds_tweets
此表映射推文和提要(N:M 关系)。
我们应该使用什么样的数据库?
虽然我们的数据模型看起来很有关系,但我们不一定需要将所有内容存储在单个数据库中,因为这会限制我们的可扩展性并迅速成为瓶颈。
我们将在不同的服务之间拆分数据,每个服务都对特定表拥有所有权。然后,我们可以在用例中使用关系数据库(如 PostgreSQL)或分布式 NoSQL 数据库(如 Apache Cassandra)。
API 设计
让我们为我们的服务做一个基本的 API 设计:
发布推文
此 API 将允许用户在平台上发布推文。
postTweet(userID: UUID, content: string, mediaURL?: string): boolean参数
用户ID():用户的ID。
UUID
内容 ():推文的内容。
string
媒体 URL ():附加媒体的 URL(可选)。
string
返回
结果 ():表示操作是否成功。
boolean
关注或取消关注用户
此 API 将允许用户关注或取消关注其他用户。
follow(followerID: UUID, followeeID: UUID): boolean
unfollow(followerID: UUID, followeeID: UUID): boolean参数
Follower ID():当前用户的ID。
UUID
Followee ID():我们要关注或取消关注的用户的ID。
UUID
媒体 URL ():附加媒体的 URL(可选)。
string
返回
结果 ():表示操作是否成功。
boolean
获取新闻源
此 API 将返回要在给定新闻源中显示的所有推文。
getNewsfeed(userID: UUID): Tweet[]参数
用户ID():用户的ID。
UUID
返回
推文 ():要在给定新闻源中显示的所有推文。
Tweet[]
高级设计
现在让我们对系统进行高级设计。
建筑
我们将使用微服务架构,因为它可以更轻松地横向扩展和解耦我们的服务。每个服务都拥有自己的数据模型的所有权。让我们试着将我们的系统划分为一些核心服务。
用户服务
此服务处理与用户相关的问题,例如身份验证和用户信息。
新闻源服务
此服务将处理用户新闻源的生成和发布。具体讨论将单独讨论。
推文服务
推文服务将处理与推文相关的用例,例如发布推文、收藏夹等。
搜索服务
该服务负责处理与搜索相关的功能。具体讨论将单独讨论。
媒体服务
此服务将处理媒体(图像、视频、文件等)上传。具体讨论将单独讨论。
通知服务
此服务将简单地向用户发送推送通知。
分析服务
此服务将用于指标和分析用例。
服务间通信和服务发现呢?
由于我们的架构是基于微服务的,因此服务也将相互通信。一般来说,REST或HTTP表现良好,但我们可以使用gRPC进一步提高性能,因为gRPC更轻量级、更高效。
服务发现是我们必须考虑的另一件事。我们还可以使用服务网格,在各个服务之间实现可管理、 Observable 和安全的通信。
注意:详细了解 REST、GraphQL、gRPC 以及它们之间的比较。
新闻源
说到新闻源,它似乎很容易实现,但有很多事情可以成就或破坏这个功能。因此,让我们将问题分为两部分:
代
假设我们要为用户 A 生成 Feed,我们将执行以下步骤:
- 检索用户 A 以下所有用户和实体(主题标签、主题等)的 ID。
- 获取每个检索到的 ID 的相关推文。
- 使用排名算法根据相关性、时间、参与度等参数对推文进行排名。
- 以分页方式将排名后的推文数据返回给客户端。
Feed 生成是一个密集的过程,可能需要相当长的时间,尤其是对于关注很多人的用户而言。为了提高性能,可以预先生成提要并将其存储在缓存中,然后我们可以有一种机制来定期更新提要并将我们的排名算法应用于新的推文。
出版
发布是根据每个特定用户推送源数据的步骤。这可能是一项相当繁重的操作,因为用户可能拥有数百万个朋友或关注者。为了解决这个问题,我们有三种不同的方法:
- 拉动模型(或负载时扇出)
当用户创建推文,并且关注者重新加载其新闻源时,将创建该源并将其存储在内存中。仅当用户请求时,才会加载最新的 Feed。这种方法减少了对数据库的写入操作次数。
这种方法的缺点是,除非用户从服务器“拉取”数据,否则他们将无法查看最近的源,这将增加服务器上的读取操作数。
- 推送模型(或写入时扇出)
在这种模型中,一旦用户创建了一条推文,它就会立即被“推送”到所有关注者的提要中。这样可以防止系统必须浏览用户的整个关注者列表来检查更新。
但是,这种方法的缺点是它会增加数据库上的写入操作数。
- 混合模型
第三种方法是拉动和推取模型之间的混合模型。它结合了上述两种模型的有益特征,并想在两者之间提供一种平衡的方法。
混合模型仅允许关注者数量较少的用户使用推送模型。对于粉丝数量较多的用户,如名人,采用拉取模式。
排名算法
正如我们所讨论的,我们需要一种排名算法,根据每条推文与每个特定用户的相关性对每条推文进行排名。
例如,Facebook 曾经使用 EdgeRank 算法。在这里,每个 Feed 项的排名描述如下:
$$ 秩 = 亲和力 \ 权重 \ 衰减 $$
哪里
Affinity:是用户与边缘创建者的“亲密程度”。如果用户经常喜欢、评论或向边缘创建者发送消息,那么亲和力的值会更高,从而导致帖子的排名更高。
Weight:是根据每条边分配的值。评论的权重可能高于点赞,因此评论较多的帖子更有可能获得更高的排名。
Decay:是创建边的度量。边缘越老,衰减值和最终的等级就越小。
如今,算法要复杂得多,排名是使用机器学习模型完成的,该模型可以考虑数千个因素。
转推
转推是我们的扩展要求之一。要实现这个功能,我们只需使用转发原始推文的用户的用户 ID 创建一个新推文,然后修改新推文的枚举和属性以将其与原始推文链接。
type
content
例如,枚举属性可以是 tweet 类型,类似于 text、video 等,并且可以是原始推文的 id。在这里,第一行表示原始推文,而第二行表示转推的方式。
type
content
| 编号 | 用户 ID | 类型 | 内容 | createdAt |
|---|---|---|---|---|
| ad34-291a-45f6-b36c | 型号:7a2c-62c4-4dc8-b1bb | 发短信 | 嘿,这是我的第一条推文...... | 1658905644054 |
| 货号:f064-49ad-9aa2-84a6 | 6aa2-2bc9-4331-879f | 鸣叫 | ad34-291a-45f6-b36c | 1658906165427 |
这是一个非常基本的实现。为了改善这一点,我们可以创建一个单独的表本身来存储转发。
搜索
有时传统的DBMS性能不够,我们需要一些东西,使我们能够快速、近乎实时地存储、搜索和分析大量数据,并在几毫秒内给出结果。Elasticsearch 可以帮助我们完成这个用例。
Elasticsearch 是一个分布式、免费和开放的搜索和分析引擎,适用于所有类型的数据,包括文本、数字、地理空间、结构化和非结构化。它建立在 Apache Lucene 之上。
我们如何识别热门话题?
趋势功能将基于搜索功能。我们可以在最后几秒缓存最常搜索的查询、主题标签和主题,并使用某种批处理作业机制每秒更新一次。我们的排名算法也可以应用于热门话题,赋予它们更多的权重,并为用户个性化。
N
M
通知
推送通知是任何社交媒体平台不可或缺的一部分。我们可以将消息队列或消息代理(例如 Apache Kafka)与通知服务一起使用,将请求分派给 Firebase Cloud Messaging (FCM) 或 Apple Push Notification Service (APNS),后者将处理将推送通知传递到用户设备。
有关更多详细信息,请参阅 WhatsApp 系统设计,其中我们详细讨论了推送通知。
详细设计
是时候详细讨论我们的设计决策了。
数据分区
为了扩展我们的数据库,我们需要对数据进行分区。水平分区(又名分片)可能是一个很好的第一步。我们可以使用分区方案,例如:
- 基于哈希的分区
- 基于列表的分区
- 基于范围的分区
- 复合分区
上述方法仍然会导致数据和负载分布不均匀,我们可以使用一致哈希来解决此问题。
共同的朋友
对于共同的朋友,我们可以为每个用户建立一个社交图谱。图中的每个节点将代表一个用户,方向边缘将代表关注者和被关注者。之后,我们可以遍历用户的关注者来查找和推荐共同的朋友。这将需要一个图形数据库,例如 Neo4j 和 ArangoDB。
这是一个非常简单的算法,为了提高我们的建议准确性,我们需要结合一个使用机器学习作为算法一部分的推荐模型。
指标和分析
记录分析和指标是我们的扩展要求之一。由于我们将使用 Apache Kafka 发布各种事件,因此我们可以处理这些事件并使用 Apache Spark 对数据运行分析,Apache Spark 是一个用于大规模数据处理的开源统一分析引擎。
缓存
在社交媒体应用程序中,我们必须小心使用缓存,因为我们的用户期望获得最新数据。因此,为了防止资源的使用高峰,我们可以缓存前 20% 的推文。
为了进一步提高效率,我们可以在系统 API 中添加分页功能。此决定将对网络带宽有限的用户有所帮助,因为除非请求,否则他们不必检索旧邮件。
要使用哪种缓存逐出策略?
我们可以使用 Redis 或 Memcached 等解决方案并缓存 20% 的每日流量,但哪种缓存逐出策略最适合我们的需求?
最近最少使用 (LRU) 对于我们的系统来说可能是一个很好的策略。在此策略中,我们首先丢弃最近使用最少的密钥。
如何处理缓存未命中?
每当缓存未命中时,我们的服务器都可以直接访问数据库并使用新条目更新缓存。
有关更多详细信息,请参阅缓存。
媒体访问和存储
众所周知,我们的大部分存储空间将用于存储媒体文件,例如图像、视频或其他文件。我们的媒体服务将处理用户媒体文件的访问和存储。
但是,我们可以在哪里大规模存储文件呢?好吧,对象存储就是我们正在寻找的。对象存储将数据文件分解为称为对象的部分。然后,它将这些对象存储在单个存储库中,该存储库可以分布在多个网络系统中。我们还可以使用分布式文件存储,例如 HDFS 或 GlusterFS。
内容分发网络 (CDN)
内容分发网络 (CDN) 提高了内容可用性和冗余度,同时降低了带宽成本。通常,静态文件(如图像和视频)由 CDN 提供。对于此用例,我们可以使用 Amazon CloudFront 或 Cloudflare CDN 等服务。
识别并解决瓶颈
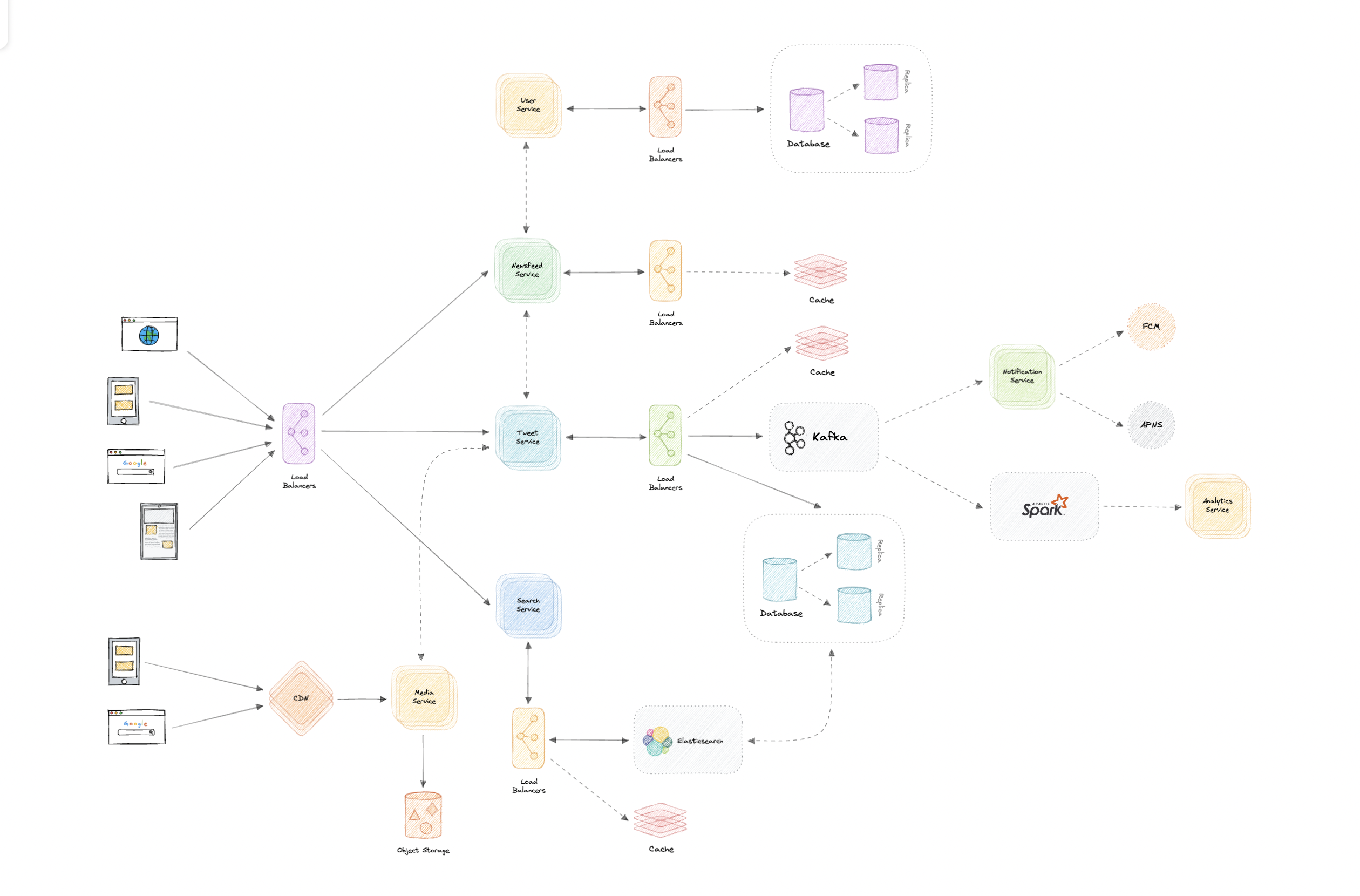
让我们识别并解决设计中的瓶颈,例如单点故障:
- “如果我们的某项服务崩溃了怎么办?”
- “我们将如何在组件之间分配流量?”
- “我们如何减少数据库的负载?”
- “如何提高缓存的可用性?”
- “我们怎样才能使我们的通知系统更加强大?”
- “我们如何降低媒体存储成本”?
为了使我们的系统更具弹性,我们可以执行以下操作:
- 运行我们每个服务的多个实例。
- 在客户端、服务器、数据库和缓存服务器之间引入负载平衡器。
- 对数据库使用多个只读副本。
- 分布式缓存的多个实例和副本。
- 一旦在分布式系统中传递和消息排序具有挑战性,我们可以使用专用的消息代理(如 Apache Kafka 或 NATS)来使我们的通知系统更加健壮。
- 我们可以在媒体服务中添加媒体处理和压缩功能来压缩大文件,这将节省大量存储空间并降低成本。
Netflix公司
让我们设计一个类似Netflix的视频流媒体服务,类似于Amazon Prime Video、Disney Plus、Hulu、Youtube、Vimeo等服务。
什么是Netflix?
Netflix 是一项基于订阅的流媒体服务,允许其会员在连接互联网的设备上观看电视节目和电影。它可以在 Web、iOS、Android、TV 等平台上使用。
要求
我们的系统应满足以下要求:
功能要求
- 用户应该能够流式传输和共享视频。
- 内容团队(或 YouTube 中的用户)应该能够上传新视频(电影、电视节目、剧集和其他内容)。
- 用户应该能够使用标题或标签搜索视频。
- 用户应该能够对类似于 YouTube 的视频发表评论。
非功能性需求
- 高可用性和最小延迟。
- 可靠性高,不会丢失任何上传。
- 该系统应具有可扩展性和效率。
扩展要求
- 某些内容应进行地理封锁。
- 从用户离开的位置恢复视频播放。
- 记录视频的指标和分析。
估计和约束
让我们从估计和约束开始。
注意:请务必与面试官核实任何与规模或交通相关的假设。
交通
这将是一个阅读量很大的系统,假设我们有 10 亿用户和 2 亿日活跃用户 (DAU),平均每个用户每天观看 5 个视频。这使我们每天观看了 10 亿个视频。
$$ 200 \space million \times 5 \space videos = 1 \space billion/天 $$
假设读/写比率,每天将上传大约 500 万个视频。
200:1
$$ \frac{1}{200} \times 1 \space billion = 5 \space million/天 $$
我们系统的每秒请求数 (RPS) 是多少?
每天 10 亿个请求转化为每秒 12K 个请求。
$$ \frac{1 \space billion}{(24 \space hrs \times 3600 \space seconds)} = \sim 12K \space requests/second $$
存储
如果我们假设每个视频平均为 100 MB,那么我们每天将需要大约 500 TB 的存储空间。
$$ 5 \space million \times 100 \space MB = 500 \space TB/天 $$
在 10 年内,我们将需要惊人的 1,825 PB 存储。
$$ 500 \space TB \times 365 \space days \times 10 \space years = \sim 1,825 \space PB $$
带宽
由于我们的系统每天处理 500 TB 的入口,因此我们需要至少每秒约 5.8 GB 的带宽。
$$ \frac{500 \space TB}{(24 \space hrs \times 3600 \space seconds)} = \sim 5.8 \space GB/秒 $$
高级估计
以下是我们的高层次估计:
| 类型 | 估计 |
|---|---|
| 每日活跃用户 (DAU) | 200万 |
| 每秒请求数 (RPS) | 12K/秒 |
| 存储(每天) | ~500 结核病 |
| 存储(10 年) | ~1,825 PB |
| 带宽 | ~5.8 千兆字节/s |
数据模型设计
这是反映我们要求的通用数据模型。
我们有以下表格:
用户
此表将包含用户的信息,例如 、 、 和其他详细信息。
name
dob
视频
顾名思义,此表将存储视频及其属性,例如 、 、 等。我们还将存储相应的 .
title
streamURL
tags
userID
标签
此表将仅存储与视频关联的标记。
视图
此表帮助我们存储视频中收到的所有观看次数。
评论
此表存储了在视频(如 YouTube)上收到的所有评论。
我们应该使用什么样的数据库?
虽然我们的数据模型看起来很有关系,但我们不一定需要将所有内容存储在单个数据库中,因为这会限制我们的可扩展性并迅速成为瓶颈。
我们将在不同的服务之间拆分数据,每个服务都对特定表拥有所有权。然后,我们可以在用例中使用关系数据库(如 PostgreSQL)或分布式 NoSQL 数据库(如 Apache Cassandra)。
API 设计
让我们为我们的服务做一个基本的 API 设计:
上传视频
给定一个字节流,此 API 允许将视频上传到我们的服务。
uploadVideo(title: string, description: string, data: Stream<byte>, tags?: string[]): boolean参数
标题 ():新视频的标题。
string
描述 ():新视频的说明。
string
数据():视频数据的字节流。
Byte[]
Tags ():视频的标签(可选)。
string[]
返回
结果 ():表示操作是否成功。
boolean
流式传输视频
此 API 允许我们的用户使用首选编解码器和分辨率流式传输视频。
streamVideo(videoID: UUID, codec: Enum<string>, resolution: Tuple<int>, offset?: int): VideoStream参数
视频ID():需要推流的视频ID。
UUID
编解码器():请求视频所需的编解码器,如、、等。
Enum<string>
h.265
h.264
VP9
分辨率 ():请求视频的分辨率。
Tuple<int>
偏移量 ():视频流的偏移量(以秒为单位),用于从视频中的任意点流式传输数据(可选)。
int
返回
Stream():请求视频的数据流。
VideoStream
搜索视频
此 API 将使我们的用户能够根据视频的标题或标签搜索视频。
searchVideo(query: string, nextPage?: string): Video[]参数
查询 ():来自用户的搜索查询。
string
下一页():下一页的令牌,可用于分页(可选)。
string
返回
视频 ():可用于特定搜索查询的所有视频。
Video[]
添加评论
此 API 将允许我们的用户在视频(如 YouTube)上发表评论。
comment(videoID: UUID, comment: string): boolean参数
VideoID ():用户要评论的视频的 ID。
UUID
注释():注释的文本内容。
string
返回
结果 ():表示操作是否成功。
boolean
高级设计
现在让我们对系统进行高级设计。
建筑
我们将使用微服务架构,因为它可以更轻松地横向扩展和解耦我们的服务。每个服务都拥有自己的数据模型的所有权。让我们试着将我们的系统划分为一些核心服务。
用户服务
此服务处理与用户相关的问题,例如身份验证和用户信息。
流服务
流服务将处理与视频流相关的功能。
搜索服务
该服务负责处理与搜索相关的功能。具体讨论将单独讨论。
媒体服务
此服务将处理视频上传和处理。具体讨论将单独讨论。
分析服务
此服务将用于指标和分析用例。
服务间通信和服务发现呢?
由于我们的架构是基于微服务的,因此服务也将相互通信。一般来说,REST或HTTP表现良好,但我们可以使用gRPC进一步提高性能,因为gRPC更轻量级、更高效。
服务发现是我们必须考虑的另一件事。我们还可以使用服务网格,在各个服务之间实现可管理、 Observable 和安全的通信。
注意:详细了解 REST、GraphQL、gRPC 以及它们之间的比较。
视频处理
在处理视频时,有很多变量在起作用。例如,来自高端摄像机的两小时原始 8K 素材的平均数据大小很容易达到 4 TB,因此我们需要进行某种处理来降低存储和交付成本。
以下是我们如何处理视频,一旦视频被内容团队(或 YouTube 的用户)上传并在我们的消息队列中排队等待处理。
让我们讨论一下它是如何工作的:
- 文件分块器
这是我们处理流程的第一步。文件分块是将文件拆分为称为块的较小部分的过程。它可以帮助我们消除存储上重复数据的重复副本,并通过仅选择更改的块来减少通过网络发送的数据量。
通常,视频文件可以根据时间戳拆分成大小相等的块,但 Netflix 会根据场景拆分块。这种细微的变化成为获得更好用户体验的一个重要因素,因为每当客户端从服务器请求一个块时,中断的可能性就会降低,因为会检索到完整的场景。
- 内容过滤器
此步骤会检查视频是否符合平台的内容政策。这可以像 Netflix 一样根据媒体的内容评级进行预先批准,也可以像 YouTube 一样严格执行。
整个过程由机器学习模型完成,该模型执行版权、盗版和 NSFW 检查。如果发现问题,我们可以将任务推送到死信队列 (DLQ),审核团队中的人员可以进行进一步检查。
- 转码器
转码是将原始数据解码为中间未压缩格式,然后编码为目标格式的过程。此过程使用不同的编解码器来执行比特率调整、图像缩减采样或对媒体重新编码。
这导致文件更小,目标设备的格式更优化。FFmpeg 等独立解决方案或 AWS Elemental MediaConvert 等基于云的解决方案可用于实施管道的此步骤。
- 质量转换
这是处理管道的最后一步,顾名思义,此步骤处理将上一步中的转码媒体转换为不同的分辨率,例如 4K、1440p、1080p、720p 等。
它允许我们根据用户的请求获取所需质量的视频,一旦媒体文件完成处理,它就会上传到分布式文件存储(如 HDFS、GlusterFS)或对象存储(如 Amazon S3),以便以后在流式传输期间检索。
注意:我们可以添加其他步骤,例如字幕和缩略图生成,作为我们管道的一部分。
我们为什么要使用消息队列?
将视频作为长时间运行的任务进行处理并使用消息队列更有意义。它还将我们的视频处理管道与上传功能分离。我们可以使用 Amazon SQS 或 RabbitMQ 之类的东西来支持这一点。
视频流
从客户端和服务器的角度来看,视频流都是一项具有挑战性的任务。此外,不同用户之间的互联网连接速度差异很大。为确保用户不会重新获取相同的内容,我们可以使用内容分发网络 (CDN)。
Netflix 通过其 Open Connect 计划更进一步。在这种方法中,他们与数以千计的互联网服务提供商 (ISP) 合作,以本地化他们的流量并更有效地交付他们的内容。
Netflix 的 Open Connect 和传统的内容分发网络 (CDN) 有什么区别?
Netflix Open Connect 是一个专门构建的内容分发网络 (CDN),负责为 Netflix 的视频流量提供服务。全球大约 95% 的流量是通过 Open Connect 与客户用于访问互联网的 ISP 之间的直接连接提供的。
目前,他们在全球 1000 多个不同地点拥有 Open Connect 设备 (OCA)。如果出现问题,Open Connect 设备 (OCA) 可以进行故障转移,并且可以将流量重新路由到 Netflix 服务器。
此外,我们可以使用自适应比特率流协议,例如 HTTP Live Streaming (HLS),它专为可靠性而设计,它通过优化可用连接速度的播放来动态适应网络条件。
最后,为了从用户离开的地方播放视频(我们扩展要求的一部分),我们可以简单地使用存储在表中的属性来检索该特定时间戳的场景块,并为用户恢复播放。
offset
views
搜索
有时传统的DBMS性能不够,我们需要一些东西,使我们能够快速、近乎实时地存储、搜索和分析大量数据,并在几毫秒内给出结果。Elasticsearch 可以帮助我们完成这个用例。
Elasticsearch 是一个分布式、免费和开放的搜索和分析引擎,适用于所有类型的数据,包括文本、数字、地理空间、结构化和非结构化。它建立在 Apache Lucene 之上。
我们如何识别热门内容?
趋势功能将基于搜索功能。我们可以在最后几秒缓存最常搜索的查询,并使用某种批处理作业机制每秒更新一次。
N
M
共享
共享内容是任何平台的重要组成部分,为此,我们可以提供某种 URL 缩短器服务,可以生成短 URL 供用户共享。
有关详细信息,请参阅 URL Shortener 系统设计。
详细设计
是时候详细讨论我们的设计决策了。
数据分区
为了扩展我们的数据库,我们需要对数据进行分区。水平分区(又名分片)可能是一个很好的第一步。我们可以使用分区方案,例如:
- 基于哈希的分区
- 基于列表的分区
- 基于范围的分区
- 复合分区
上述方法仍然会导致数据和负载分布不均匀,我们可以使用一致哈希来解决此问题。
地理封锁
Netflix 和 YouTube 等平台使用地理封锁来限制某些地理区域或国家/地区的内容。这主要是由于 Netflix 在与制作和发行公司达成协议时必须遵守的法律发行法。对于 YouTube,这将由用户在发布内容期间控制。
我们可以使用用户配置文件中的 IP 或区域设置来确定用户的位置,然后使用 Amazon CloudFront 等服务(支持地理限制功能或 Amazon Route53 的地理位置路由策略)来限制内容,并在内容在该特定区域或国家/地区不可用时将用户重新路由到错误页面。
建议
Netflix 使用机器学习模型,该模型使用用户的观看历史来预测用户接下来可能想看什么,可以使用协作过滤等算法。
但是,Netflix(如YouTube)使用自己的算法,称为Netflix推荐引擎,该算法可以跟踪多个数据点,例如:
- 用户个人资料信息,如年龄、性别和位置。
- 用户的浏览和滚动行为。
- 用户观看影片的时间和日期。
- 用于流式传输内容的设备。
- 搜索次数和搜索的术语。
有关更多详细信息,请参阅 Netflix 推荐研究。
指标和分析
记录分析和指标是我们的扩展要求之一。我们可以从不同的服务中捕获数据,并使用Apache Spark对数据进行分析,Apache Spark是一个用于大规模数据处理的开源统一分析引擎。此外,我们可以将关键元数据存储在视图表中,以增加数据中的数据点。
缓存
在流媒体平台中,缓存很重要。我们必须能够缓存尽可能多的静态媒体内容,以改善用户体验。我们可以使用 Redis 或 Memcached 等解决方案,但哪种缓存逐出策略最适合我们的需求?
要使用哪种缓存逐出策略?
最近最少使用 (LRU) 对于我们的系统来说可能是一个很好的策略。在此策略中,我们首先丢弃最近使用最少的密钥。
如何处理缓存未命中?
每当缓存未命中时,我们的服务器都可以直接访问数据库并使用新条目更新缓存。
有关更多详细信息,请参阅缓存。
媒体流和存储
由于我们的大部分存储空间将用于存储缩略图和视频等媒体文件。根据我们之前的讨论,媒体服务将处理媒体文件的上传和处理。
我们将使用分布式文件存储(如 HDFS、GlusterFS)或对象存储(如 Amazon S3)来存储和流式传输内容。
内容分发网络 (CDN)
内容分发网络 (CDN) 提高了内容可用性和冗余度,同时降低了带宽成本。通常,静态文件(如图像和视频)由 CDN 提供。对于此用例,我们可以使用 Amazon CloudFront 或 Cloudflare CDN 等服务。
识别并解决瓶颈
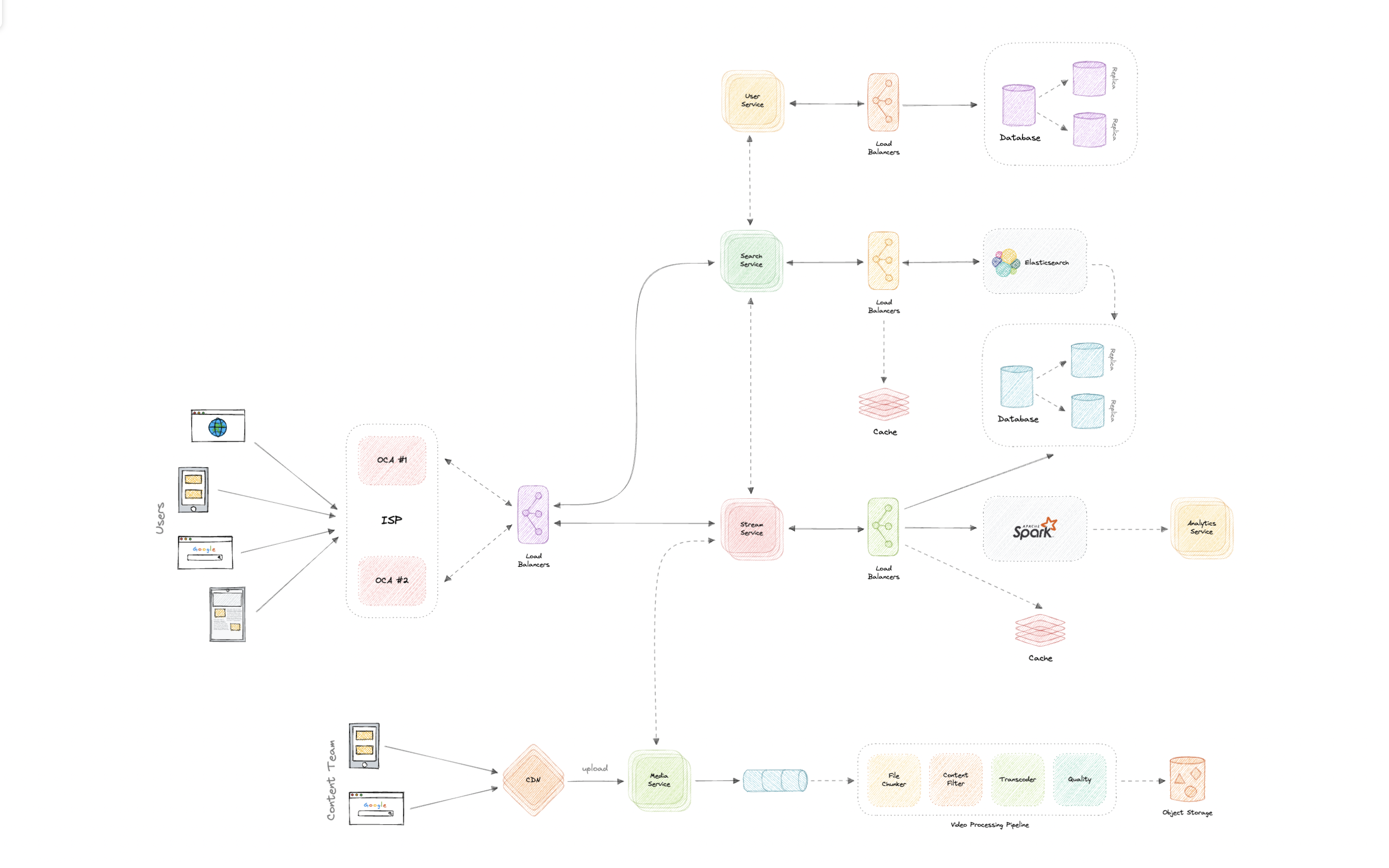
让我们识别并解决设计中的瓶颈,例如单点故障:
- “如果我们的某项服务崩溃了怎么办?”
- “我们将如何在组件之间分配流量?”
- “我们如何减少数据库的负载?”
- “如何提高缓存的可用性?”
为了使我们的系统更具弹性,我们可以执行以下操作:
- 运行我们每个服务的多个实例。
- 在客户端、服务器、数据库和缓存服务器之间引入负载平衡器。
- 对数据库使用多个只读副本。
- 分布式缓存的多个实例和副本。
优步
让我们设计一个类似 Uber 的叫车服务,类似于 Lyft、OLA Cabs 等服务。
什么是优步?
优步是一家移动服务提供商,允许用户预订乘车服务,并允许司机以类似于出租车的方式运送他们。它可以在 Android 和 iOS 等网络和移动平台上使用。
要求
我们的系统应满足以下要求:
功能要求
我们将为两类用户设计我们的系统:客户和司机。
客户
- 客户应该能够看到附近的所有出租车,以及预计到达时间和定价信息。
- 客户应该能够预订前往目的地的出租车。
- 客户应该能够看到驱动程序的位置。
司机
- 合作车主应该能够接受或拒绝客户请求的行程。
- 司机接受乘车后,他们应该会看到客户的上车地点。
- 司机应该能够在到达目的地时将行程标记为完成。
非功能性需求
- 可靠性高。
- 高可用性和最小延迟。
- 该系统应具有可扩展性和效率。
扩展要求
- 客户可以在行程完成后对行程进行评分。
- 付款处理。
- 指标和分析。
估计和约束
让我们从估计和约束开始。
注意:请务必与面试官核实任何与规模或交通相关的假设。
交通
假设我们有 1 亿日活跃用户 (DAU) 和 100 万名司机,我们的平台平均每天提供 1000 万次乘车服务。
如果平均每个用户执行 10 次操作(例如请求查看可用行程、票价、预订行程等),我们每天将不得不处理 10 亿个请求。
$$ 100 \space million \times 10 \space actions = 1 \space billion/天 $$
我们系统的每秒请求数 (RPS) 是多少?
每天 10 亿个请求转化为每秒 12K 个请求。
$$ \frac{1 \space billion}{(24 \space hrs \times 3600 \space seconds)} = \sim 12K \space requests/second $$
存储
如果我们假设每条消息平均为 400 字节,则每天将需要大约 400 GB 的数据库存储。
$$ 1 \space billion \times 400 \space 字节 = \sim 400 \space GB/天 $$
在 10 年内,我们将需要大约 1.4 PB 的存储空间。
$$ 400 \space GB \times 10 \space years \times 365 \space days = \sim 1.4 \space PB $$
带宽
由于我们的系统每天处理 400 GB 的入口,因此我们需要至少每秒约 4 MB 的带宽。
$$ \frac{400 \space GB}{(24 \space hrs \times 3600 \space seconds)} = \sim 5 \space MB/秒 $$
高级估计
以下是我们的高层次估计:
| 类型 | 估计 |
|---|---|
| 每日活跃用户 (DAU) | 100万 |
| 每秒请求数 (RPS) | 12K/秒 |
| 存储(每天) | ~400 千兆字节 |
| 存储(10 年) | ~1.4 PB |
| 带宽 | ~5 MB/秒 |
数据模型设计
这是反映我们要求的通用数据模型。

我们有以下表格:
客户
此表将包含客户的信息(如 、 和其他详细信息)。
name
司机
此表将包含驱动程序的信息(如 、 和其他详细信息)。
name
dob
旅行
此表表示客户所采取的行程,并存储行程的 、 和 等数据。
source
destination
status
出租车
此表存储数据,例如司机将驾驶的出租车的注册号和类型(如 Uber Go、Uber XL 等)。
评级
顾名思义,此表存储行程的 和。
rating
feedback
付款
付款表包含与付款相关的数据以及相应的 .
tripID
我们应该使用什么样的数据库?
虽然我们的数据模型看起来很有关系,但我们不一定需要将所有内容存储在单个数据库中,因为这会限制我们的可扩展性并迅速成为瓶颈。
我们将在不同的服务之间拆分数据,每个服务都对特定表拥有所有权。然后,我们可以在用例中使用关系数据库(如 PostgreSQL)或分布式 NoSQL 数据库(如 Apache Cassandra)。
API 设计
让我们为我们的服务做一个基本的 API 设计:
叫车
通过此 API,客户将能够叫车。
requestRide(customerID: UUID, source: Tuple<float>, destination: Tuple<float>, cabType: Enum<string>, paymentMethod: Enum<string>): Ride参数
客户 ID():客户的 ID。
UUID
Source ():包含行程起点的纬度和经度的元组。
Tuple<float>
目的地 ():包含行程目的地纬度和经度的元组。
Tuple<float>
返回
结果 ():行程的关联行程信息。
Ride
取消行程
此 API 将允许客户取消行程。
cancelRide(customerID: UUID, reason?: string): boolean参数
客户 ID():客户的 ID。
UUID
原因():取消行程的原因(可选)。
UUID
返回
结果 ():表示操作是否成功。
boolean
接受或拒绝行程
此 API 将允许司机接受或拒绝行程。
acceptRide(driverID: UUID, rideID: UUID): boolean
denyRide(driverID: UUID, rideID: UUID): boolean参数
Driver ID ():驱动程序的 ID。
UUID
乘车 ID ():客户请求乘车的 ID。
UUID
返回
结果 ():表示操作是否成功。
boolean
开始或结束行程
使用此 API,司机将能够开始和结束行程。
startTrip(driverID: UUID, tripID: UUID): boolean
endTrip(driverID: UUID, tripID: UUID): boolean参数
Driver ID ():驱动程序的 ID。
UUID
行程 ID ():请求行程的 ID。
UUID
返回
结果 ():表示操作是否成功。
boolean
评价行程
此 API 将使客户能够对行程进行评分。
rateTrip(customerID: UUID, tripID: UUID, rating: int, feedback?: string): boolean参数
客户 ID():客户的 ID。
UUID
行程 ID ():已完成行程的 ID。
UUID
评分 ():行程评分。
int
反馈 ():客户对行程的反馈(可选)。
string
返回
结果 ():表示操作是否成功。
boolean
高级设计
现在让我们对系统进行高级设计。
建筑
我们将使用微服务架构,因为它可以更轻松地横向扩展和解耦我们的服务。每个服务都拥有自己的数据模型的所有权。让我们试着将我们的系统划分为一些核心服务。
顾客服务
此服务处理与客户相关的问题,例如身份验证和客户信息。
司机服务
此服务处理与驱动程序相关的问题,例如身份验证和驱动程序信息。
乘车服务
此服务将负责行程匹配和四叉树聚合。具体讨论将单独讨论。
旅行服务
这项服务处理我们系统中与旅行相关的功能。
支付服务
这项服务将负责处理我们系统中的付款。
通知服务
此服务将简单地向用户发送推送通知。具体讨论将单独讨论。
分析服务
此服务将用于指标和分析用例。
服务间通信和服务发现呢?
由于我们的架构是基于微服务的,因此服务也将相互通信。一般来说,REST或HTTP表现良好,但我们可以使用gRPC进一步提高性能,因为gRPC更轻量级、更高效。
服务发现是我们必须考虑的另一件事。我们还可以使用服务网格,在各个服务之间实现可管理、 Observable 和安全的通信。
注意:详细了解 REST、GraphQL、gRPC 以及它们之间的比较。
该服务应如何工作?
以下是我们服务的预期工作方式:
- 客户通过指定来源、目的地、出租车类型、付款方式等来请求乘车。
- 乘车服务会记录此请求,查找附近的合作车主,并计算预计到达时间 (ETA)。
- 然后,该请求将广播给附近的司机,供他们接受或拒绝。
- 如果司机接受,客户在等待取车时会收到有关司机的实时位置以及预计到达时间 (ETA) 的通知。
- 客户被接走,司机可以开始旅行。
- 到达目的地后,司机会将乘车标记为完成并收取款项。
- 付款完成后,客户可以根据需要为旅行留下评分和反馈。
位置跟踪
我们如何有效地将实时位置数据从客户端(客户和司机)发送到我们的后端?我们有两种不同的选择:
拉取模型
客户端可以定期向服务器发送 HTTP 请求,以报告其当前位置并接收 ETA 和定价信息。这可以通过长轮询之类的方式来实现。
推送模型
客户端打开与服务器的长期连接,一旦有新数据可用,它就会被推送到客户端。为此,我们可以使用 WebSockets 或服务器发送事件 (SSE)。
拉模型方法不可扩展,因为它会在我们的服务器上产生不必要的请求开销,并且大多数时候响应将是空的,从而浪费了我们的资源。为了最大程度地减少延迟,将推送模型与 WebSockets 一起使用是更好的选择,因为这样我们就可以在数据可用时将数据推送到客户端,而不会有任何延迟,前提是与客户端的连接是开放的。此外,WebSockets 提供全双工通信,这与服务器发送事件 (SSE) 不同,后者只是单向的。
此外,客户端应用程序应具有某种后台作业机制,以便在应用程序处于后台时对 GPS 位置执行 ping 操作。
注意:详细了解长轮询、WebSockets、服务器发送事件 (SSE)。
乘车匹配
我们需要一种方法来有效地存储和查询附近的驱动程序。让我们探索一下可以纳入设计的不同解决方案。
SQL算法
我们已经可以访问客户的纬度和经度,并且使用 PostgreSQL 和 MySQL 等数据库,我们可以执行查询以查找附近的驱动程序位置,给定半径 (R) 内的纬度和经度 (X, Y)。
SELECT * FROM locations WHERE lat BETWEEN X-R AND X+R AND long BETWEEN Y-R AND Y+R但是,这是不可缩放的,并且在大型数据集上执行此查询将非常慢。
地理散列
地理哈希是一种地理编码方法,用于将地理坐标(如纬度和经度)编码为短字母数字字符串。它由 Gustavo Niemeyer 于 2008 年创建。
Geohash 是使用 Base-32 字母编码的分层空间索引,geohash 中的第一个字符将初始位置标识为 32 个单元格之一。该单元格还将包含 32 个单元格。这意味着,为了表示一个点,世界被递归地划分为越来越小的单元,每增加一个位,直到达到所需的精度。精度因子还决定了单元格的大小。
例如,具有坐标的旧金山可以在 geohash 中表示为 。
37.7564, -122.4016
9q8yy9mf
现在,使用客户的 geohash,我们可以通过简单地将其与驱动程序的 geohash 进行比较来确定最接近的可用驱动程序。为了获得更好的性能,我们将驱动程序的 geohash 编制索引并将其存储在内存中,以便更快地检索。
四叉树
四叉树是一种树数据结构,其中每个内部节点正好有四个子节点。它们通常用于通过将二维空间递归细分为四个象限或区域来划分二维空间。每个子节点或叶节点都存储空间信息。四叉树是八叉树的二维模拟,用于划分三维空间。
四叉树使我们能够有效地搜索二维范围内的点,其中这些点被定义为纬度/经度坐标或笛卡尔 (x, y) 坐标。
我们可以通过仅在某个阈值后细分节点来节省进一步的计算。
Quadtree 似乎非常适合我们的用例,每次从驱动程序收到新的位置更新时,我们都可以更新 Quadtree。为了减少四叉树服务器上的负载,我们可以使用内存数据存储(如 Redis)来缓存最新更新。通过应用希尔伯特曲线等映射算法,我们可以执行高效的范围查询,为客户找到附近的驱动程序。
What about race conditions?
Race conditions can easily occur when a large number of customers will be requesting rides simultaneously. To avoid this, we can wrap our ride matching logic in a Mutex to avoid any race conditions. Furthermore, every action should be transactional in nature.
For more details, refer to Transactions and Distributed Transactions.
How to find the best drivers nearby?
Once we have a list of nearby drivers from the Quadtree servers, we can perform some sort of ranking based on parameters like average ratings, relevance, past customer feedback, etc. This will allow us to broadcast notifications to the best available drivers first.
Dealing with high demand
In cases of high demand, we can use the concept of Surge Pricing. Surge pricing is a dynamic pricing method where prices are temporarily increased as a reaction to increased demand and mostly limited supply. This surge price can be added to the base price of the trip.
For more details, learn how surge pricing works with Uber.
Payments
Handling payments at scale is challenging, to simplify our system we can use a third-party payment processor like Stripe or PayPal. Once the payment is complete, the payment processor will redirect the user back to our application and we can set up a webhook to capture all the payment-related data.
Notifications
Push notifications will be an integral part of our platform. We can use a message queue or a message broker such as Apache Kafka with the notification service to dispatch requests to Firebase Cloud Messaging (FCM) or Apple Push Notification Service (APNS) which will handle the delivery of the push notifications to user devices.
For more details, refer to the WhatsApp system design where we discuss push notifications in detail.
Detailed design
It's time to discuss our design decisions in detail.
Data Partitioning
To scale out our databases we will need to partition our data. Horizontal partitioning (aka Sharding) can be a good first step. We can shard our database either based on existing partition schemes or regions. If we divide the locations into regions using let's say zip codes, we can effectively store all the data in a given region on a fixed node. But this can still cause uneven data and load distribution, we can solve this using Consistent hashing.
For more details, refer to Sharding and Consistent Hashing.
Metrics and Analytics
Recording analytics and metrics is one of our extended requirements. We can capture the data from different services and run analytics on the data using Apache Spark which is an open-source unified analytics engine for large-scale data processing. Additionally, we can store critical metadata in the views table to increase data points within our data.
Caching
In a location services-based platform, caching is important. We have to be able to cache the recent locations of the customers and drivers for fast retrieval. We can use solutions like Redis or Memcached but what kind of cache eviction policy would best fit our needs?
Which cache eviction policy to use?
Least Recently Used (LRU) can be a good policy for our system. In this policy, we discard the least recently used key first.
How to handle cache miss?
Whenever there is a cache miss, our servers can hit the database directly and update the cache with the new entries.
For more details, refer to Caching.
Identify and resolve bottlenecks
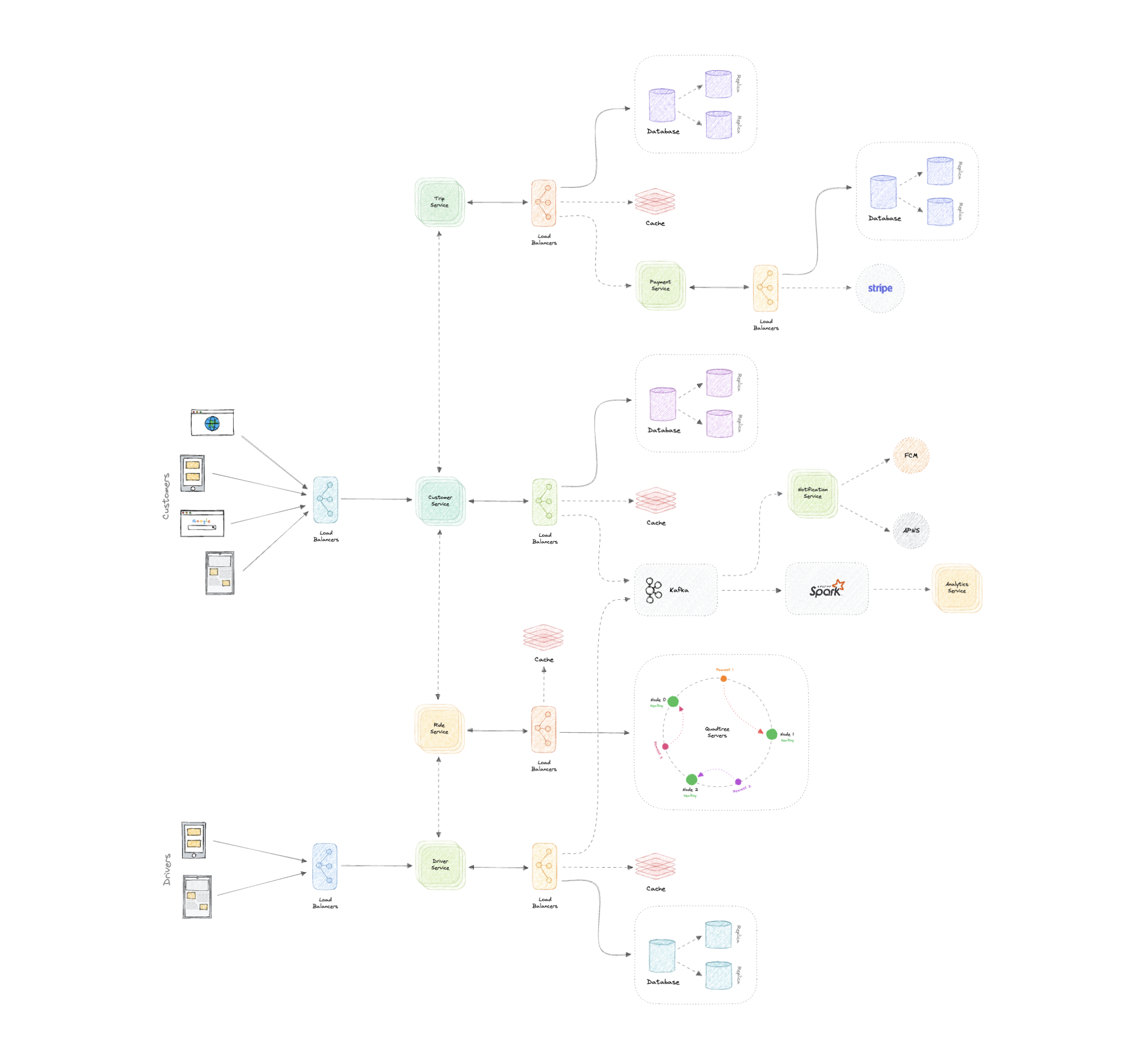
Let us identify and resolve bottlenecks such as single points of failure in our design:
- "What if one of our services crashes?"
- "How will we distribute our traffic between our components?"
- "How can we reduce the load on our database?"
- "How to improve the availability of our cache?"
- "How can we make our notification system more robust?"
To make our system more resilient we can do the following:
- Running multiple instances of each of our services.
- Introducing load balancers between clients, servers, databases, and cache servers.
- Using multiple read replicas for our databases.
- Multiple instances and replicas for our distributed cache.
- Exactly once delivery and message ordering is challenging in a distributed system, we can use a dedicated message broker such as Apache Kafka or NATS to make our notification system more robust.
Next Steps
Congratulations, you've finished the course!
Now that you know the fundamentals of System Design, here are some additional resources:
- Distributed Systems (by Dr. Martin Kleppmann)
- System Design Interview: An Insider's Guide
- 微服务(作者:Chris Richardson)
- 无服务器计算
- Kubernetes的
还建议积极关注公司的工程博客,将我们在课程中学到的知识大规模付诸实践:
- Microsoft 工程
- Google 研究博客
- Netflix 技术博客
- AWS 博客
- Facebook工程
- 优步工程博客
- Airbnb 工程
- GitHub 工程博客
- 英特尔软件博客
- LinkedIn 工程
- PayPal 开发者博客
- Twitter工程
最后但并非最不重要的一点是,自愿参加贵公司的新项目,并向高级工程师和架构师学习,以进一步提高你的系统设计技能。
我希望这门课程是一次很棒的学习经历。我很想听听你的反馈。
祝你进一步学习一切顺利!
引用
以下是创建本课程时引用的资源。
- Cloudflare 学习中心
- IBM 博客
- 快速博客
- NS1 博客
- 摸索系统设计面试
- Grokking 微服务设计模式
- 系统设计入门
- AWS 博客
- Microsoft 的架构模式
- 马丁·福勒
- PagerDuty 资源
- VMWare 博客
所有图表都是使用 Excalidraw 制作的,可在此处获得。
About
