whisper.cpp - OpenAI 的 Whisper 模型在 C/C++ 中的端口
耳语.cpp
![]()

OpenAI的Whisper自动语音识别(ASR)模型的高性能推理:
- 没有依赖关系的普通 C/C++ 实现
- Apple 芯片一等公民 - 通过 Arm Neon 和 Accelerate 框架进行优化
- 对 x86 架构的 AVX 内部支持
- VSX 对 POWER 架构的内部支持
- 混合F16 / F32精度
- 低内存使用率(闪存注意)
- 运行时零内存分配
- 在 CPU 上运行
- C 型接口
支持的平台:
- [x] Mac OS(Intel and Arm)
- [x] 苹果
- [x] 安卓
- [x] Linux / FreeBSD
- [x] 网站组装
- [x] Windows (MSVC 和 MinGW)]
- [x] 树莓派
模型的整个实现包含在 2 个源文件中:
拥有如此轻量级的模型实现可以轻松地将其集成到不同的平台和应用程序中。例如,这是在iPhone 13设备上运行该模型的视频 - 完全离线,在设备上:whisper.objc
https://user-images.githubusercontent.com/1991296/197385372-962a6dea-bca1-4d50-bf96-1d8c27b98c81.mp4
你还可以轻松制作自己的离线语音助手应用程序:命令
https://user-images.githubusercontent.com/1991296/204038393-2f846eae-c255-4099-a76d-5735c25c49da.mp4
或者你甚至可以直接在浏览器中运行它:talk.wasm
实现详细信息
- 核心张量运算是用 C (ggml.h / ggml.c ) 实现的 )
- 转换器模型和高级 C 样式 API 以 C++ (whisper.h / whisper.cpp 实现。)
- 主要内容演示了示例用法.cpp
- 来自麦克风的实时音频转录示例在流中演示.cpp
- 示例文件夹中提供了各种其他示例
张量算子针对 Apple 硅 CPU 进行了大量优化。根据计算大小,将使用 Arm Neon SIMD 固有函数或 CBLAS 加速框架例程。后者对于更大的尺寸特别有效,因为加速框架利用了现代 Apple 产品中可用的专用 AMX 协处理器。
快速入门
首先,下载一个转换为ggml格式的Whisper模型。例如:
bash ./models/download-ggml-model.sh base.en现在构建主要示例并转录一个音频文件,如下所示:
# build the main example
make
# transcribe an audio file
./main -f samples/jfk.wav要快速演示,只需运行:
make base.en
$ make base.en
cc -I. -O3 -std=c11 -pthread -DGGML_USE_ACCELERATE -c ggml.c -o ggml.o
c++ -I. -I./examples -O3 -std=c++11 -pthread -c whisper.cpp -o whisper.o
c++ -I. -I./examples -O3 -std=c++11 -pthread examples/main/main.cpp whisper.o ggml.o -o main -framework Accelerate
./main -h
usage: ./main [options] file0.wav file1.wav ...
options:
-h, --help [default] show this help message and exit
-t N, --threads N [4 ] number of threads to use during computation
-p N, --processors N [1 ] number of processors to use during computation
-ot N, --offset-t N [0 ] time offset in milliseconds
-on N, --offset-n N [0 ] segment index offset
-d N, --duration N [0 ] duration of audio to process in milliseconds
-mc N, --max-context N [-1 ] maximum number of text context tokens to store
-ml N, --max-len N [0 ] maximum segment length in characters
-bo N, --best-of N [5 ] number of best candidates to keep
-bs N, --beam-size N [-1 ] beam size for beam search
-wt N, --word-thold N [0.01 ] word timestamp probability threshold
-et N, --entropy-thold N [2.40 ] entropy threshold for decoder fail
-lpt N, --logprob-thold N [-1.00 ] log probability threshold for decoder fail
-su, --speed-up [false ] speed up audio by x2 (reduced accuracy)
-tr, --translate [false ] translate from source language to english
-di, --diarize [false ] stereo audio diarization
-nf, --no-fallback [false ] do not use temperature fallback while decoding
-otxt, --output-txt [false ] output result in a text file
-ovtt, --output-vtt [false ] output result in a vtt file
-osrt, --output-srt [false ] output result in a srt file
-owts, --output-words [false ] output script for generating karaoke video
-ocsv, --output-csv [false ] output result in a CSV file
-of FNAME, --output-file FNAME [ ] output file path (without file extension)
-ps, --print-special [false ] print special tokens
-pc, --print-colors [false ] print colors
-pp, --print-progress [false ] print progress
-nt, --no-timestamps [true ] do not print timestamps
-l LANG, --language LANG [en ] spoken language ('auto' for auto-detect)
--prompt PROMPT [ ] initial prompt
-m FNAME, --model FNAME [models/ggml-base.en.bin] model path
-f FNAME, --file FNAME [ ] input WAV file path
bash ./models/download-ggml-model.sh base.en
Downloading ggml model base.en ...
ggml-base.en.bin 100%[========================>] 141.11M 6.34MB/s in 24s
Done! Model 'base.en' saved in 'models/ggml-base.en.bin'
You can now use it like this:
$ ./main -m models/ggml-base.en.bin -f samples/jfk.wav
===============================================
Running base.en on all samples in ./samples ...
===============================================
----------------------------------------------
[+] Running base.en on samples/jfk.wav ... (run 'ffplay samples/jfk.wav' to listen)
----------------------------------------------
whisper_init_from_file: loading model from 'models/ggml-base.en.bin'
whisper_model_load: loading model
whisper_model_load: n_vocab = 51864
whisper_model_load: n_audio_ctx = 1500
whisper_model_load: n_audio_state = 512
whisper_model_load: n_audio_head = 8
whisper_model_load: n_audio_layer = 6
whisper_model_load: n_text_ctx = 448
whisper_model_load: n_text_state = 512
whisper_model_load: n_text_head = 8
whisper_model_load: n_text_layer = 6
whisper_model_load: n_mels = 80
whisper_model_load: f16 = 1
whisper_model_load: type = 2
whisper_model_load: mem required = 215.00 MB (+ 6.00 MB per decoder)
whisper_model_load: kv self size = 5.25 MB
whisper_model_load: kv cross size = 17.58 MB
whisper_model_load: adding 1607 extra tokens
whisper_model_load: model ctx = 140.60 MB
whisper_model_load: model size = 140.54 MB
system_info: n_threads = 4 / 10 | AVX = 0 | AVX2 = 0 | AVX512 = 0 | FMA = 0 | NEON = 1 | ARM_FMA = 1 | F16C = 0 | FP16_VA = 1 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 0 | VSX = 0 |
main: processing 'samples/jfk.wav' (176000 samples, 11.0 sec), 4 threads, 1 processors, lang = en, task = transcribe, timestamps = 1 ...
[00:00:00.000 --> 00:00:11.000] And so my fellow Americans, ask not what your country can do for you, ask what you can do for your country.
whisper_print_timings: fallbacks = 0 p / 0 h
whisper_print_timings: load time = 113.81 ms
whisper_print_timings: mel time = 15.40 ms
whisper_print_timings: sample time = 11.58 ms / 27 runs ( 0.43 ms per run)
whisper_print_timings: encode time = 266.60 ms / 1 runs ( 266.60 ms per run)
whisper_print_timings: decode time = 66.11 ms / 27 runs ( 2.45 ms per run)
whisper_print_timings: total time = 476.31 ms该命令下载转换为自定义格式的模型,并对文件夹中的所有样本运行推理。
base.en
ggml
.wav
samples
有关详细的使用说明,请运行:
./main -h
请注意,主要示例目前仅使用 16 位 WAV 文件运行,因此请确保在运行该工具之前转换输入。例如,你可以像这样使用:
ffmpeg
ffmpeg -i input.mp3 -ar 16000 -ac 1 -c:a pcm_s16le output.wav更多音频样本
如果你想播放一些额外的音频样本,只需运行:
make samples
这将从维基百科下载更多音频文件,并通过 .
ffmpeg
你可以下载并运行其他模型,如下所示:
make tiny.en make tiny make base.en make base make small.en make small make medium.en make medium make large-v1 make large
内存使用情况
| 型 | 磁盘 | 记忆 | 沙 |
|---|---|---|---|
| 小 | 75兆字节 | ~125 兆字节 | bd577a113a864445d4c299885e0cb97d4ba92b5f |
| 基础 | 142兆字节 | ~210 兆字节 | 465707469ff3a37a2b9b8d8f89f2f99de7299dac |
| 小 | 466兆字节 | ~600 MB | 55356645c2b361a969dfd0ef2c5a50d530afd8d5 |
| 中等 | 1.5 千兆字节 | ~1.7 千兆字节 | fd9727b6e1217c2f614f9b698455c4ffd82463b4 |
| 大 | 2.9 千兆字节 | ~3.3 GB | 0f4c8e34f21cf1a914c59d8b3ce882345ad349d6 |
局限性
- 仅推理
- 尚不支持 GPU
另一个例子
以下是另一个使用模型在MacBook M1 Pro上在大约半分钟内转录3:24分钟语音的示例:
medium.en
展开以查看结果
$ ./main -m models/ggml-medium.en.bin -f samples/gb1.wav -t 8
whisper_init_from_file: loading model from 'models/ggml-medium.en.bin'
whisper_model_load: loading model
whisper_model_load: n_vocab = 51864
whisper_model_load: n_audio_ctx = 1500
whisper_model_load: n_audio_state = 1024
whisper_model_load: n_audio_head = 16
whisper_model_load: n_audio_layer = 24
whisper_model_load: n_text_ctx = 448
whisper_model_load: n_text_state = 1024
whisper_model_load: n_text_head = 16
whisper_model_load: n_text_layer = 24
whisper_model_load: n_mels = 80
whisper_model_load: f16 = 1
whisper_model_load: type = 4
whisper_model_load: mem required = 1720.00 MB (+ 43.00 MB per decoder)
whisper_model_load: kv self size = 42.00 MB
whisper_model_load: kv cross size = 140.62 MB
whisper_model_load: adding 1607 extra tokens
whisper_model_load: model ctx = 1462.35 MB
whisper_model_load: model size = 1462.12 MB
system_info: n_threads = 8 / 10 | AVX = 0 | AVX2 = 0 | AVX512 = 0 | FMA = 0 | NEON = 1 | ARM_FMA = 1 | F16C = 0 | FP16_VA = 1 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 0 | VSX = 0 |
main: processing 'samples/gb1.wav' (3179750 samples, 198.7 sec), 8 threads, 1 processors, lang = en, task = transcribe, timestamps = 1 ...
[00:00:00.000 --> 00:00:08.000] My fellow Americans, this day has brought terrible news and great sadness to our country.
[00:00:08.000 --> 00:00:17.000] At nine o'clock this morning, Mission Control in Houston lost contact with our Space Shuttle Columbia.
[00:00:17.000 --> 00:00:23.000] A short time later, debris was seen falling from the skies above Texas.
[00:00:23.000 --> 00:00:29.000] The Columbia's lost. There are no survivors.
[00:00:29.000 --> 00:00:32.000] On board was a crew of seven.
[00:00:32.000 --> 00:00:39.000] Colonel Rick Husband, Lieutenant Colonel Michael Anderson, Commander Laurel Clark,
[00:00:39.000 --> 00:00:48.000] Captain David Brown, Commander William McCool, Dr. Kultna Shavla, and Ilan Ramon,
[00:00:48.000 --> 00:00:52.000] a colonel in the Israeli Air Force.
[00:00:52.000 --> 00:00:58.000] These men and women assumed great risk in the service to all humanity.
[00:00:58.000 --> 00:01:03.000] In an age when space flight has come to seem almost routine,
[00:01:03.000 --> 00:01:07.000] it is easy to overlook the dangers of travel by rocket
[00:01:07.000 --> 00:01:12.000] and the difficulties of navigating the fierce outer atmosphere of the Earth.
[00:01:12.000 --> 00:01:18.000] These astronauts knew the dangers, and they faced them willingly,
[00:01:18.000 --> 00:01:23.000] knowing they had a high and noble purpose in life.
[00:01:23.000 --> 00:01:31.000] Because of their courage and daring and idealism, we will miss them all the more.
[00:01:31.000 --> 00:01:36.000] All Americans today are thinking as well of the families of these men and women
[00:01:36.000 --> 00:01:40.000] who have been given this sudden shock and grief.
[00:01:40.000 --> 00:01:45.000] You're not alone. Our entire nation grieves with you,
[00:01:45.000 --> 00:01:52.000] and those you love will always have the respect and gratitude of this country.
[00:01:52.000 --> 00:01:56.000] The cause in which they died will continue.
[00:01:56.000 --> 00:02:04.000] Mankind is led into the darkness beyond our world by the inspiration of discovery
[00:02:04.000 --> 00:02:11.000] and the longing to understand. Our journey into space will go on.
[00:02:11.000 --> 00:02:16.000] In the skies today, we saw destruction and tragedy.
[00:02:16.000 --> 00:02:22.000] Yet farther than we can see, there is comfort and hope.
[00:02:22.000 --> 00:02:29.000] In the words of the prophet Isaiah, "Lift your eyes and look to the heavens
[00:02:29.000 --> 00:02:35.000] who created all these. He who brings out the starry hosts one by one
[00:02:35.000 --> 00:02:39.000] and calls them each by name."
[00:02:39.000 --> 00:02:46.000] Because of His great power and mighty strength, not one of them is missing.
[00:02:46.000 --> 00:02:55.000] The same Creator who names the stars also knows the names of the seven souls we mourn today.
[00:02:55.000 --> 00:03:01.000] The crew of the shuttle Columbia did not return safely to earth,
[00:03:01.000 --> 00:03:05.000] yet we can pray that all are safely home.
[00:03:05.000 --> 00:03:13.000] May God bless the grieving families, and may God continue to bless America.
[00:03:13.000 --> 00:03:19.000] [Silence]
whisper_print_timings: fallbacks = 1 p / 0 h
whisper_print_timings: load time = 569.03 ms
whisper_print_timings: mel time = 146.85 ms
whisper_print_timings: sample time = 238.66 ms / 553 runs ( 0.43 ms per run)
whisper_print_timings: encode time = 18665.10 ms / 9 runs ( 2073.90 ms per run)
whisper_print_timings: decode time = 13090.93 ms / 549 runs ( 23.85 ms per run)
whisper_print_timings: total time = 32733.52 ms实时音频输入示例
这是对来自麦克风的音频执行实时推理的简单示例。流工具每半秒对音频进行一次采样,并连续运行转录。更多信息可在问题 #10 中找到。
make stream
./stream -m ./models/ggml-base.en.bin -t 8 --step 500 --length 5000https://user-images.githubusercontent.com/1991296/194935793-76afede7-cfa8-48d8-a80f-28ba83be7d09.mp4
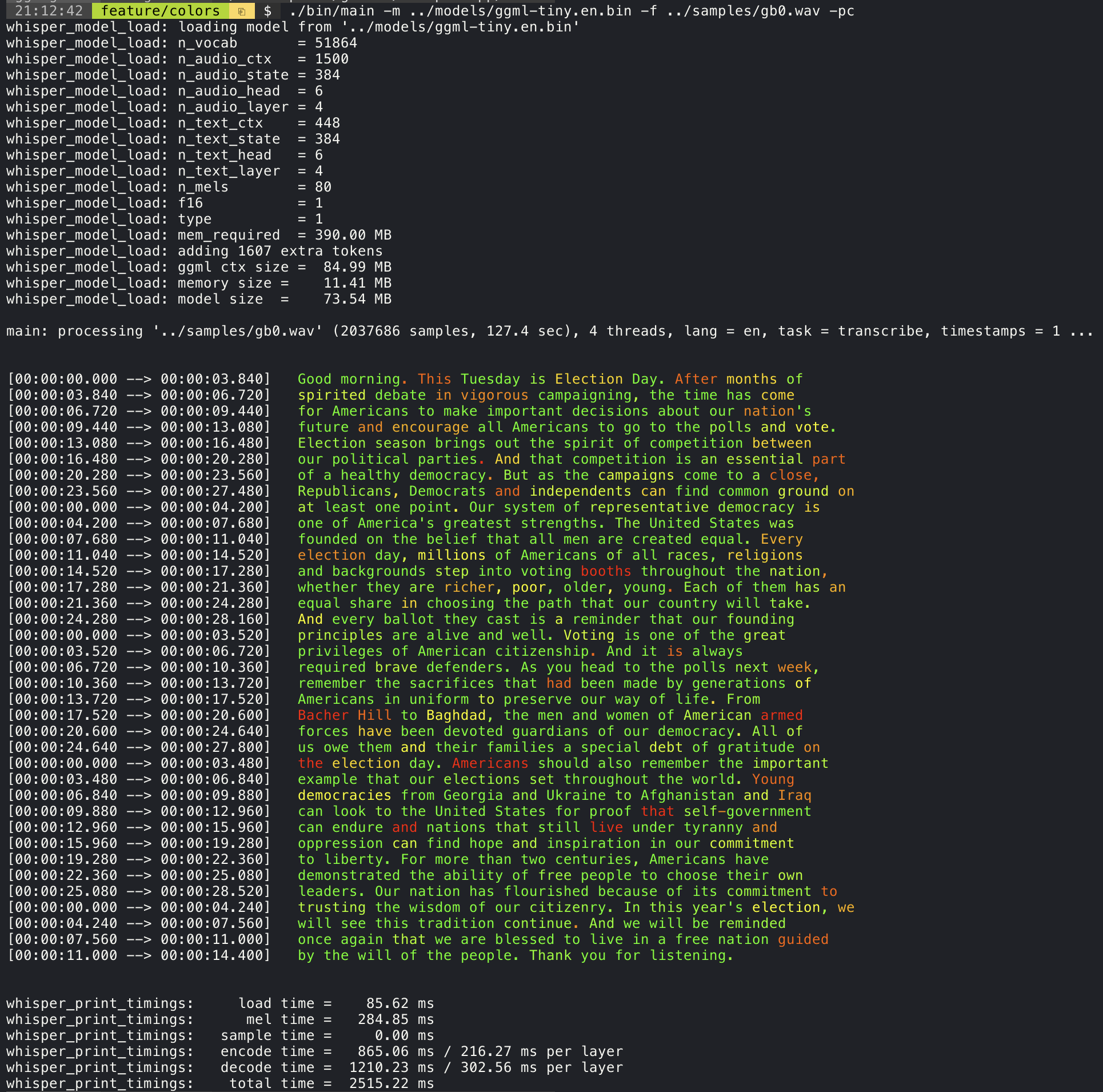
置信度颜色编码
添加参数将使用实验性颜色编码策略打印转录文本,以突出显示置信度高或低的单词:
--print-colors
控制生成的文本段的长度(实验性)
例如,要将行长度限制为最多 16 个字符,只需添加:
-ml 16
./main -m ./models/ggml-base.en.bin -f ./samples/jfk.wav -ml 16
whisper_model_load: loading model from './models/ggml-base.en.bin'
...
system_info: n_threads = 4 / 10 | AVX2 = 0 | AVX512 = 0 | NEON = 1 | FP16_VA = 1 | WASM_SIMD = 0 | BLAS = 1 |
main: processing './samples/jfk.wav' (176000 samples, 11.0 sec), 4 threads, 1 processors, lang = en, task = transcribe, timestamps = 1 ...
[00:00:00.000 --> 00:00:00.850] And so my
[00:00:00.850 --> 00:00:01.590] fellow
[00:00:01.590 --> 00:00:04.140] Americans, ask
[00:00:04.140 --> 00:00:05.660] not what your
[00:00:05.660 --> 00:00:06.840] country can do
[00:00:06.840 --> 00:00:08.430] for you, ask
[00:00:08.430 --> 00:00:09.440] what you can do
[00:00:09.440 --> 00:00:10.020] for your
[00:00:10.020 --> 00:00:11.000] country.字级时间戳
该参数可用于获取字级时间戳。只需使用 :
--max-len
-ml 1
./main -m ./models/ggml-base.en.bin -f ./samples/jfk.wav -ml 1
whisper_model_load: loading model from './models/ggml-base.en.bin'
...
system_info: n_threads = 4 / 10 | AVX2 = 0 | AVX512 = 0 | NEON = 1 | FP16_VA = 1 | WASM_SIMD = 0 | BLAS = 1 |
main: processing './samples/jfk.wav' (176000 samples, 11.0 sec), 4 threads, 1 processors, lang = en, task = transcribe, timestamps = 1 ...
[00:00:00.000 --> 00:00:00.320]
[00:00:00.320 --> 00:00:00.370] And
[00:00:00.370 --> 00:00:00.690] so
[00:00:00.690 --> 00:00:00.850] my
[00:00:00.850 --> 00:00:01.590] fellow
[00:00:01.590 --> 00:00:02.850] Americans
[00:00:02.850 --> 00:00:03.300] ,
[00:00:03.300 --> 00:00:04.140] ask
[00:00:04.140 --> 00:00:04.990] not
[00:00:04.990 --> 00:00:05.410] what
[00:00:05.410 --> 00:00:05.660] your
[00:00:05.660 --> 00:00:06.260] country
[00:00:06.260 --> 00:00:06.600] can
[00:00:06.600 --> 00:00:06.840] do
[00:00:06.840 --> 00:00:07.010] for
[00:00:07.010 --> 00:00:08.170] you
[00:00:08.170 --> 00:00:08.190] ,
[00:00:08.190 --> 00:00:08.430] ask
[00:00:08.430 --> 00:00:08.910] what
[00:00:08.910 --> 00:00:09.040] you
[00:00:09.040 --> 00:00:09.320] can
[00:00:09.320 --> 00:00:09.440] do
[00:00:09.440 --> 00:00:09.760] for
[00:00:09.760 --> 00:00:10.020] your
[00:00:10.020 --> 00:00:10.510] country
[00:00:10.510 --> 00:00:11.000] .卡拉OK风格的电影生成(实验性)
主要示例提供对卡拉 OK 样式电影输出的支持,其中突出显示当前发音的单词。使用该参数并运行生成的 bash 脚本。这需要已安装。
-wts
ffmpeg
以下是一些“典型”示例:
./main -m ./models/ggml-base.en.bin -f ./samples/jfk.wav -owts
source ./samples/jfk.wav.wts
ffplay ./samples/jfk.wav.mp4https://user-images.githubusercontent.com/1991296/199337465-dbee4b5e-9aeb-48a3-b1c6-323ac4db5b2c.mp4
./main -m ./models/ggml-base.en.bin -f ./samples/mm0.wav -owts
source ./samples/mm0.wav.wts
ffplay ./samples/mm0.wav.mp4https://user-images.githubusercontent.com/1991296/199337504-cc8fd233-0cb7-4920-95f9-4227de3570aa.mp4
./main -m ./models/ggml-base.en.bin -f ./samples/gb0.wav -owts
source ./samples/gb0.wav.wts
ffplay ./samples/gb0.wav.mp4https://user-images.githubusercontent.com/1991296/199337538-b7b0c7a3-2753-4a88-a0cd-f28a317987ba.mp4
不同型号的视频比较
使用额外/wts.sh 脚本生成以下格式的视频:
./extra/bench-wts.sh samples/jfk.wav
ffplay ./samples/jfk.wav.all.mp4https://user-images.githubusercontent.com/1991296/223206245-2d36d903-cf8e-4f09-8c3b-eb9f9c39d6fc.mp4
基准
为了客观比较不同系统配置的推理性能,请使用工作台工具。该工具只需运行模型的编码器部分并打印执行它所花费的时间。结果总结在以下 Github 问题中:
gggml 格式
原始模型将转换为自定义二进制格式。这允许将所需的所有内容打包到一个文件中:
- 模型参数
- 梅尔过滤器
- 词汇
- 权重
你可以使用 models/download-ggml-model.sh 脚本下载转换后的模型,也可以从此处手动下载:
有关更多详细信息,请参阅转换脚本模型/转换 pt-to-ggml.py 或模型中的自述文件。
绑定
- [X] 铁锈: tazz4843/耳语-rs |#310
- [X] Javascript: bindings/javascript |#309
- [X] 转到:绑定/转到 |#312
- [X] 拼音:绑定/拼音 |#507
- [X] Objective-C / Swift: ggerganov/whisper.spm |#313
- [X] .NET: |#422
- [X] 蟒蛇: |#9
- stlukey/whispercpp.py (Cython)
- aarnphm/whispercpp (Pybind11)
例子
在 examples 文件夹中,有将库用于不同项目的各种示例。其中一些示例甚至被移植到使用 WebAssembly 在浏览器中运行。看看他们!
| 例 | 蹼 | 描述 |
|---|---|---|
| 主要 | 耳语 | 使用耳语翻译和转录音频的工具 |
| 板凳 | 板凳.wasm | 在你的机器上对 Whisper 的性能进行基准测试 |
| 流 | stream.wasm | 实时转录原始麦克风捕获 |
| 命令 | 命令.wasm | 用于从麦克风接收语音命令的基本语音助手示例 |
| 说话 | 谈话.瓦斯姆 | 与 GPT-2 机器人交谈 |
| 耳语 | 使用耳语的iOS移动应用程序.cpp | |
| 耳语.斯威夫特 | SwiftUI iOS / macOS应用程序使用耳语.cpp | |
| 耳语安卓 | 使用耳语的安卓移动应用程序.cpp | |
| 耳语.nvim | Neovim 的语音转文本插件 | |
| generate-karaoke.sh | 帮助脚本,可轻松生成原始音频捕获的卡拉OK视频 | |
| livestream.sh | 直播音频转录 | |
| yt-wsp.sh | 下载+转录和/或翻译任何视频点播(原文) |
讨论
如果你对这个项目有任何反馈,请随时使用“讨论”部分并打开一个新主题。你可以使用“显示并告知”类别来共享你自己的使用 .如果你有问题,请务必查看常见问题 (#126) 讨论。
whisper.cpp
